







前面一点小东西:
1.堆通常是一个可以被看做一棵树的数组对象
2·堆中某个节点的值总是不大于或不小于其父节点的值
3·堆总是一棵完全二叉树
4.堆中每次都只能删除第0个数据
其中我们将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。

4.假设当前节点为k,由图知:
父节点 = (k-1)/2
左子节点 = 2*k+1
右子节点 = 2*k+2
最后一个非叶子节点 = (数组.length-1)/2
5.关于堆的插入删除图解(https://blog.csdn.net/MoreWindows/article/details/6709644)
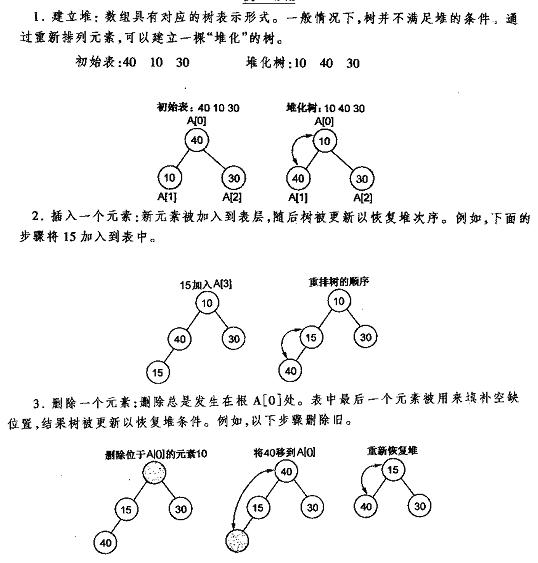
大概思路:
1.对无序的数据先建立一个堆,输出堆顶元素
2.输出堆顶元素后,最后一个元素来代替堆顶元素,再进行调整,使其仍为一个堆(堆是有条件的)
3.再重复步骤2,直到整个堆只剩一个元素,输出,堆排序结束
首先是对一组无序的数进行堆的建立:
//节点筛选,k为待筛选节点序号/数组下标,n为有效数据个数/数组长度,a为堆的数据
public void heapOne(int[] a,int n,int k) {
int k1 = 2*k+1;
int k2 = 2*k+2;
if(k1>=n&&k2>=n)return;//确认k1,k2为叶子节点
//Integer类中的一个int类型的常量MAX_VALUE,为int类型的最大存储值
int a1 = Integer.MAX_VALUE;
int a2 = Integer.MAX_VALUE;
if(k1<n)a1 = a[k1];//左孩子
if(k2<n)a2 = a[k2];//右孩子
if(a[k]<=a1&&a[k]<=a2)return;//完成堆的要求
//找到左右孩子中的最小值,和它交换
if(a1<a2) {
int t = a[k];
a[k] = a[k1];
a[k1] = t;
heapOne(a,n,k1);//继续筛选
}else {
int t = a[k];
a[k] = a[k2];
a[k2] = t;
heapOne(a,n,k2);//继续筛选子树
}
}然后输出堆顶元素以后,最后一个元素代替堆顶元素,再调用堆建立的方法
//堆的输出以及再排序
public void heapSort(int[] a) {
//建立初始堆
for(int i = (a.length-1)/2;i>=0;i--)heapOne(a,a.length,i);
//输出堆顶,再调整堆
int n = a.length;
while(n>0) {
System.out.print(a[0]+" ");//输出堆顶
a[0] = a[n-1];//最后元素移到堆顶
n--;//输出堆顶后长度-1
heapOne(a,n,0);
}
}调用方法输出
public static void main(String[] args) {
int[] a = {7,9,0,4,29,88,-9,8,10,-66,467};
Dui2 d = new Dui2();
d.heapSort(a);
}注:
堆排序方法对记录数较少的文件并不值得提倡,但对n较大的文件还是很有效的。因为其运行时间主要耗费在建初始堆和调整建新堆时进行的反复“筛选”上。
堆排序在最坏的情况下,其时间复杂度也为O(nlogn)。相对于快速排序来说,这是堆排序的最大优点。此外,堆排序仅需一个记录大小的供交换用的辅助存储空间。















 1427
1427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









