







背景
当我们浏览博客文章时,经常会看到诸如浏览次数、阅读次数、收藏次数这类统计信息。类似地,我还想到其它网站的一些使用场景,例如抖音某个视频的点赞数量、电子商务网站某件商品访问者数量等等。这激发了我的好奇心,我想知道如何通过程序来统计网站的这些计数。
简单快速的解决方案
首先,我能想到的最有效的数据结构是集合(Set),因为集合不允许元素重复,因此集合的大小就可以表示集合内不重复元素的计数。下面是一段利用集合来统计不重复访客数量的代码:
public class UniqueVisitors {
private Set<String> visitors = new HashSet<>();
public void addVisitor(String ip) {
visitors.add(ip);
}
public int getUniqueVisitorCount() {
return visitors.size();
}
public static void main(String[] args) {
UniqueVisitors uniqueVisitors = new UniqueVisitors();
uniqueVisitors.addVisitor("192.168.0.1");
uniqueVisitors.addVisitor("192.168.0.2");
uniqueVisitors.addVisitor("192.168.0.1");
System.out.println("Unique Visitors: " + uniqueVisitors.getUniqueVisitorCount());
}
}
//输出
Unique Visitors: 2
任务完成了吗?

刚写完上面的代码时,我的反应就像这个著名的“成功小子”一样得意。然而,如果进一步思考:每次有新访客访问页面时,我们都需要将这个访客的信息存储在内存中(可以根据IP地址/会话等来识别新用户)。如果网站的规模像微信、淘宝这样庞大,每天有数亿用户访问,这个解决方案还能有效吗?
上面的解决方案需要与用户数量成比例的内存空间。假设我们有1亿访客,让我们做个简单的计算:
访问者对象的空间 = 100 B
访问者数量 = 1亿
所需总空间 = 1亿 * 100 B ≈ 9.31 GB
这意味着我们需要大约9.31 GB的空间来获取唯一访客的计数。因此,这个算法在大规模应用场景并不高效——浪费了很多空间。
我在谷歌上搜索互联网大厂是如何解决这个问题的,令人惊讶的是,这个看起来很简单的问题竟然是计算机科学中最著名的问题之一,称为“计数独特问题”。
在搜索这个问题过程中,我接触到了HyperLogLog算法,它可以高效地计算集合中的不同元素数量,并且消耗的空间很少。
下面让我们一起看看这个算法 !
HyperLogLog
正如我们在前面的例子中看到的那样,如果使用Set统计计数,会得到一个准确的计数值,但是,随着规模的增加,消耗的内存空间也会增加。
其实,对于像博客文章点赞,转发量这些场景其实并不需要显示百分百准确的计数,一定误差(例如小于3%)是完全可以接受的。
HyperLogLog算法可以做到用不到1.5KB内存来计算海量数据集基数的问题,并且误差估计小于2%。
基本工作原理
在深入研究 HyperLogLog 的内部工作原理之前,先假设您正在和朋友在玩一个游戏,在这个游戏中,你朋友会将一块硬币抛很多次,并记录下最多连续出现正面的次数n。然后,他会将这个n告诉你,让你猜测他大概抛了多少次硬币。
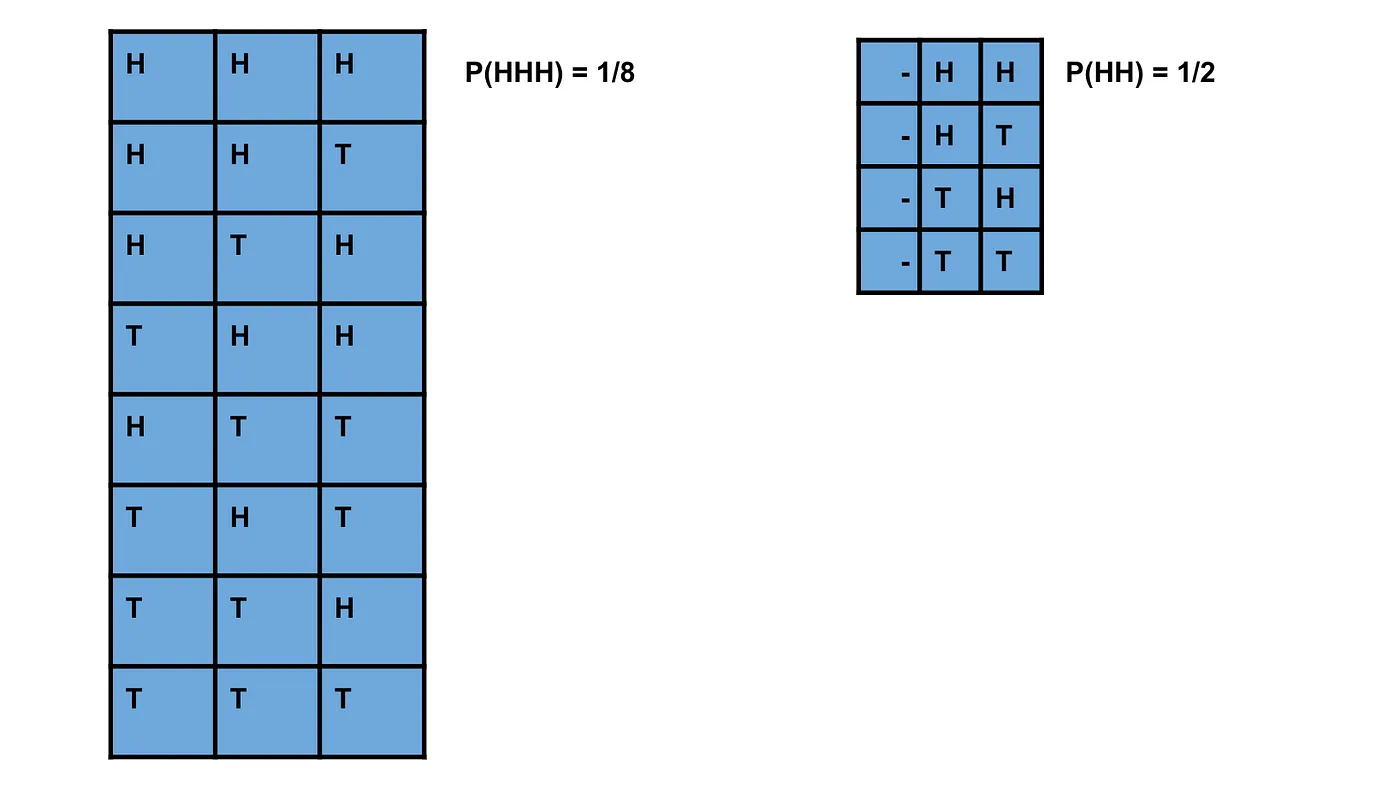
例如,如果你朋友告诉你n=1,那么他大概抛了2次, 因为抛一次硬币出现正面的概率是1/2,那平均来说,你朋友需要大约抛2次硬币才能得到一次正面。第一次掷可能是正面,也可能不是,所以大约需要2次尝试。
如果你朋友告诉你n=2,那么他大概抛了4次,因为连续出现2次正面的概率是 1/2 * 1/2 = 1/4。因为只有1/4的可能性能够连续两次掷出正面,平均来说,你需要掷4次硬币才能达到这个结果。
这是一个简单的概率应用:如果某个事件的概率是1/n,那么通常你需要尝试n次才能期待发生一次这种事件。
因此,如果连续出现了 n 次正面(概率为1/(2^n)),那么预计需要的总掷硬币次数大约是 2^n 次。
HyperLogLog算法使用了相同的原理,不同之处在于HyperLogLog算法中使用1和0代替正面和反面。
哈希函数的输出通常是均匀分布的,这意味着每一个可能的输出值出现的概率是相同的。对于一个N位的二进制哈希输出,每个位都有1/2的概率是0或1。
在均匀分布的情况下,得到一个有k个前导0的哈希值的概率是1/2k。如果我们集合中n个元素得到的n个哈希值中最大的前导0个数是k,意味着我们需要大约2k个元素来“填满”这个概率空间,也就是说n为2k,即集合中元素的个数大概是2k个
总结一下,如果我们在哈希结果集中观察到的前导零最大个数是k,就可以估计出这个数据集的基数大约为2k。也就是说,数据集中不同元素的数量约为2k。
让我们回顾一下之前计算网站上唯一访客数量的例子。为简单起见,我们使用用户的 IP 地址作为用户标识符。此 IP 地址传递给哈希函数,n个用户IP对应n个哈希值,其中哈希值中前导零最大数量为20 ,那么就可以估算出用户数量为2²⁰ 。
下面是这种方法的两个缺点:
-
计数总是2的幂次方数。所以有效值只能是{1,2,4,8,16,32,64,128,256,512,1024…等}。但事实上,我们要统计的指标如点赞数其数量可以是任意数值。这导致准确性差。
-
这种方法的变异性很大。如果我们只有一个访客,幸运的话其哈希值10个连续的前导0,根据算法就会错误地估计有 2^10 = 1024 个访客。而且错的离谱。
提高准确性和减少变异
在上述方法中,我们做一个小小的改变:不依赖于单个哈希函数,而是使用多个哈希函数来减少变异。对于每个哈希函数,我们计算前导零的数量,然后找到算术平均值,并使用这个平均值来得到基数。
例如,如果我们使用10个哈希函数,其中一个哈希函数的输出有20个前导零,而其他9个哈希函数可能有一个前导零。在这种情况下,平均值将是(201+19)/10 =2.9,基数是2^(2.9),比2²⁰要好。
除了使用多个哈希函数之外,还有一种替代方法是利用Durand 和 Flajolet提出的解决方法。
下面是这个方法的主要流程:
1. 哈希值分桶,记录前导零
首先,将哈希函数的输出分成多个桶。桶记录遇到的最大连续零的数量。
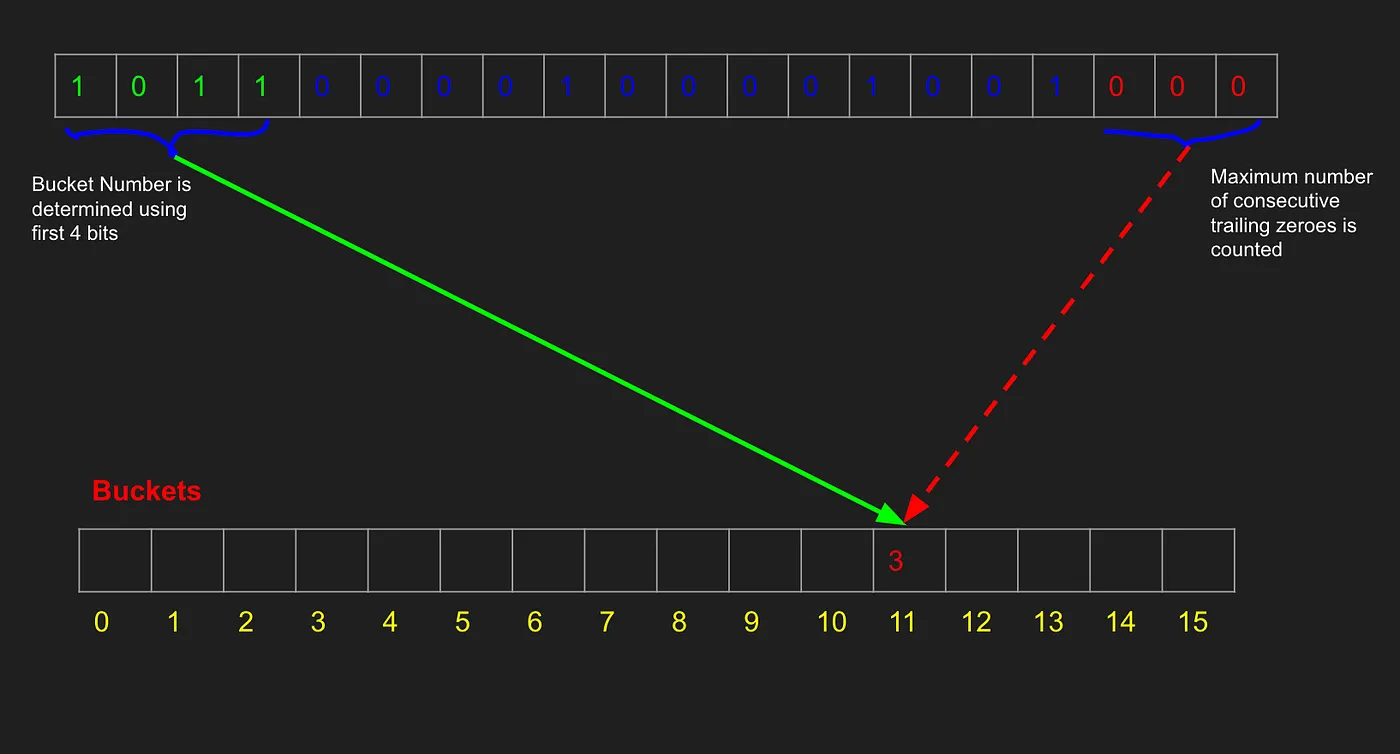
假设有个用户的 IP 地址是 192.168.0.1。我们把这个 IP 地址通过哈希函数得到的哈希值是 10110000100001001000。我们使用哈希值的前四位来决定它属于哪个桶。这里前四位是 1011,转换为十进制是 11,所以它属于第 11 号桶。
接着,我们从右边开始数哈希值中的连续零的数量。在这个例子中,哈希值 10110000100001001000 从右边开始有 3 个连续的零。因此把第 11 号桶的值更新为 3。
2. 更新桶中的值
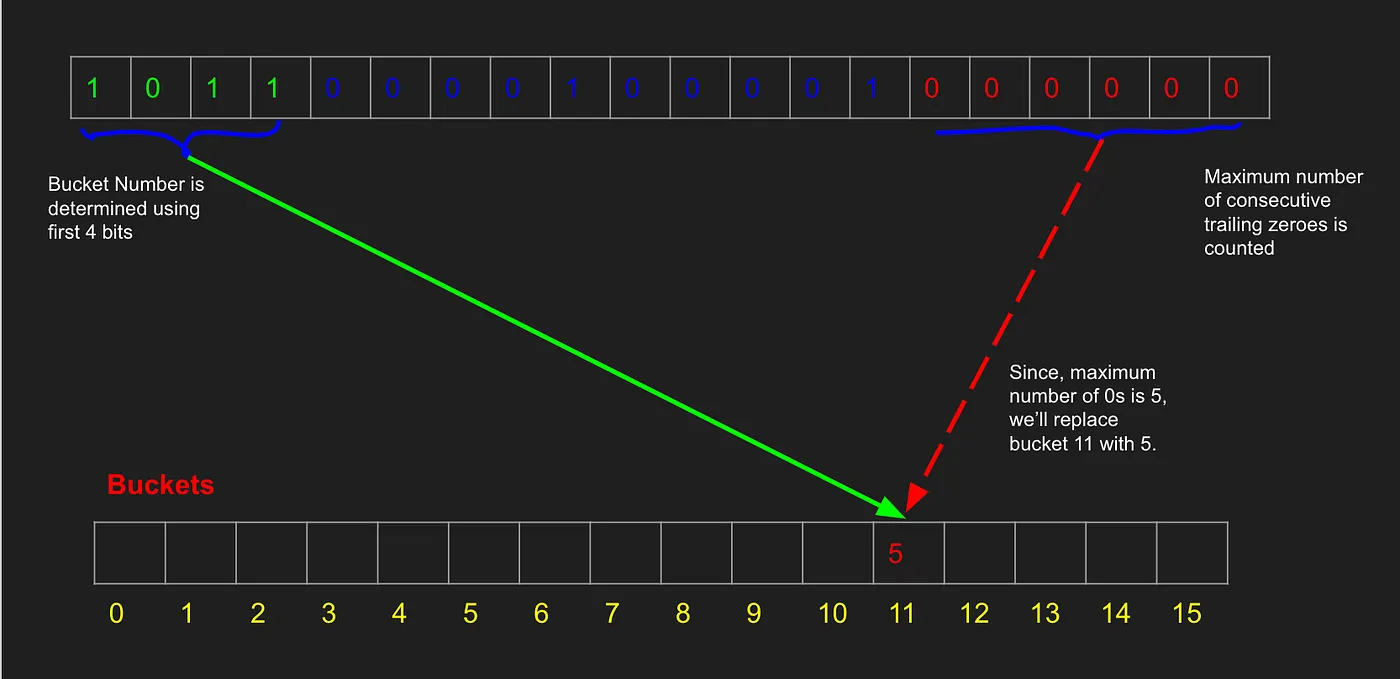
当我们处理新的数据时,比如另一个用户的 IP 地址(如 192.168.0.2),再次通过哈希函数得到新的哈希值,比如 1011000010000100000。我们用这个新哈希值的前四位 1011 发现它仍然属于第 11 号桶。此时,我们从右边开始数,发现哈希值 1011000010000100000 中有 5 个连续的零。
由于新哈希值中连续零的数量(5)比第 11 号桶当前记录的数量(3)多,我们更新第 11 号桶的值为 5。
3. 计算基数
最终,我们计算所有桶的最大前导零数量的调和平均数,然后使用这个调和平均数来估算数据集的基数。
计算基数的公式是:
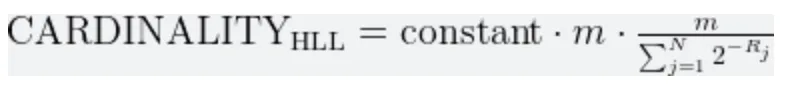
上式中的常数为 0.7942,用于纠正偏差。m是桶数。第三项是调和平均值,Rjs 表示从最左边的位开始的最大零的数量。
误差估计为 1.05/(√m),其中 m 是桶数。当 m=2048 时,误差估计降低至 2.32%。对于 100 万人口,我们的估计值将在 976798 和 1023201 之间。
Java 中 HLL 的实际实现
在下面的代码中,使用了 Google 的 guava java 库提供的 Murmur3_32 哈希函数。迭代了数百万个整数并计算每个整数的哈希值。由于输出是 32 位整数,因此前 5 位用于将哈希值分配给存储桶。我们有 2⁵ = 32 个存储桶,每个存储桶保存从最右边的位开始的最大连续零。
在计算出哈希所属的存储桶之后,我们将获得该哈希的最大尾随零,如果哈希的最大尾随零大于存储桶中存储的零,则更新存储桶(第 19-23 行)。
我们使用上一节提到的基数公式来估计元素的数量。
public class HyperLogLog {
public static void main(String[] args) throws Exception{
HashMap<Integer, Integer> buckets = new HashMap<>();
HashFunction hashFunction = Hashing.murmur3_32();
for (int x = 0; x < 1000000; ++x) {
int msb = hashFunction.hashInt(x).asInt() & 0xf8000000;
msb = msb >>> 27;
int trailingZeroes = trailingZeroes(hashFunction.hashInt(x).asInt());
if (!buckets.containsKey(msb)) {
buckets.put(msb, trailingZeroes);
} else if (trailingZeroes > buckets.get(msb)) {
buckets.put(msb, trailingZeroes);
}
}
buckets.forEach((key, value) -> {
System.out.println("bucket = " + key + " leading zeroes = " + value);
});
System.out.println("Harmonic mean = " + harmonicMean(new ArrayList<>(buckets.values())));
System.out.println(32*0.79*harmonicMean(new ArrayList<>(buckets.values())));
}
static float harmonicMean(List<Integer> arr)
{
float sum = 0;
for (int i = 0; i < arr.size(); i++)
sum = sum + (float)1 / (int)Math.pow(2, arr.get(i));
return (float)32/sum;
}
static int trailingZeroes(int number) {
int count = 0;
for (int index = 1; index <= 27; ++index) {
if (getNthBit(number, index) == 1)
break;
++count;
}
return count;
}
static int getNthBit(int num, int n) {
return ((num >> (n - 1)) & 1);
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









