






1.相关概念
mysql与elasticsearch的概念对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
-
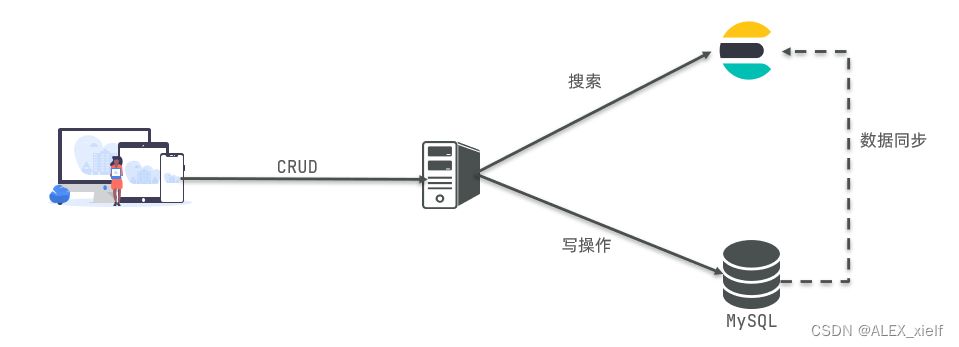
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性
2.索引操作
2.1 mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
-
数值:long、integer、short、byte、double、float、
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:参与搜索则需要创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
2.2 创建索引库

2.3 查询、删除索引库
GET /example
DELETE /example
2.4 修改索引库

3.文档操作
3.1 新增文档

3.2 查询、删除文档
GET /example/_doc/ 1
DELETE /example/_doc/ 1
3.3 修改文档

3.4 查询文档
3.4.1 基本语法

3.4.2 查询所有
-
查询出所有数据,一般测试用。例如:match_all
-
size控制每页展示数量,默认为20,size与query平级
3.4.3 全文检索查询
-
利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
-
match:根据一个字段查询
-
multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
-
搜索字段多,对查询性能影响大,因此建议采用copy_to,然后单字段查询的方式。
-
3.4.4 精确查询
-
根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
-
range:根据值的范围查询
-
term:根据词条精确值查询
-
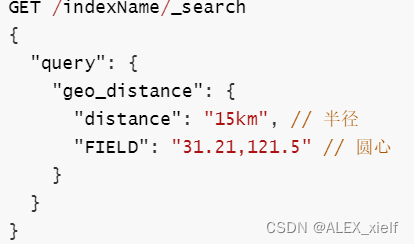
3.4.5 地理(geo)查询
-
根据经纬度查询。例如:
-
geo_distance:附近查询,查询到指定中心点小于某个距离值的所有文档
-
geo_bounding_box:矩形范围查询,指定矩形的左上、右下两个点的坐标
-

3.4.6 复合(compound)查询
-
复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
-
bool:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
-
function_score:算分函数查询,可以控制文档相关性算分,控制文档排名
-
(1)算分函数查询
语法说明:
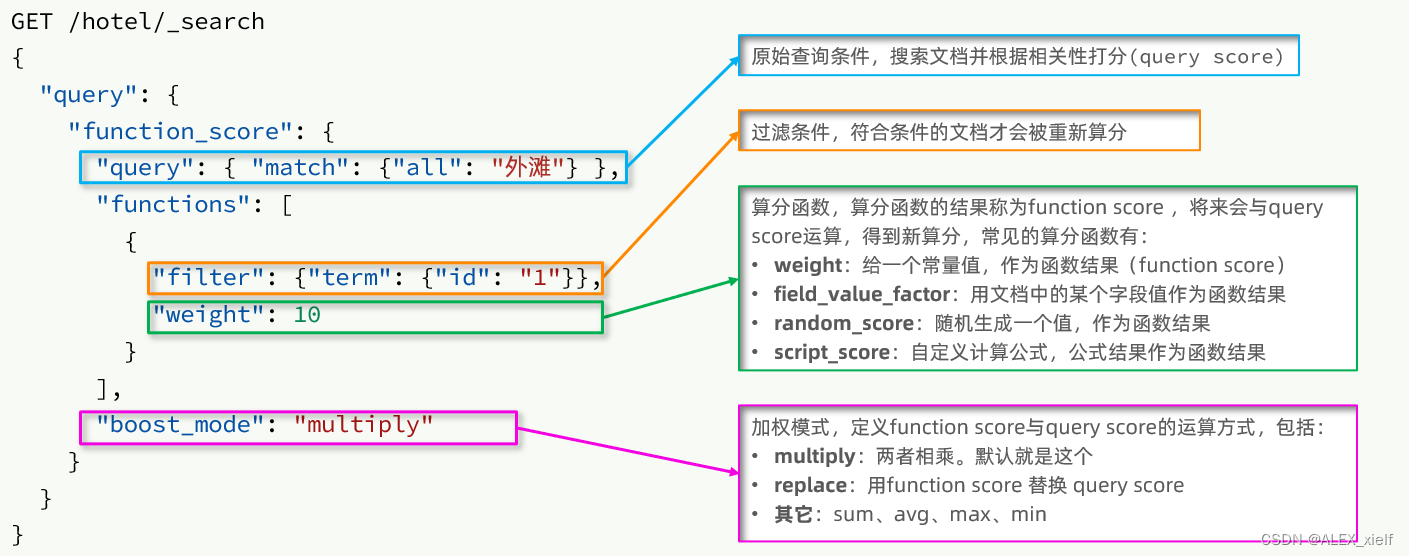
function score的运行流程如下:
-
1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
2)根据过滤条件,过滤文档
-
3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
-
4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
(2) 布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
-
搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
-
其它过滤条件,采用filter查询。不参与算分

3.5 搜索结果处理
查询之后对结果进行处理,和 “query” 是并列关系
3.5.1 排序
普通排序:

地理坐标排序:

3.5.2 分页

深度分页问题:
- 当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
- 针对深度分页,ES提供了两种解决方案:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
-
scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
-
分页查询的常见实现方案以及优缺点:
- from + size:
- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
- after search:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
- scroll:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
3.5.3 高亮

注意:
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false,例如对copy_to了的字段
4. 聚合
聚合是对文档数据的统计、分析、计算
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
参与聚合的字段类型必须是: keyword 、数值、 日期、 布尔
4.1 bucket 聚合
aggs与query,size,bool平级
默认情况下,Bucket聚合会统计Bucket内的文档数量,并且按照count降序排序,可以自定义。
添加query条件,可以对限定条件的结果聚合。

结果:

4.2 Metric聚合
还可以给聚合结果做个排序,方式同上。
聚合类型可以指定为某一个,也可以直接写stats,min max avg count 都会显示

5. 设计索引库数据结构范例
#查询索引库
GET /hmall
#删除索引库
DELETE /hmall
# 查一个值
GET /hmall/_search
{
"size": 1
}
# 创建索引库
PUT /hmall
{
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
},
"completion_analyzer":{
"tokenizer":"keyword",
"filter":"py"
}
},
"filter":{
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings": {
"properties": {
"category":{
"type": "text",
"index": true,
"copy_to": "all"
},
"brand":{
"type": "text",
"index": true,
"copy_to": "all"
},
"price":{
"type": "long",
"index": true
},
"sold":{
"type": "integer",
"index": true
},
"id":{
"type": "long",
"index": true
},
"name":{
"type": "text",
"index": true,
"copy_to": "all"
},
"commentCount":{
"type": "integer",
"index": true
},
"image":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_max_word"
},
"suggestion":{
"type":"completion",
"analyzer": "completion_analyzer",
"search_analyzer": "keyword"
}
}
}
}
















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









