







堆栈、堆、栈的概念
- 堆:堆可以被看成是一棵树。堆是在程序运行时,申请某个大小的存储空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
- 栈:栈是一种运算受限的线性表。仅允许在栈的一端进行插入和删除操。这一端称为栈顶,相对的,另一端称为栈底。遵循先入后出的原则。
- 堆栈:堆栈本身就是栈,只是由于现代汉语言喜欢用两个字表示一个事物,因此用了“堆栈”的说法来代替栈。
CPU中为什么要引入堆栈的机制
程序在执行程序时,相对应是PC指针的变化,PC指针永远指向下一条待执行的指令。但是PC指针不是永远都是一条一条逐一递增的,再遇到函数嵌套调用时,函数跳转时(比如遇到 if…else这样的语句时),PC指针会发生跳转。

在发生函数调用的时候,函数调用结束需要使CPU回到原来的位置,也就是使PC指针发生一个跳转,PC指针的跳转也就要给PC指针赋值,给PC指针赋的这个值也就是函数的返回地址。那CPU应该从何处获得这个返回地址呢?早期的CPU设计是设计了一个返回地址寄存器。
返回地址寄存器的作用就是为了存储函数调用时的返回地址,从而使得函数调用结束时,将此寄存器的值赋值给PC指针寄存器,完成函数的返回。但是函数调用可能会嵌套好几层,第一次调用的返回地址要进行存储,第二次调用的返回地址仍然需要进行存储,在使用C语言时,会使用到库函数,在使用库函数的过程当中,就可能发生多层的函数调用,因此会造成返回地址寄存器不够用的情况,因此也就引入了一种更加智能的机制,也就是堆栈(stack)
堆栈的特点及作用
特性
- 堆栈是一段连续的存储空间
- 堆栈按照先入后出的方式进行工作
- 只能向/从堆栈的顶部加入或取出数据
- 堆栈能够保存数据的顺序
补充: 堆栈的存储器是自下向上使用,所谓的“顶部”是数据最后放入的位置
且对于大部分的CPU而言,“顶部”指低位的存储空间
基本操作方式
压栈(PUSH):将内容加入到堆栈顶端
出栈(POP): 将堆栈顶端的内容取出
堆栈的三种作用
- C语言编译器使用堆栈来完成参数传递和返回值传递——C语言的函数调用
- 汇编程序可以使用堆栈来保存局部变量,寄存器的值
- CPU硬件使用堆栈来保存返回地址和寄存器上下文
解决函数调用返回地址存储的方法
有了堆栈这样的机制,就能很好地处理函数跳转及函数嵌套调用的问题。
在发生函数嵌套调用的时候,当发生一级函数调用的时候,就把当前的PC指针寄存器的值压入堆栈,当函数调用还没有返回时,又再次发生函数调用时,需要把第二次发生函数调用的当前的PC指针寄存器的值压入堆栈,当第二层函数调用需要返回时,只需要从栈顶取出数据即可,这个值也就是第二次函数调用时的返回地址,将其赋值给PC指针寄存器,就可以完成第二层函数的返回。而发生第一层函数返回时,只需要再次从栈中取出一个值赋值给PC指针寄存器即可,这样就能完成第一层函数的返回。
综上,就是函数调用时的全部过程,完美的运用了堆栈先入后出的机制。
局部变量与堆栈的关系
C语言中函数的参数、返回值的传递是使用栈的,C语言中的局部变量也会根据编译器在栈中占据一定量的存储空间,因此堆栈会依据C语言的使用而逐渐地消耗,局部变量存储在栈中这一点也很好地印证了局部变量有生命周期,因为当函数调用结束,函数返回。局部变量的存储空间将逐一释放,逐一弹出,不再继续使用,局部变量的值也就被释放了。
堆栈溢出
堆栈的位置
上述描述了堆栈的作用,那堆栈又在哪里呢?对于CPU来讲,CPU采用一段连续的片外存储空间来充当堆栈,而CPU又如何找到这段存储空间呢?这里引入了堆栈指针寄存器的概念,堆栈指针寄存器指定栈顶位置,也就是片外存储器用于堆栈这一段存储空间的栈顶。
堆栈溢出的原理
在介绍堆栈溢出原理之前先指出一点,堆,全局变量的存储位置就是在堆上。
而堆栈存储空间和变量空间(堆)是使用同一端存储器空间,针对于堆栈存储空间和变量空间分别具有以下特性:
- 变量空间从低地址向高地址划分(C语言编程时使用的全局变量)
- 堆栈空间从高地址向低地址增长
下图是变量空间和堆栈空间在存储器上的示意图

因此在程序运行的时候,伴随着各种函数的调用,因此堆栈空间是处于一个上下涨落的状态,堆也在上面使用内存,考虑极限情况,当全局变量定义的过多,函数嵌套的过深,可能出现的情况就是堆空间和堆栈空间产生了交集,从而导致PC指针从堆栈中取了一个值作为返回地址,但取到的值却不是返回地址,而是一个全局变量,从而造成程序跑飞。这也就是堆栈溢出的原理。
堆栈运行例子
S12MCU
例子涉及到的汇编指令:
NOP:不执行任何操作
LDS:给堆栈指针赋一个值
PSHx:把寄存器x中的数值放入堆栈中
JSR:跳到子分支
RTS:从子分支中返回
下图中是CPU的一段内存:

下图是几条待执行的指令:
指令执行的第一步

蓝色箭头指向的是上一步已经执行结束的指令。
在上一步指令执行结束之后,我们可以看到指令中涉及到的变量有了如下的变化:
SP = undefined
PC = 0x3006
A = 0X34
B = 0X56
在上述变量中,我们可以看到SP的值是未定义的,而PC指针的值是0x3006,也就是蓝色箭头指向指令的下一条,也印证了PC指针的作用是指向即将执行的指令的地址。,A 和 B是CPU的通用寄存器,保存着即将送入CPU逻辑单元的操作数。
指令执行的第二步

在执行了第二条指令后,CPU的内存空间发生了一些变化,在其最底部出现了一个红色箭头,红色箭头指向1FFFF往下一个地址,也就是2000,在看所运行的指令,我们发现此时蓝色箭头所指向的指令的意思是给堆栈指针赋值2000,因此红色箭头指向的是堆栈指针寄存器的值,也就是说红色箭头以上的内存空间是堆栈可以使用的内存空间,因此,这段指令的意思就是:完成了堆栈的初始化,指定了地址从2000开始往上所可以使用的内存空间,将其作为堆栈使用,从这条语句开始程序也就有堆栈可以使用了。
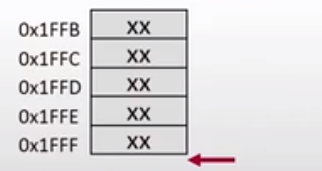
上述指令所涉及的变量发生了如下改变:
SP = 0x2000
PC = 0x3008
A = 0x34
B = 0x56
堆栈指针正如上述所分析的,SP = 0x2000,PC指针指向了指令中下一条待执行指令的地址,也就是3008,A和B寄存器的值不变。
指令执行的第三步

在执行了第三条指令之后,指令的意思是将寄存器A的值压入堆栈,指令执行结束之后,CPU的内存空间发生了一些变化,变化如下:
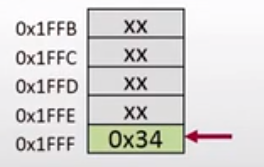
执行指令之后,相关的变量变化如下:
SP = 0x1FFF
PC = 0x3009
A = 0x34
B = 0x56
也就是说堆栈的空间被用了一个,现在可用的堆栈空间是0x1FFF以上的空间,PC指针指向的下一条待执行的指令。
指令指向的第三步

这条指令的作用是将寄存器B的值进行压栈,压栈后的CPU内存空间变为:
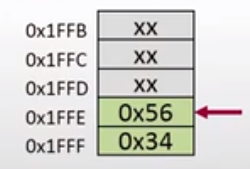
涉及到的变量变为:
SP = 0x1FFFE
PC = 0x300A
A = 0x34
B = 0x56
指令执行的第四步

这条指令的作用是跳转到子函数去执行,执行这条指令后,发生了很多变化,涉及到的相关变量发生了如下的变化:
SP = 0x1FFC
PC = 0x4050
A = 0x34
B = 0x56
SP堆栈指针变为了0x1FFC,PC指针指向了0x4050,从PC指针的值也可以清楚地看到下一条指令就要跳转到子函数执行子函数,4050也就是子函数对应的可执行指令的第一条指令。相应地,在执行了子函数,也就是发生了函数调用,那么就需要存储函数返回地址,这样才能够正确地从子函数返回。
因此,在CPU内存空间发生了如下的变化:
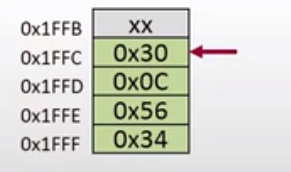
从上图可以看到0x30,和0x0C压入了堆栈,而这两个指令是由一个16位的地址拆开的两个8位的地址,将2个8位的地址合起来就是一个16位的地址,这个16位的地址就是调用子函数返回后即将执行的指令所在的地址。
总结来说,也就是在发生函数调用后,PC指针指向子函数的第一条指令所在的地址,然后堆栈会自动的压入函数返回地址,SP指针也会因为函数返回地址压入堆栈的原因,SP指针的值相应地会减少
指令执行的第五步

这条指令什么也没干,相应发生变化的是PC指针,PC指针指向了下一条待执行的指令的地址,也就是0x4052。
SP = 0x1FFC
PC = 0x4052
A = 0x34
B = 0x56
指令执行的第六步

这条指令的意思是从子函数返回,执行这条指令后,涉及到的变量发生了如下的变化:
SP = 0x1FFE
PC = 0x300C
A = 0x34
B = 0x56
从上述变化我们可以看到SP的指针相对于上一次增加了,PC指针并没有指向子函数的下一条指令,而是指向了主函数中的指令的地址,也就是刚刚自动压入堆栈的地址。相应的函数返回后,堆栈中压入的函数返回地址也自动出栈,堆栈的变化如图所示:
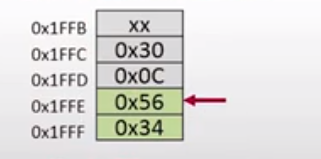
由上图所知,虽然堆栈的值自动加2,堆栈可使用的空间也增加了2,但是0x30和0x0c的值仍然存在于堆栈中,只是不被堆栈所承认。下次再往堆栈中放数据的时候就直接覆盖了原来的数据。
总结来说,也就是函数调用结束之后,将堆栈顶部的数据取出来赋值给PC指针寄。SP指针的值加2。
指令执行的第7步

指令的意思是从堆栈中弹出一个数,弹出到A寄存器,涉及到的变量变化为:
SP = 0x1FFF
PC = 0x300D
A = 0x56
B = 0X56
SP指针的值加2,PC指针的值指向下一条指令,A寄存器的值变为0x56
对应的内存空间的变化为:
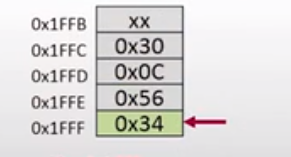
指令执行的第8步

指令的意思是从堆栈中弹出一个数赋值给B寄存器,相应的变量变化为:、
SP = 0x2000
PC = 0x300E
A = 0x56
B = 0x34
相应的内存空间的变化是:
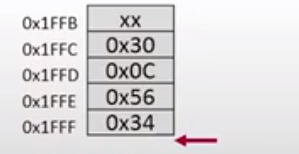
总结
回顾上述步骤,我们可以看到最终发生的变化是将A和B寄存器的值发生了一个调换,可想而知这么一个简单的操作需要执行将近10条指令,但是对于CPU来说,却是非常迅速的,CPU执行一条指令的时间是ns级的,执行一个数据交换虽然对于我们来说,指令数也不少,但是对于CPU来讲,却是电光火石之间的事。















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









