







Zookeeper: 文件系统 + 通知机制。
Zookeeper是一个开源分布式的,为分布式应用提供协调服务的Apache项目。从遍程设计角度来讲,是一个基于观察者模式
设计的分布式服务管理。它是负责存储和管理大家关系的数据,然后根据观察者的注册,一旦这些数据的状态发生变化,Zookeeper
就将负责通知已经再Zookeeper上注册的那些观察者都做出相应的反应。
安装要求:
1、安装JDK
2、安装Zookeeper
安装:
1、 java -version 返现虚拟机已有安装。
2、
a.下载wget命令下载或者下载后利用winSCP传上去都是可以的。
b.如下步骤完成安装配置,详细不累述。
tar -zxvf zookeeper-3.4.13.tar.gz
mvn zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/tmp/zookeeper/data
dataLogDir=/tmp/zookeeper/log
启动结果:(上面配置文件中的路径一定要配对,,如果报错查看logs文件)
脚本说明:
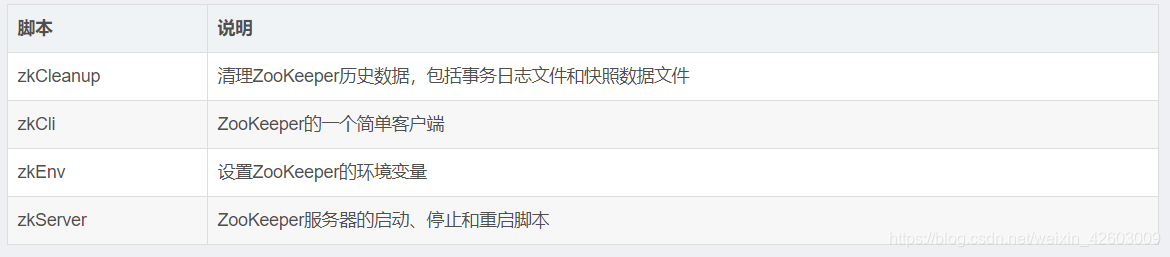
root@ubuntu:/usr/local/zookeeper/bin# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@ubuntu:/usr/local/zookeeper/bin# ./zkCli.sh -server
配置参数举例解析(详见官方文档):
tickTime:ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。
服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳。
例如,session的最小超时时间是2*tickTime。单位毫秒。
initLimit=10: LF初始通信时限。集群中的Follower跟随者与Leader
领导者服务器之间初始连接时能容忍的最多心跳数,用它来限定集群中的Zookeeper服务器连接到leader的时限。
clientPort:客户端连接server的端口,即对外服务端口,一般设置为2181吧。
dataDir:存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。
dataLogDir:事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。
选举机制:
1、半数机制:集群中半数以上的机器存活,集群可用。所以非常适合奇数台服务器。
2、Zookeeper中没有指定主从,但是在工作的时候有,leader是通过内部的选举机制临时产生的。
选举规则是满足第一个半数以上就是leader。启动后给自己投票,不是就给比它大的投票,直到找到leader。其他未follower
Zookeeper的数据模型和linux文件系统是很类似的,就是一个文件树结构。
结构分为以下四种:
1.持久节点 (PERSISTENT)
默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在 。
2.持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号:
3.临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
4.临时顺序节点(EPHEMERAL_SEQUENTIAL)
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与Zookeeper断开连接后,临时节点会被删除。
至少三个节点:
比如分别在hadoop102、hadoop103、hadoop104三个节点上部署Zookeeper。
hadoop102安装好后,同时同步到hadoop103、hadoop104。
1、配置服务器编号。创建zkData/myid的文件。编辑vim myid 2。同步到hadoop103、hadoop104。在分别修改为3、4。
2、配置zoo.cfg。配置数据存储路径opt/module/zoo…/zkData。
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
server.A=B:C:D。B是这个服务器的IP地址、C是这个服务器与集群中Leader服务器交换信息的端口、D备用
配置完同步zoo.cfg
Zookeeper分布式分布式锁的原理:Zookeeper分布式锁恰恰应用了临时顺序节点。
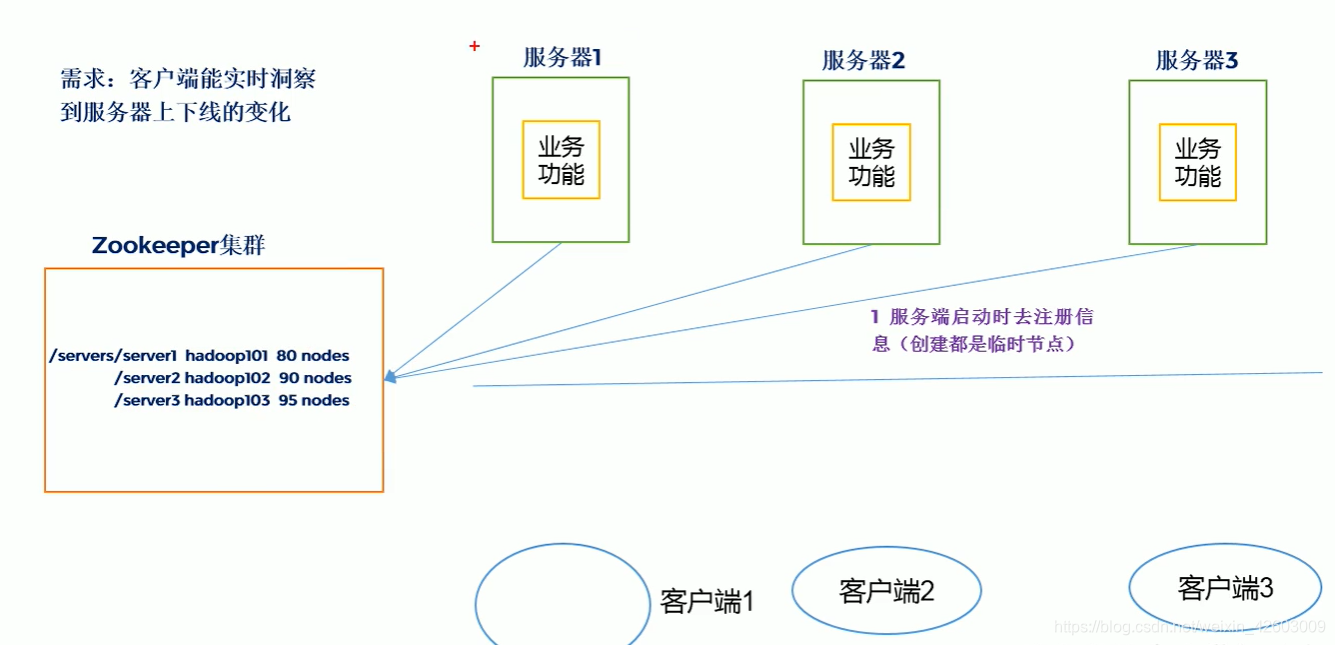
加锁:
1、首先,在Zookeeper当中创建一个持久节点server。当第一个客户端想要获得锁时,需要在server这个节点下面创建一个临时顺序节点 Lock1。
2、之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
3、这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
4、Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
5、于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。
6、这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。
7、Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。
8、于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列,很像是Java当中ReentrantLock所依赖的AQS(AbstractQueuedSynchronizer)。
解锁:
1、当任务完成时,Client1会显示调用删除节点Lock1的指令。
2、由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。
如果是最小,则Client2顺理成章获得了锁。
3、如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知。
直到结束。
代码三板斧:
1:连接zooleeper
2:注册监听
3:业务逻辑
Zookeeper分布式锁对比redis实现分布式锁:
分布式锁实现方式不论哪一种都是保证单线程操作。同时利用Jmeter模拟高并发场景(这里不累述)。
1、利用redis命令setnx,保证单线程。
setnx命令的解释:


在这里插入图片描述
来看看Springboot中那个方式是实现了上面这条命令:
redisTemplate.opsForValue().setIfAbsent()
public Boolean setIfAbsent(K key, V value) {
byte[] rawKey = this.rawKey(key);
byte[] rawValue = this.rawValue(value);
return (Boolean)this.execute((connection) -> {
return connection.setNX(rawKey, rawValue);
}, true);
}
所以我们实现分布式锁,利用这条语句即可。或者你也利用
this.execute((connection) -> {
return connection.setNX(rawKey, rawValue);
}, true);
来实现分布式锁。
先看看第一种:
package com.stu.demo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class RedisApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
void contextLoads() {
// 在redis中保存product字段、value=100,保存商品用于抢购。
// 同一个JVM中加锁保证单线就可以了。但是现在的场景是分布式系统,多个JVM中,前面的办法就无法保证了。
Boolean result = redisTemplate.opsForValue().setIfAbsent("productLock", "shangping");
if (!result) { // false,则存在锁
System.out.println("存在锁,不允许做操作");
return;
} else { // true,不存在锁允许操作
int product = Integer.parseInt(redisTemplate.opsForValue().get("product"));
if (product > 0) {
product--;
redisTemplate.opsForValue().set("product", "" + product);
return;
} else {
System.out.println("已售罄");
return;
}
}
}
}
上面这样写会存在一个很大的问题,死锁。需要解决如下两个问题。
1、如果进来就已经存在锁。那么你将死锁,导致商品卖不出。
2、进程进来执行一半,服务器宕机,导致产生的死锁。
解决方式:进来无论有没有都释放。
package com.stu.demo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.time.Duration;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class RedisApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
void contextLoads() {
// 防止宕机产生死锁,加有效时间
Boolean result = redisTemplate.opsForValue().setIfAbsent("productLock", "shangping",60, TimeUnit.SECONDS);
try {
if (!result) { // false,则存在锁
System.out.println("存在锁,不允许做操作");
return;
} else { // true,不存在锁允许操作
int product = Integer.parseInt(redisTemplate.opsForValue().get("product"));
if (product > 0) {
product--;
redisTemplate.opsForValue().set("product", "" + product);
return;
} else {
System.out.println("已售罄");
return;
}
}
} finally {
// 解锁:不管有没有卖出成功,或者抛出异常
redisTemplate.delete("productLock");
}
}
}
第二种方式:
想了想还是不写了,有点脱裤子放屁,人家方法都写好了。你还要自己去折腾。放在这里当一种思路吧。copy一份网上的放在这里:
public boolean lock(String lockKey, long lockExpireMils) {
return (Boolean) redisTemplate.execute((RedisCallback) connection -> {
long nowTime = System.currentTimeMillis();
Boolean acquire = connection.setNX(lockKey.getBytes(), String.valueOf(nowTime + lockExpireMils + 1).getBytes());
if (acquire) {
return Boolean.TRUE;
} else {
byte[] value = connection.get(lockKey.getBytes());
if (Objects.nonNull(value) && value.length > 0) {
long oldTime = Long.parseLong(new String(value));
if (oldTime < nowTime) {
//connection.getSet:返回这个key的旧值并设置新值。
byte[] oldValue = connection.getSet(lockKey.getBytes(), String.valueOf(nowTime + lockExpireMils + 1).getBytes());
//当key不存时会返回空,表示key不存在或者已在管道中使用
return oldValue == null ? false : Long.parseLong(new String(oldValue)) < nowTime;
}
}
}
return Boolean.FALSE;
});
}
redis实现分布式锁的缺点:
1、每次需要自己去尝试,比较消耗性能。
2、redis锁模型就决定了它的的健壮性不够。
2、利用zookeeper文件系统特性create创建文件,已有不能创建,保证单线程操作。
1、利用命令的简单实现。
zhouyi@ubuntu:/usr/local/apache-zookeeper-3.5.5/bin$ ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2、使用curator实现分布式锁。
pom.xml文件:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
</dependency>
<!-- zookeeper和curator版本一定要合的上 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
import java.util.concurrent.TimeUnit;
import lombok.Cleanup;
import lombok.SneakyThrows;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.data.Stat;
public class ZkLock {
@SneakyThrows
public static void main(String[] args) {
final String connectString = "localhost:2181,localhost:2182,localhost:2183";
// 重试策略,初始化每次重试之间需要等待的时间,基准等待时间为1秒。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
// 使用默认的会话时间(60秒)和连接超时时间(15秒)来创建 Zookeeper 客户端
@Cleanup CuratorFramework client = CuratorFrameworkFactory.builder().
connectString(connectString).
connectionTimeoutMs(15 * 1000).
sessionTimeoutMs(60 * 100).
retryPolicy(retryPolicy).
build();
// 启动客户端
client.start();
final String lockNode = "/lock_node";
InterProcessMutex lock = new InterProcessMutex(client, lockNode);
try {
// 1. Acquire the mutex - blocking until it's available.
lock.acquire();
// OR
// 2. Acquire the mutex - blocks until it's available or the given time expires.
if (lock.acquire(60, TimeUnit.MINUTES)) {
Stat stat = client.checkExists().forPath(lockNode);
if (null != stat){
// Dot the transaction
}
}
} finally {
if (lock.isAcquiredInThisProcess()) {
lock.release();
}
}
}
}














 1471
1471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









