







概要
数据库优化维度有4个:
硬件升级、系统配置、表结构设计、SQL语句及索引。
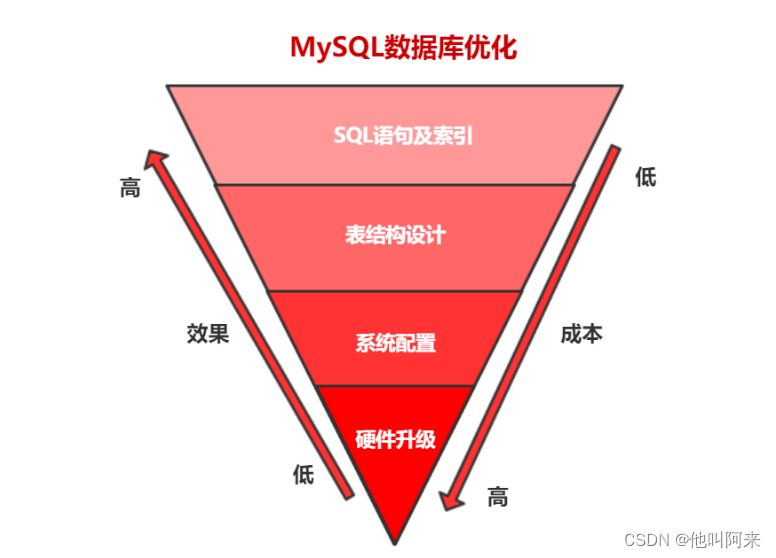
优化选择:
优化成本:硬件升级>系统配置>表结构设计>SQL语句及索引。
优化效果:硬件升级<系统配置<表结构设计<SQL语句及索引。
系统配置优化
1、保证从内存中读取数据
InnoDB存储引擎在处理客户端的请求时, 当需要访问某个⻚的数据时, 就会把完整的⻚的数据全部加载到内存中, 也就是说即使我们只需要访问⼀个⻚的⼀条记录, 那也需要先把整个⻚的数据加载到内存中。
向系统申请的连续内存空间叫做Buffer Pool 默认大小是128M。可以通过参数innodb_buffer_pool_size来配置。
该参数配置得越大,InnoDB 表性能就越好。但是,设置得过大也不好,可能会导致系统发生 SWAP 页交换。所以我们需要在 IBP 大小和其它系统服务所需内存大小之间取得平衡。MySQL 推荐配置 IBP 的大小为服务器物理内存的 80%。
mysql> show global status like 'innodb_buffer_pool_pages_%';
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| Innodb_buffer_pool_pages_data | 8190 |
| Innodb_buffer_pool_pages_dirty | 0 |
| Innodb_buffer_pool_pages_flushed | 12646 |
| Innodb_buffer_pool_pages_free | 0 | 0 表示已经被用光
| Innodb_buffer_pool_pages_misc | 1 |
| Innodb_buffer_pool_pages_total | 8191 |
+----------------------------------+-------+
通过修改my.cnf来配置,如
innodb_buffer_pool_size = 750M
如果是专用的MySQL Server可以禁用SWAP。
2、数据预热
默认情况,仅仅有某条数据被读取一次,才会缓存在 innodb_buffer_pool。所以,数据库刚刚启动,须要进行数据预热,将磁盘上的全部数据缓存到内存中。数据预热能够提高读取速度。
预热脚本
SELECT DISTINCT CONCAT('SELECT ', ndxcollist, ' FROM ', db, '.', tb,
' ORDER BY ', ndxcollist, ';') SelectQueryToLoadCache
FROM (
SELECT engine,
table_schema db,
table_name tb,
index_name,
GROUP_CONCAT(column_name ORDER BY seq_in_index)
ndxcollist
FROM (
SELECT B.engine,
A.table_schema,
A.table_name,
A.index_name,
A.column_name,
A.seq_in_index
FROM information_schema.statistics A
INNER JOIN
(
SELECT engine, table_schema, table_name
FROM information_schema.tables
WHERE engine = 'InnoDB'
) B USING (table_schema, table_name)
WHERE B.table_schema NOT IN ('information_schema', 'mysql')
ORDER BY table_schema, table_name, index_name, seq_in_index
) A
GROUP BY table_schema, table_name, index_name
) AA
ORDER BY db, tb;
需要数据预热时执行命令(loadtomem.sql是上面保存下来的脚本):
mysql -uroot < /root/loadtomem.sql > /dev/null 2>&1
3、降低磁盘的写入次数
- 增大redolog,减少落盘次数
innodb_log_file_size设置为0.25 * innodb_buffer_pool_size - 通用查询日志、 慢查询日志可以不打开,binlog日志打开
生产中不开通用查询日志,遇到性能问题开慢查询日志 - 写redolog策略 innodb_flush_log_at_trx_commit设置为0或2
如果不涉及非常高的安全性 (金融系统),或者基础架构足够安全,或者事务都非常小,都能够用 0或者 2 来减少磁盘操作。
4、提高磁盘读写性能
使用SSD或者内存磁盘
表结构设计优化
1、主键优化
每张表建议都要有一个主键(主键索引),而且主键类型最好是int类型,建议自增主键。
2、字段设计
数据库中的表越小,在它上面执行的查询也就会越快。
因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
对于比较小的数字可以使用tinyint类型
3、设计冗余字段
为减少关联查询,创建合理的冗余字段(创建冗余字段还需要注意数据一致性问题)
4、拆表
对于字段太多的大表,考虑拆表(比如一个表有100多个字段)。
对于表中经常不被使用的字段或者存储数据比较多的字段,考虑拆表。
SQL语句及索引优化
1、使用EXPLAIN查看索引使用情况
使用【慢查询日志】功能,去获取所有查询时间比较长的SQL语句 3秒-5秒
使用explain查看有问题的SQL的执行计划,重点查看索引使用情况
各字段解释参考:MySQL索引设计与EXPLAIN
2、SQL语句中IN包含的值不应过多
MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序
的。但是如果数值较多,产生的消耗也是比较大的。
3、SELECT语句务必指定字段名称
SELECT * 增加很多不必要的消耗(CPU、IO、内存、网络带宽);减少了使用覆盖索引的可能性;所以要求直接在select后面接上字段名。
4、只需要一条数据时,使用limit 1
limit 是可以停止全表扫描的
5、排序字段加索引
6、区分in 和exists、not in 和 not exists
区分in和exists主要是造成了驱动顺序的改变,如果是exists,那么外层表为驱动表,先被访问;如果是in,那么先执行子查询。所以IN适合于外表大而内表小的情况;exists适合于外表小而内表大的情况。
关于not in 和not exists,推荐使用not exists,效率更高。
not in的优化
原SQL:
select colname ... from A表 where a.id not in (select b.id from B表);
优化后SQL:
select colname ... from A表 left join B表 on a.id = b.id where b.id is null;
7、使用合理的分页方式提高分页效率
分页使用limit m,n,尽量让m的值小;
利用主键定位,可以减少m的值
或者先分页查询出主键值,在通过主键查询要查询的其他列
8、不建议使用%前缀模糊查询
例如LIKE"%name"或者LIKE"%name%",这种查询会导致索引失效而进行全表扫描。但是可以使用
LIKE "name%"。
9、避免在where字句中对字段进行表达式操作
select user_id,user_project from user_base where age*2=36;
中对字段进行了算术运算,会使索引失效,可以改成
select user_id,user_project from user_base where age=36/2;
10、避免隐式类型转换
where子句中出现column字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定
where中的参数类型。
11、对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段id、name、school,可以直接用id字段,也可以id、name这样的顺序,但是
name;school都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询
字段放在最前面。
12、必要时可以使用force index来强制查询走某个索引
有的时候MySQL优化器采取它认为合适的索引来检索SQL语句,但是可能它所采用的索引并不是我们想
要的。这时就可以采用force index来强制优化器使用我们制定的索引。
13、注意JOIN语句的优化
LEFT JOIN A表 则A表为驱动表,INNER JOIN MySQL会自动找出那个数据少的表作用驱动表,RIGHT JOIN B 表 则B表为驱动表。
- 利用小表驱动大表。
- 尽量使用
INNER JOIN,避免使用LEFT JOIN。 - 被驱动表的索引字段作为on的限制字段。

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









