







想象一下,你经营着一家大型网上商店,而今天是全年最忙的购物日。
许多人都在访问你的网站,以获取最优惠的交易。

突然间,你的服务器崩溃了,网站宕机,客户无法购物。
这样的事件会严重影响公司的销售和声誉。
这就是为什么确保系统始终可用如此重要的原因。
在这篇文章中,我们将探讨可用性的概念、可用性等级、提高可用性的策略以及实现高可用性的最佳实践。
什么是可用性?
可用性是指系统正常运行时间占实际运行时间的比例。所以,可用性其实是一个百分比,如99.9%。
可用性的正式定义是:
Availability = Uptime / (Uptime + Downtime)
Uptime:系统正常运行的时间。
Downtime:由于故障、维护或其他问题,系统不可用的时间段。
可用性等级
可用性通常用“几个九”来表示。可用性越高,宕机时间越少。
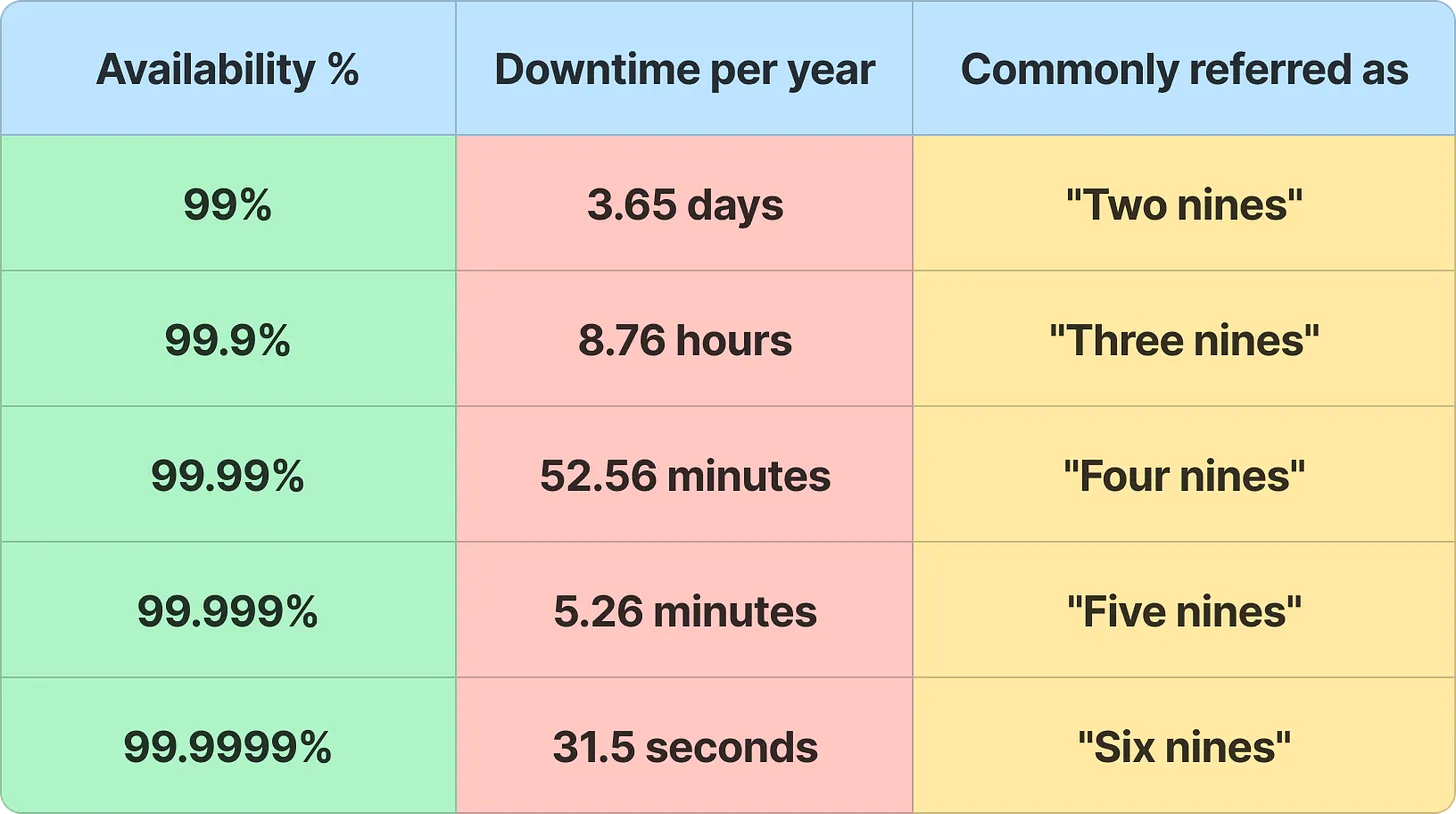
每增加一个“九”,就代表着可用性提高一个数量级,例如:99.99%的可用性相比于99.9%可用性,正常运行时间提高了10倍。
提高可用性的策略
1.冗余
冗余就是在系统中增加备份组件的做法,确保在主组件发生故障时,备份组件可以接管主组件的工作。这样即使遇到问题,系统仍然可以正常运行。
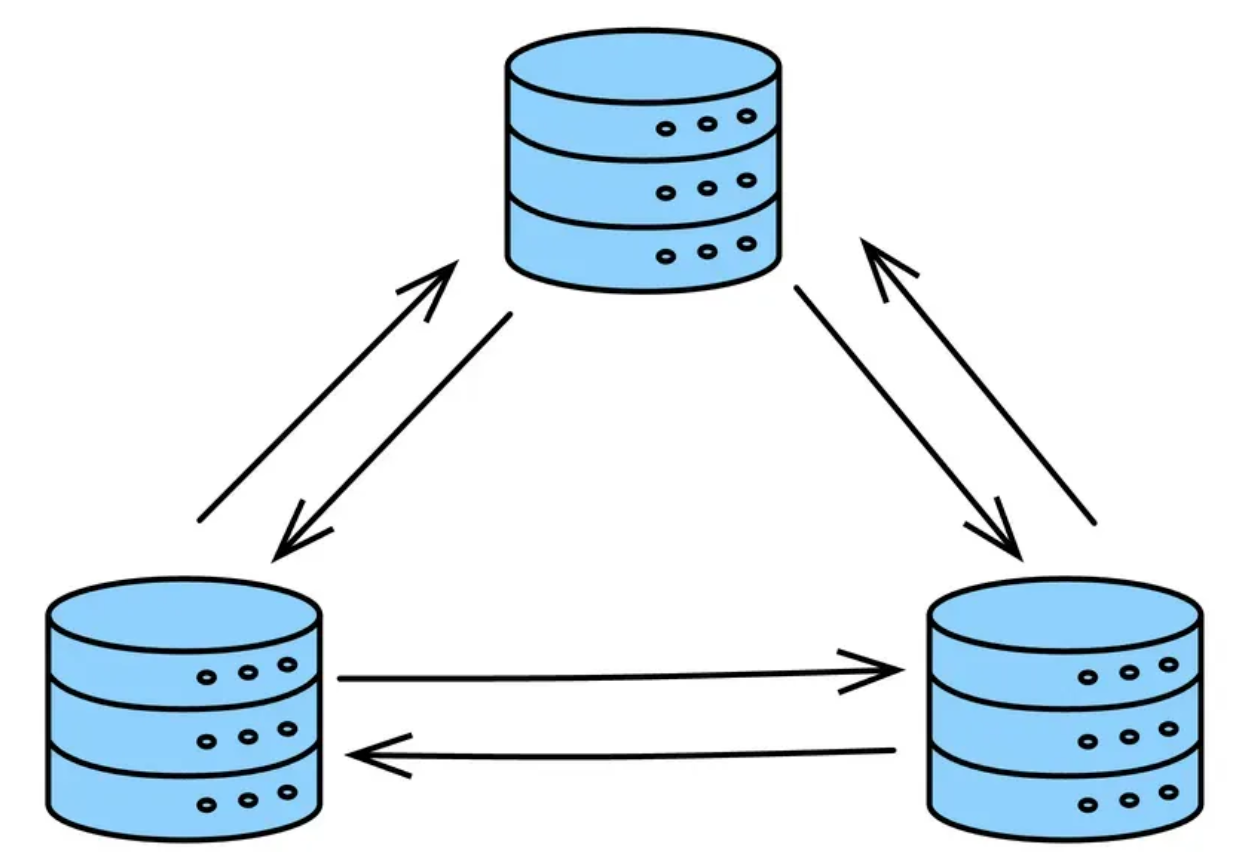
三种常见的冗余策略:
-
服务器冗余:部署多台服务器来处理请求,确保如果一台服务器出现故障,其他服务器可以继续提供服务。
-
数据库冗余:创建一个副本数据库,当主数据库发生故障时,该副本数据库可以接管主数据库。
-
地理冗余:将服务和数据库等部署在多个地理位置,以减轻区域性故障的影响。
2.负载均衡
负载均衡将请求流量尽可能均衡的分配到多台服务器,以确保没有任何一台服务器成为瓶颈,从而提高系统的性能和可用性。
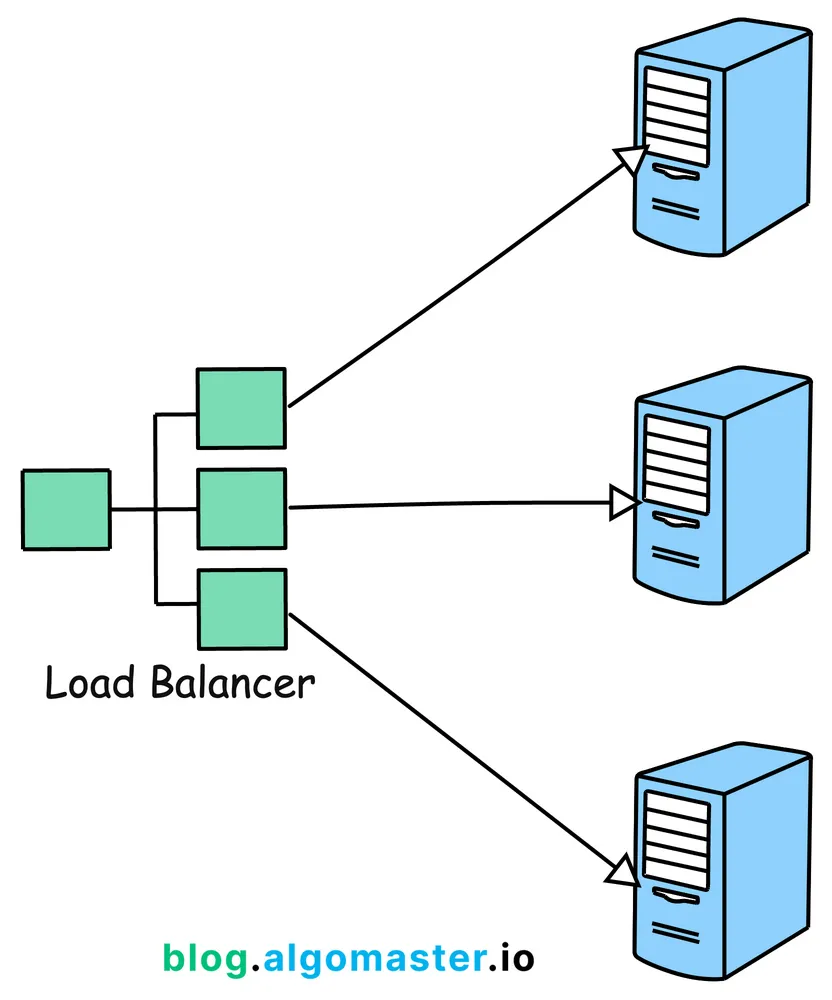
常用的负载均衡器:
-
硬件负载均衡器:硬件负载均衡器是一种专用的物理设备,用于根据预设的规则来分配请求流量。
-
软件负载均衡器:管理流量分配的软件解决方案,例如 HAProxy、Nginx 或基于云的解决方案(如 AWS Elastic Load Balancer)。
3.故障转移机制
故障转移机制是一种系统设计策略,用于在主要系统组件(如服务器、数据库、网络等)出现故障时,自动将工作负载转移到备用组件,以确保服务的连续性和稳定性。通俗地说,这种机制确保了系统在出现问题时不会“崩溃”,而是迅速切换到另一个正常的部分继续工作。例如Redis的 sentinel架构就实现了故障自动转移。
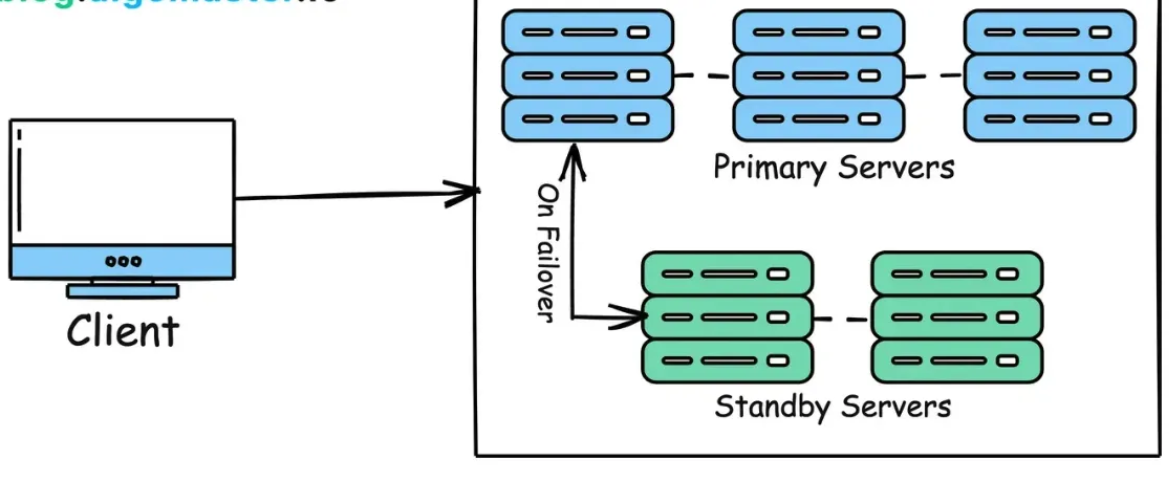
故障转移机制的关键步骤:
-
监控:监控持续监控主服务器的状态,检查它是否正常工作。通常,这通过定期的健康检查和心跳信号完成。
-
故障检测:当监控系统发现主服务器出现故障(比如无法响应请求或出现错误)时,会立即识别并记录这个问题。
-
故障转移:监控系统自动将流量或请求转移到备用服务器上,确保服务的连续性。
-
恢复:当主服务器问题解决并恢复正常时,系统可以将流量重新转回到主服务器上。
可以看出故障转移机制通常需要一个监控系统来有效地检测和响应故障,Redis的 sentinel架构中,sentinel节点就充当了这个监控系统的角色。
4.数据复制
复制是将数据从一个地方复制到另一个地方的过程。这样做的目的是为了提高数据的可用性和安全性。
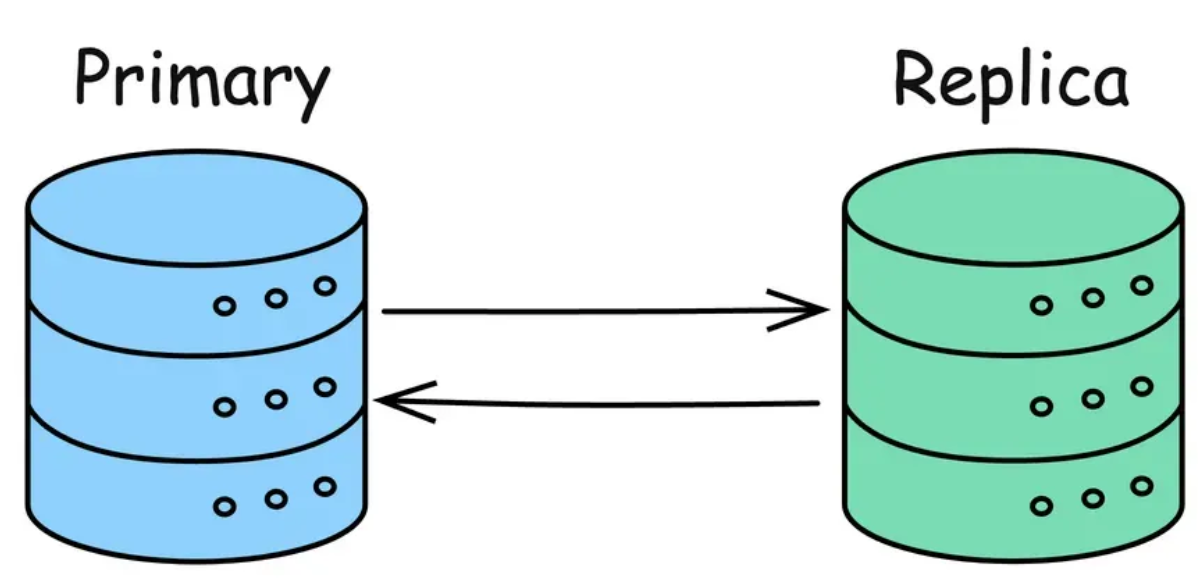
数据复制方式:
-
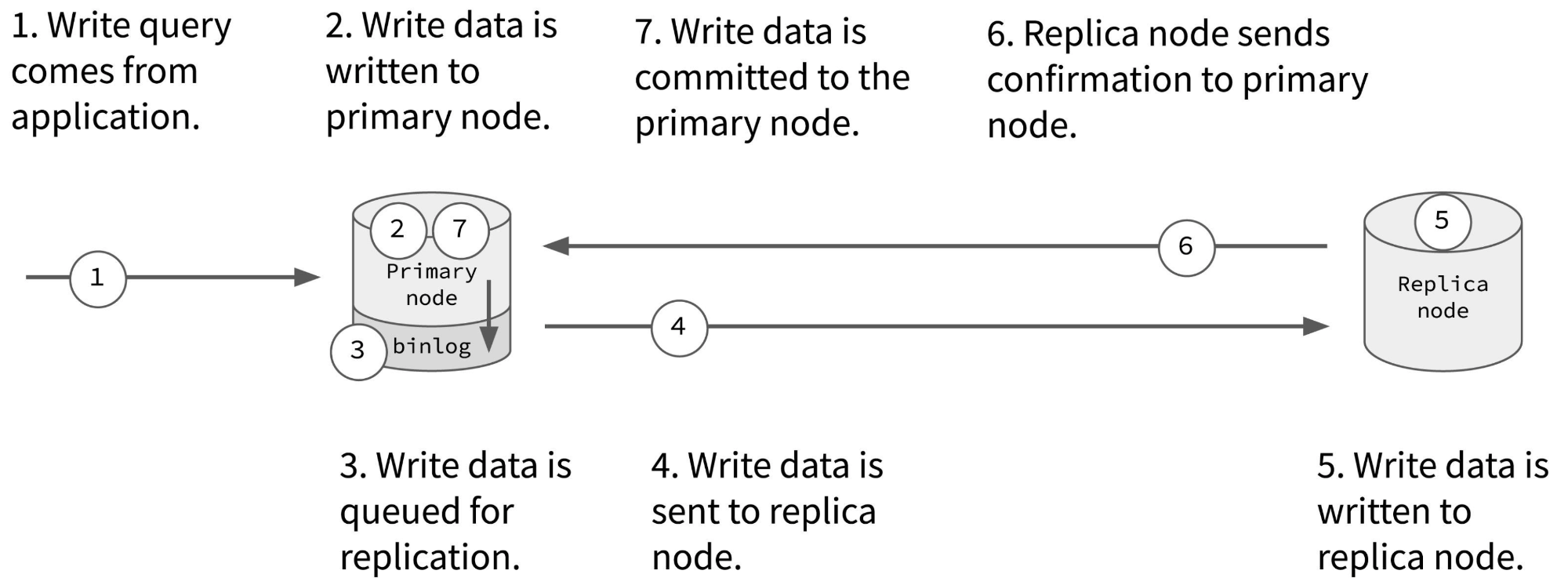
同步复制:在同步复制中,一旦主节点更新了其自身的数据,它会将数据更新操作同步给从节点:从节点接收数据更新操作并执行更新,更新成功后将确认发送给主节点。一旦主节点收到所有从节点的确认,它才会响应客户端,整个数据更新过程才算成功。
-
异步复制:主节点在更新完其自身的数据后就立即响应客户端,而无需等待更新操作传播到从节点。

同步复制确保从节点始终与主节点保持数据同步和一致,但是性能较差(需要所有从节点更新完成),适用于对数据一致性要求非常高的场景,比如金融系统或订单管理系统,虽然性能会有所牺牲。
异步复制效率高,但是数据一致性得不到保证,并且可能丢数据,适用于对性能要求高但对数据一致性要求稍低的场景,比如社交媒体应用或内容分发网络,这种方式可以提供更快的响应速度。
5. 监控和警报
监控和警报是确保系统运行顺畅、及时发现和解决问题的关键手段。它们帮助你在问题变得严重之前识别并修复故障。
监控手段:
-
心跳信号:组件之间定期发送信号以检查其状态。
-
健康检查:定期用脚本或工具对系统组件进行检测,以确保它们正常运行。这些检查会自动执行,类似于定期的体检,确保系统没有潜在的问题。
-
警报系统:警报系统是当系统检测到问题时通知相关人员的工具。例如,PagerDuty 或 OpsGenie 等工具会在检测到故障时立即发出通知,告诉系统管理员或技术支持团队需要解决问题了。
高可用性最佳实践
1. 针对故障进行设计
设计系统时,要假设系统中的任何组件都可能随时发生故障。也就是说,系统应该能应对意外情况,避免因为一个组件的失败导致整个系统崩溃。
想象你是一个建筑师,你正在建造一座桥,你不应只是考虑桥的正常使用,还要考虑万一桥的某部分损坏了,应该做些什么预防,让其他部分能否支撑交通。
2. 实施健康检查
定期检查系统组件的健康状况,以便在问题变成严重故障之前发现并解决它们。健康检查可以帮助你及时发现系统中的潜在问题。
就像你定期去体检来确保身体健康一样,系统的健康检查会定期监测各个服务的运行状态,及时发现潜在的问题,例如服务器是否运行正常或数据库是否响应。
3. 使用多个可用区域
将系统部署在不同的地理位置的数据中心,以防止局部故障。例如,某个数据中心发生了停电,其他数据中心仍然可以提供服务,从而避免整个系统的崩溃。
4. 实践混沌工程
测试时故意引入一些故障(例如关闭某个服务)来测试系统的弹性。这样做的目的是确保系统能在面对意外问题时正常工作。
例如在一座新建的桥上进行车流测试,即使桥梁在正常情况下能够承载车辆,测试时还要故意增加超载,确保桥梁在极端情况下仍能安全运行。
5. 实施断路器
快速切断出现问题的服务,以防止问题扩散到其他部分,避免引发更大的系统故障。断路器能在服务出现问题时及时采取措施,保护整体系统的稳定性。
就像电路中的断路器,如果发现电流过大,断路器会自动切断电流,防止电路过载引发火灾。软件系统中的断路器也会在服务出现问题时及时“断开”,避免影响其他部分。
6. 明智地使用缓存
使用缓存将常用的数据存储在快速访问的地方,从而减少对后端系统的负载,提高系统的响应速度和可用性。
7. 做好容量的合理规划
确保系统能够处理预期的负载增加,并且对突发流量做好准备。容量规划帮助你预见未来的需求变化,避免系统因为负荷过重而崩溃。
















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









