







Twitter 使用什么数据库存储用户每天发送的数亿条推文?是 SQL、NoSQL 还是其它持久化存储系统?

Twitter 使用什么数据库?
任何一个稍微有点规模的系统其存储层绝不会只使用一种数据库,服务于数以亿计用户的Twitter更是如此。Twitter使用的数据库主要有以下几种:
- Hadoop:用于社交图分析、推荐、趋势、API 分析、用户参与度预测、广告定位、广告分析、推文印象处理、进行 MySQL 备份、Manhattan 备份和存储前端抄写员日志。
- MySQL 和 Manhattan:存储用户数据。
- Memcache、Redis: 用于缓存
- FlockDB: 用于存储社交图谱
- MetricsDB: 用于存储平台数据指标
- Blobstore: 用于存储图像、视频和大型二进制对象。
现在让我们分别讨论一下这些数据存储。
Hadoop
Twitter 运行着世界上最大的 Hadoop 集群之一。最初,Hadoop 被用于 Twitter 上的 MySQL 备份,随着时间的推移,其使用案例大大增加。
如今,它不但用于MySQL 备份,还用于对用户在平台上执行的操作进行分析,包括社交图谱分析、推荐、趋势、API 分析、用户参与度预测、广告定位、广告分析、推文印象处理等。
Hadoop 文件系统存储了超过 500 PB 的数据,运行在数万个实例上。整个集群使用Hadoop Federation 功能进行管理,每天运行数十万个 Hadoop 作业和数千万个 Hadoop 任务。
Twitter每天有超过 15 万个服务和 1.3 亿个容器在运行。
为了扩展服务,Hadoop 使用不同的Namenode独立运行,且彼此之间没有依赖关系。
有一些节点称为数据节点Datanode,用于数据存储。这些数据节点在集群中向 Namenode 注册。
为了管理命名空间,使用了View 文件系统,这对于管理具有多个 Namenode 的集群很有用。
每个集群都有超过3500个Namenode。
关系数据库-MySQL,PostgreSQL
Twitter 最初以 MySQL 作为主要数据存储,然后逐渐从单一实例发展到大规模集群。
Twitter 自成立之初就拥有了世界上最大的 MySQL 集群之一。它包含数千个节点的 MySQL 实例,每秒可处理数百万次查询。
MySQL 主要有两种用例:
- 充当 Twitter 分片框架内分布式数据存储的存储节点。MySQL 存储节点为整个分布式存储提供可靠性和性能。
- 为广告、身份验证、Twitter 趋势和许多内部服务等服务提供支持。
Twitter 的工程团队还基于 Apache Mesos 构建了一个可扩展的 MySQL 数据库集群管理框架,称为 Mysos。它的主要目的是简化和自动化 MySQL 数据库实例的管理和调度,使得数据库在大规模环境中更加稳定和可靠。
除了 MySQL,其他基于 SQL 的数据存储(如 PostgreSQL 和 Vertica)也用于存储广告活动、销售和内部工具数据。
BlobStore
Blobstore 是 Twitter 的可扩展存储系统,用于存储用户图片、视频和其他大型二进制对象。它使 Twitter 能够降低存储用户上传的推文图片的成本。
它是一个高性能系统,能够每秒处理数十万的请求的同时在几十毫秒内提供图片。
当图片上传到 Blobstore 时,它会通过异步队列服务器将图片同步到 Twitter 的所有数据中心。
Memcache 和 Redis
通过缓存,Twitter 向客户端每秒传递约 120GB 的数据。
Twitter 的缓存有两个主要用途:
- 第一个是存储热点数据,可以避免直接访问数据库。
- 第二个,用于存储需要反复计算的中间数据或最终结果,避免重复计算。
Twitter 内部运行着许多缓存服务,其中之一是Redis。Redis 集群缓存用户消息、广告支出、展示次数和参与度等等。
此外,Twitter 还自研了Twemcache,这是 Memcache 的定制版本,适合大规模生产部署。该平台拥有数百个缓存实例,内存中存储着来自 30 多个服务的超过 20TB 的数据。总体而言,缓存层每天可处理超过 2 万亿次查询。
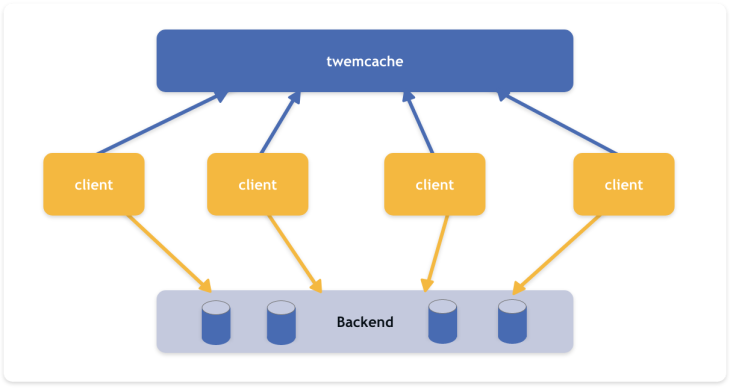
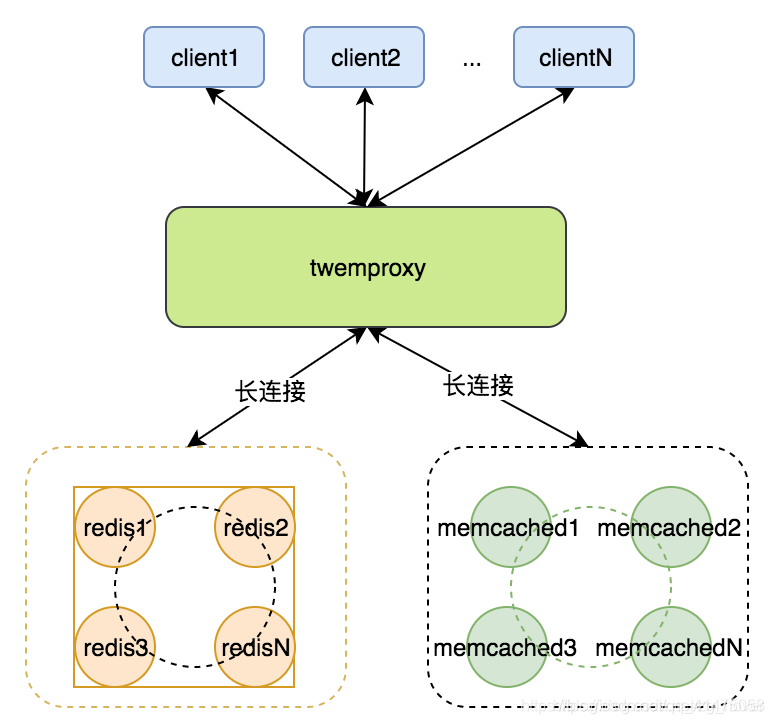
为了方便缓存的管理,Twitter又自研了一款轻量级缓存代理服务器–Twemproxy,它支持 Memcached 和 Redis 协议。它的主要作用是将客户端的请求分发到多个缓存服务器,从而实现缓存系统的横向扩展。Twemproxy 提供了一个单一的入口,使得客户端无需知道后端有多少缓存服务器,也无需处理服务器之间的数据分布和负载均衡问题。
Metrics DB
MetricsDB 是 Twitter 用于存储和管理平台数据指标的时间序列数据库。它具有高效的压缩和多区支持等特性,能够处理海量数据和高并发查询。指标的摄取率超过每分钟 50 亿个指标,每分钟 25K 个查询请求。
最初,Manhattan 用作指标存储数据库,但 Twitter 面临可扩展性问题以及不支持附加的分钟指标标签。
这导致了内部开发 Metrics DB,使用了 Facebook 内存时间序列数据库 Gorilla 的压缩算法。
Metrics DB 提供多区域支持、指标分区,压缩效率高于 Twitter 使用的其他数据存储。使用 Gorilla 的压缩算法,Twitter 减少了 95% 的空间使用量。
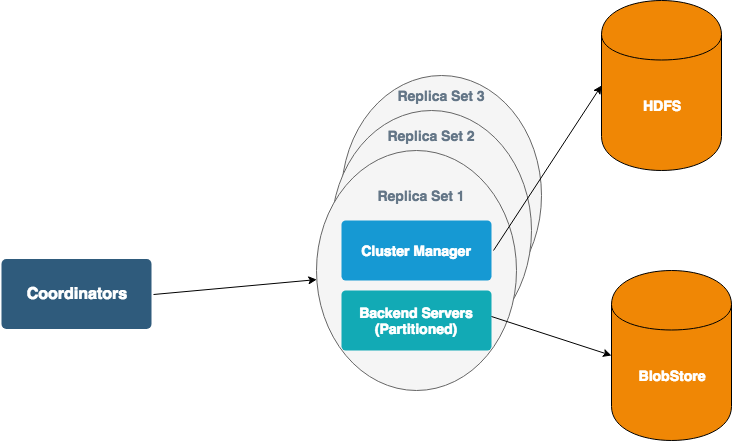
MetricsDB 有 3 个主要组件:
- ClusterManager:ClusterManager 负责管理整个 MetricsDB 集群,包括协调数据的分配、处理节点的状态监控、负载均衡等。它确保所有的数据存储节点正常工作,并在出现问题时进行相应的处理。想象一个公司的经理,他负责管理公司的所有员工,分配任务,监控工作进度,并确保每个人都在按计划工作。如果某个员工遇到问题,经理会及时介入,进行调整和帮助。ClusterManager 的作用类似于这位经理,管理和协调整个集群的运作。
- BackendServers:BackendServers 是实际存储和处理数据的节点。每个服务器存储一定量的时间序列数据,并负责处理查询请求。这些服务器是系统的核心部分,每个 BackendServer 都会在内存中保存所有指标的最新两小时数据,BackendServer 还会缓存经常访问的指标和时间范围的旧数据。
- Coordinators:Coordinators 负责处理客户端的请求,并与 BackendServers 协作以完成数据存储和查询操作。它们充当客户端和 BackendServers 之间的中介,确保数据的正确存取和高效处理。想象一家大型公司的前台接待员,他们接待来访者,并根据来访者的需求将其引导到相应的部门或人员。Coordinators 就像这些接待员,负责处理客户端请求并将其分配到正确的存储节点。
FlockDB
FlockDB 是一个分布式图形数据存储,专为快速图形遍历、存储邻接表、支持高频添加、删除和更新操作、分页处理数百万条目、横向扩展和运行图形遍历查询而设计。
Twitter 使用它来存储社交图,包含谁关注谁等信息。

















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









