









在过去的二十年里,由于分布式数据库的使用越来越广泛,数据库复制的概念也得到了发展。然而,其核心原则大体上没有太大变化。
在本文中,我们将讨论数据库复制的相关事项。
什么是数据库复制?
数据库复制是指将相同数据的多个副本保存在不同的数据库服务器(也叫副本或实例)中的过程。这样,如果某个数据库服务器出现问题,其他服务器仍然可以继续为用户提供数据服务。这种方式能够提高系统的性能、可用性和可靠性。
想象一下,一个公司把重要的文件复印了好几份并放在不同的地方,这样即使其中一份丢失了,其他地方还有备份,工作也不会受到影响。数据库复制就像这种“复印”的过程,只不过过程复杂很多。
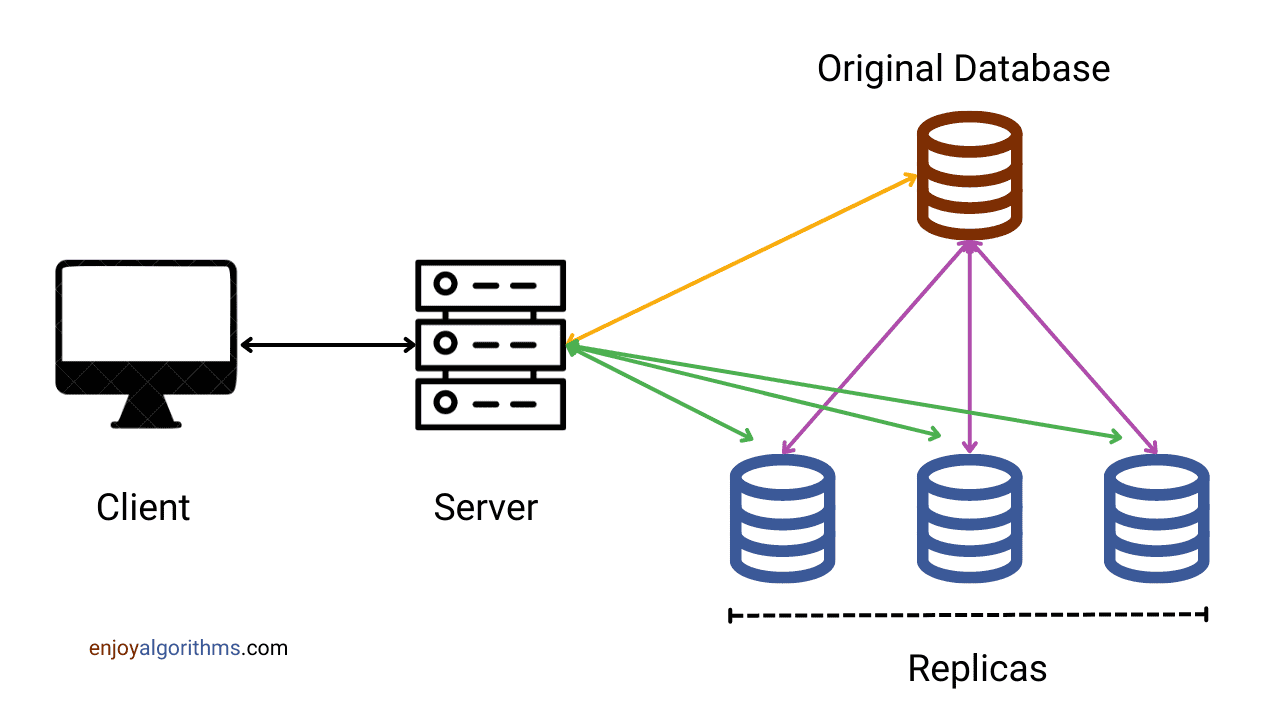
假设有一家在线商店,它只有一个数据库服务器,存储了所有与产品、订单和客户相关的数据。如果由于某些原因(硬件问题、软件问题等),这台数据库服务器发生故障,整个网站将不可用,这对于用户来说是绝对不可接受的。
为了解决这个问题,我们可以使用数据库复制。网站所有者可以设置多个数据库服务器,从主数据库服务器复制数据。如果主服务器宕机,其他从服务器可以接管并继续处理请求。
如果我们的数据不会随时间变化,那么数据库复制过程非常简单:我们只需将数据复制到每个节点一次即可。数据库复制的所有难点都在于如何处理复制数据的变化。
基于不同架构的数据库复制技术
确保对一个节点上的数据所做的任何更新都能反映到所有其他节点上是非常重要的。因此,我们需要一些技术手段来确保所有节点拥有最新的数据。
有三种类型的数据库复制技术:单主复制、多主复制和无主复制。每种类型的复制技术都有其优缺点。
单主复制架构
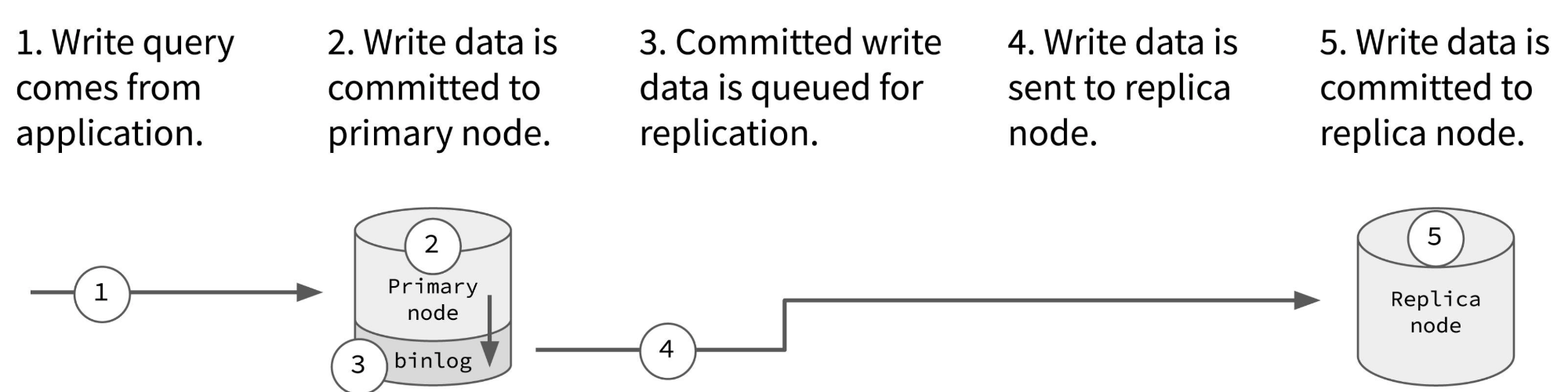
这种架构也被称为主从复制或主动-被动复制。在单主复制中,只有一个主节点(领导者/master),可以有多个从节点(跟随者/slave)。所有写请求由主节点处理,所有读请求由主节点或从节点处理。最好的做法是只使用主节点处理写请求,将读请求分配给从节点,以减轻主节点的负担。
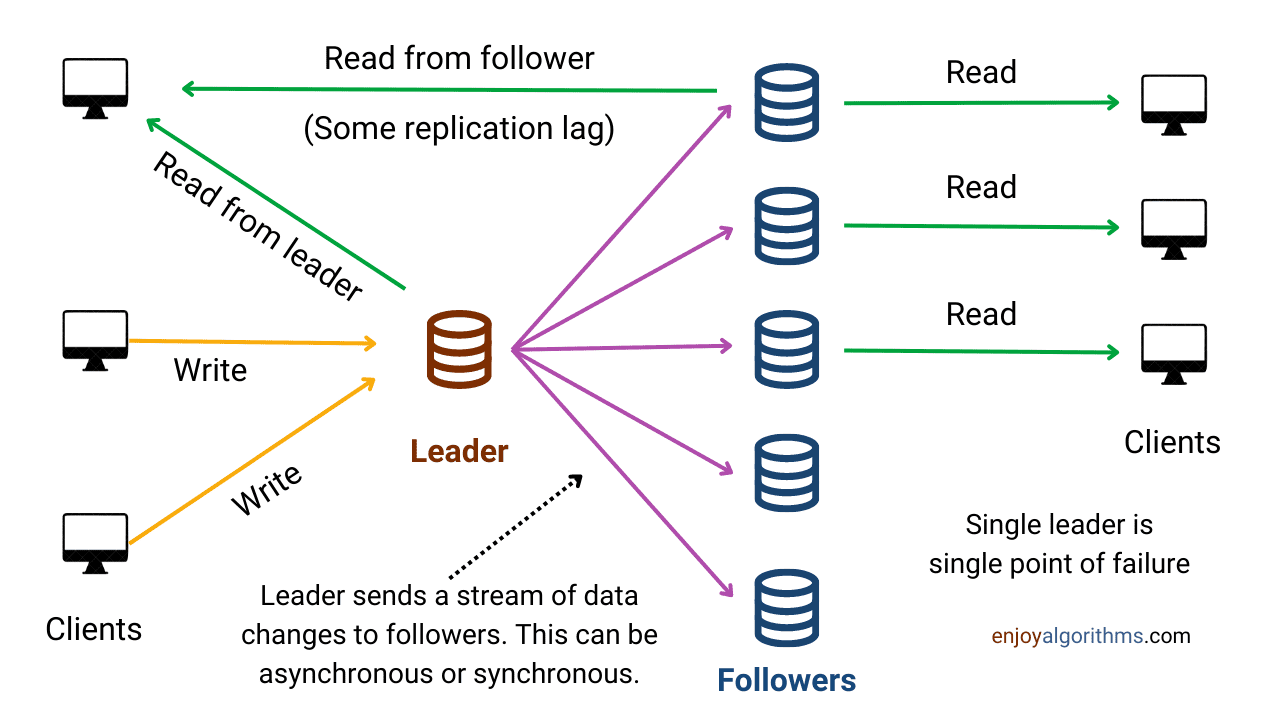
对于写请求,主节点在处理完写请求后,会将数据更改的操作以某种形式(如MySQL中以binlog日志)发送给从节点,以更新从节点对应的数据。
这种方法比较简单,但由于主节点只有一个,如果主节点故障,系统可能在选出新主节点之前变得不可用。
在复制过程中,我们需要处理一个关键问题:复制过程可能存在延迟(复制延迟),如何尽量减少这种延迟?
这种架构在读写比非常高的情况下是一个不错的选择。
多主复制架构
前面提到了数据库单主复制架构存在的一个大问题:如果主节点由于某种原因不可用,我们无法在升级另一个从节点副本为主节点之前执行写操作。
解决该问题的常见方法是使用多主复制。这也被称为主-主复制或主动-主动复制。
在这种架构下,存在多个主节点,客户端可以将写请求发送给任一主节点,每个主节点同时也是其他主节点的从节点。因此,每当主节点执行写操作时,它同时会将数据更改流转发给所有其他主节点。
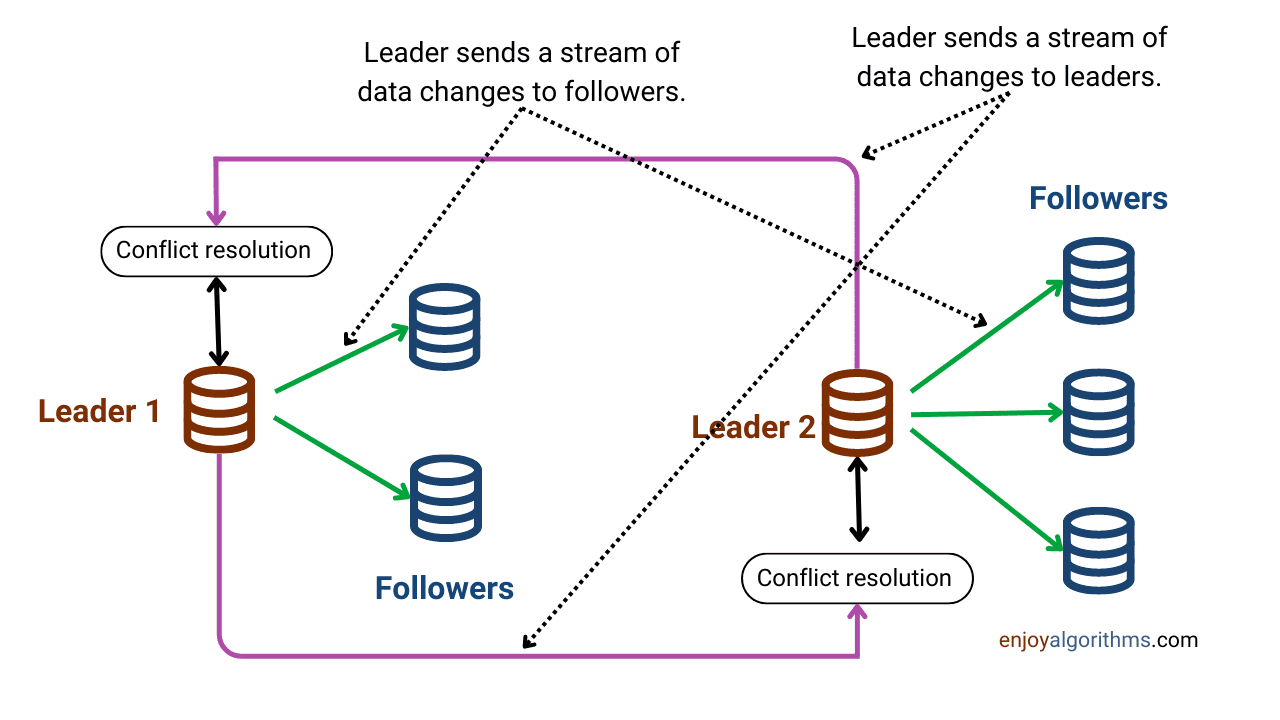
多主复制架构提供了冗余,即使系统中一个主节点发生故障,系统仍然可用,因为还有其它的主节点可以处理写请求。
但多主复制架构也带来了一些复杂性。例如,当两个或多个主节点同时收到冲突的写请求时,可能会出现冲突。因此,必须有冲突解决机制来确保数据一致性。
无主复制架构
这也被称为无领导复制。在这种架构中,客户端将写请求发送给多个节点,并行地从多个节点读取。在这种方法中没有领导者的概念,这允许任何副本直接接受客户端的写操作。
无领导复制可以提供高可用性和容错性。由于没有单点故障,即使某些节点发生故障,系统也可以继续运行。它还可以提供高读写吞吐量,因为读写请求都可以分摊到多个节点上处理。
然而,这种方法在同步方面存在挑战,因为很难确保所有节点始终拥有相同的数据视图。此外,处理并发写入引发的冲突也非常复杂,需要精心设计以确保数据一致性。
下面举个栗子来帮助我们理解这种架构。
假设你和几个朋友一起在线合作编写一本书,每个人都有这本书的副本,都可以在自己的副本中添加内容或修改现有的文本。
在这个项目中,任何人都可以随时对书的内容进行修改,并且这些修改会被同步到其他人那里。比如你在家里写了一段新的内容,你的朋友在他的电脑上也会自动收到这段内容的更新。
现在,如果你的电脑突然坏了,或者你暂时失去了网络连接,其他朋友的工作不会受到影响,他们依然可以继续编辑书的其他部分。这是因为大家都有各自的副本,没有单一的中心点或“领导”节点。如果某个节点(某个人)出问题,系统仍然可以继续正常运行。
由于每个人都可以独立地进行编辑,整个团队可以并行工作,效率很高。你在修改第3章的内容时,你的朋友可以同时在第7章添加新的段落,互不干扰。
前面提到的数据同步带来的挑战是:如何确保所有人手里的书都是最新版本?假如你和你的朋友同时修改了同一个章节,那么当你们的修改内容同步时,系统必须决定哪一方的修改会被保留。比如,你写的内容是“在这个故事中,主角是一个勇敢的骑士。”而你的朋友同时写的是“在这个故事中,主角是一个聪明的魔法师。” 当这两段内容同步时,系统就需要做出决定:是选择保留“骑士”还是“魔法师”?
同步复制和异步复制
同步复制
在同步复制中,一旦主节点更新了其自身的数据,它会将数据更新操作同步给从节点:从节点接收数据更新操作并执行更新,然后将确认发送给主节点。一旦主节点收到所有从节点的确认,它才会响应客户端,整个数据更新过程才算成功。
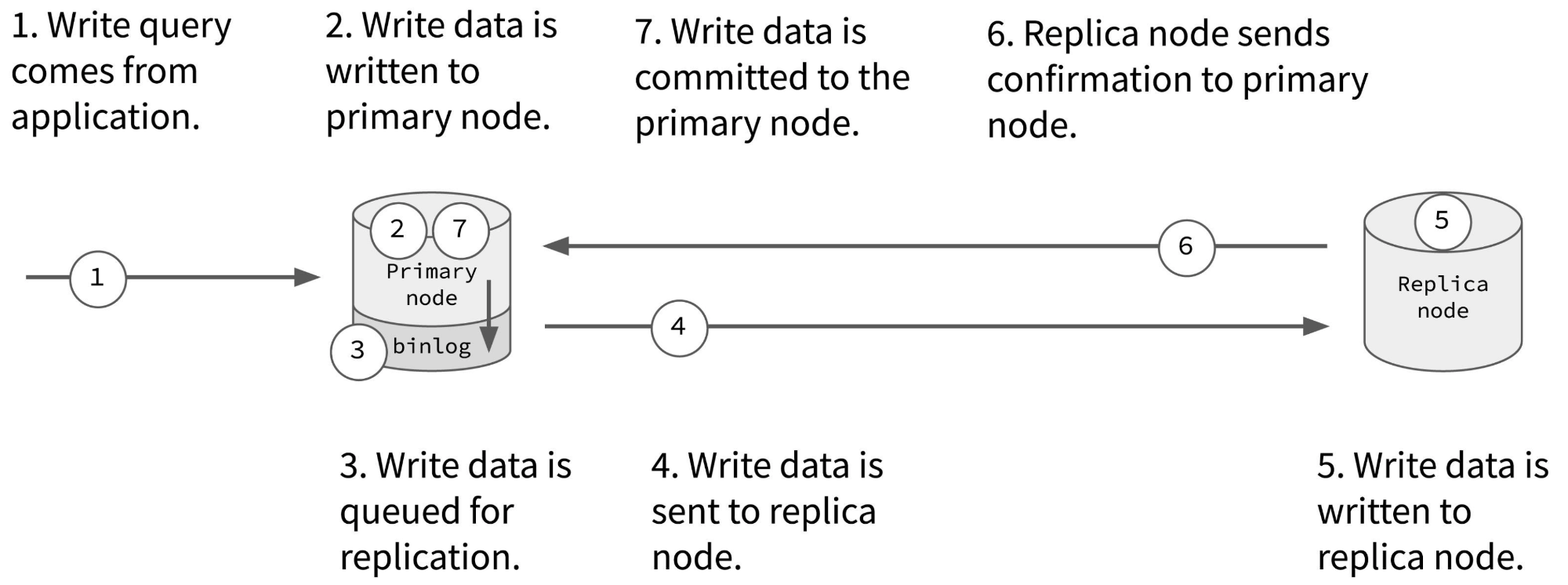
同步复制确保从节点始终与主节点保持数据同步和一致,从而具有容错性。即使主节点崩溃,因为从节点包含全部的数据。系统可以轻松地将任何一个从节点提升为新的主节点,并继续正常运行。
想象一下,你在网上购买商品时,系统需要在库存数据库中减少一件商品。在同步复制的情况下,系统会确保所有副本数据库都更新了库存数量后,才会告诉你购买成功。这确保了无论哪个数据库在查询,库存数量都是一致的。
但是这种方式由于主数据库需要等待从数据库的确认,这可能会导致系统响应时间变慢,尤其是在网络延迟较高的情况下。
异步复制
在这种策略中,主节点在更新完其自身的数据后就立即响应客户端,而无需等待更新操作传播到从节点。这种方式效率高,但存在数据丢失的风险,因为对客户端的响应是在复制过程之前已经发出。复制过程是在后台进行的,主节点异步地将更改传播给从节点。如果主节点节点崩溃,未传播的数据更改将永久丢失。而且这种数据丢失客户端并不知情,只有线上出了bug才可能知道。
还是以上面购物的场景作为例子。在异步复制的情况下,系统在你下单后立即减少主数据库中的库存数量,然后就确认购买成功,但其它副本的数据可能稍后才更新。如果在这个过程中你恰好从副本数据库中查询库存,可能会看到旧的数据(比如显示库存还有,但实际上已经没有了)。
尽管存在这一缺点,但异步复制是大多数数据存储的默认的复制策略,因为它的效率高。
如何选择
同步复制适用于对数据一致性要求非常高的场景,比如金融系统或订单管理系统,虽然性能会有所牺牲。
异步复制适用于对性能要求高但对数据一致性要求稍低的场景,比如社交媒体应用或内容分发网络,这种方式可以提供更快的响应速度。
数据库复制的特点
数据库复制的优点
-
数据库复制帮助我们扩展能够提供读写查询的机器数量,从而增加吞吐量,并允许并行处理更多的查询请求。
-
它可以帮助我们将数据保存在地理上接近用户的位置,从而减少延迟。最好的例子是CDN。
-
如果某个数据库服务器被自然灾害摧毁,数据仍然得以保留。我们不需要担心数据丢失,因为数据在多个位置复制。
-
通过在不同的数据库服务器之间复制数据,即使数据库服务器因维护或其他原因宕机,网站仍然可以正常运行。
数据库复制的缺点
-
在多个服务器之间复制数据会增加数据库系统的复杂性。
-
维护复制系统可能会很昂贵,因为它需要额外的硬件、软件和IT资源。
-
当对主数据库进行的更改未立即传播到从数据库时,这可能导致不同实例之间的数据不一致。
-
当在不同的数据库实例中对相同数据进行更改时,可能会发生数据冲突。如果未正确解决冲突,可能会导致数据不一致甚至数据丢失。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









