







在分布式系统中,数据通常分布在多个服务器或数据库中,而这些服务器之间可能位于不同的地理位置,因此分布式系统具有可扩展性和容错性等优点。
然而当系统需要处理写入操作(如更新、删除数据)时,如何确保所有服务器上的数据保持一致,成为一个重要的问题。这就是一致性模型要解决的。
分布式系统中存在多种一致性模式,大致可分为以下几类:
- 强一致性
- 最终一致性
- 弱一致性
强一致性模型(Strong Consistency)
强一致性模型可以保证每次读操作都能读取到最新的写入结果。简单来说,就是无论在什么时候读取数据,都能获取到该数据的最新值。
强一致性系统的数据复制流程如下图所示:
- 应用服务器向主数据库(primary)写入数据。
- 主数据库将数据写入的操作同步到从数据库(replica)。
- 从数据库更新完成后响应给主数据库。
- 主数据库返回写操作成功给应用服务器。
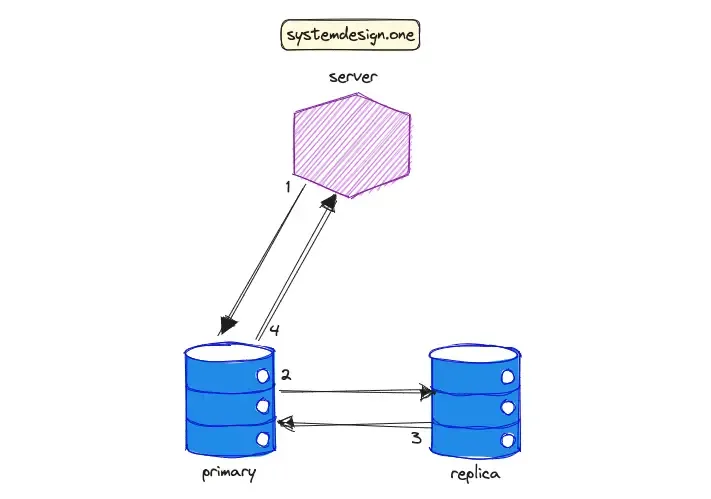
可以看出,在强一致性模型下,每次写操作必须确保当数据在所有副本上都更新完毕,系统才会确认写操作成功。
强一致性模型提供最高的数据一致性,但是会带来更高的延迟,系统性能可能会受到影响,因为需要确保所有节点的数据同步完成。适合用于对性能要求不高,但是对数据一致性要求很高的场景。例如,金融交易系统中账户余额必须是最新的,不能有任何不一致。Google 的Bigtable和 Spanner数据库也是强一致性的实际应用。
弱一致性模型(Weak Consistency)
在弱一致性模型下,系统不保证写入操作后数据在所有副本中一致,甚至可能永远不一致(这是和最终一致性的区别,最终一致性可以保证数据最终会达到一致的状态)。
弱一致性系统的数据复制流程如下图所示:
- 服务器将数据写入缓存。
- 缓存立即返回写入成功给服务器。
- 缓存系统将写入的数据异步地推送到消息队列。
- 消息队列中的数据被依次写入到数据库。
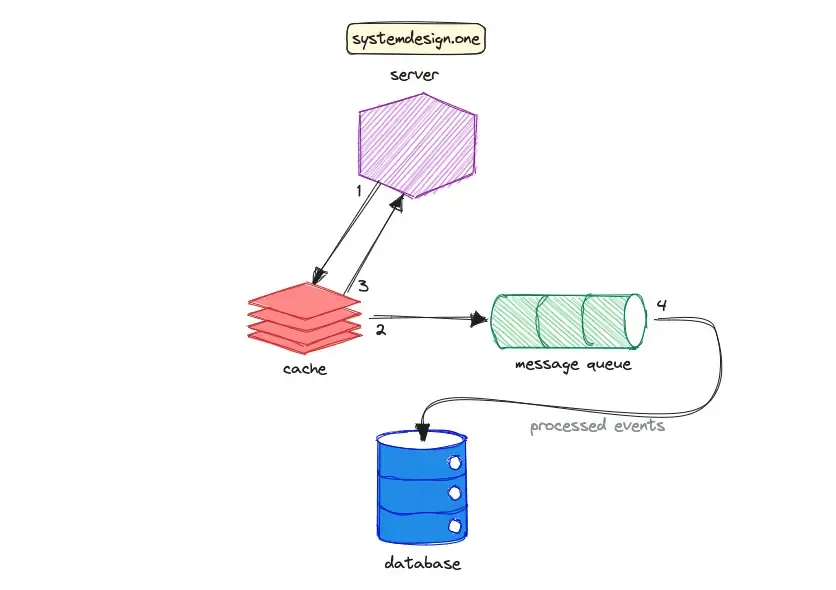
强一致性模型提供了最高的性能,但是可能会产生数据的不一致性问题,适合对数据一致性要求不高的场景,例如:
-
数据分析平台:在大数据分析平台上,数据可能会被分布在多个节点进行处理。由于数据量巨大,系统可能不会保证所有节点上的数据都是一致的,只要最终的分析结果不受影响,短暂的或部分节点的数据不一致是可以接受的。
-
实时流处理:在实时数据分析或流处理系统中,可能并不需要每一条数据都严格同步。例如,在一个在线广告系统中,不同用户可能会看到不同的广告展示,即使在短时间内广告数据不同步,这对系统的整体性能和收益影响不大。
最终一致性模型(Eventual Consistency)
在最终一致性模型下,系统在接受写操作时不会等待所有副本都更新完毕,而是立即返回成功结果。数据会在后台逐步同步到所有副本,最终达到一致。
最终一致性系统的数据复制流程如下图所示:
- 服务器向主数据库(primary)写入数据。
- 主数据库写入成功后,立即返回成功响应给服务器。
- 主数据库在后台异步地将数据同步到从数据库(replica)。
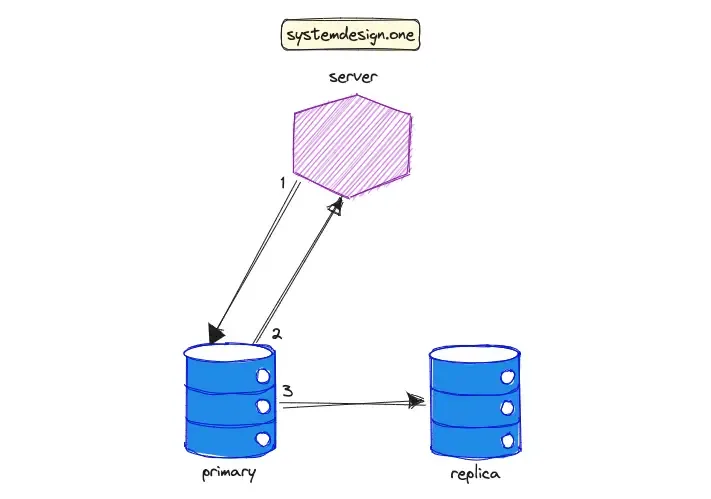
最终一致性模型允许系统在写操作后,数据副本之间存在短暂的不一致,但最终(通常在几秒或几分钟内)会达到一致性。
这种模型适用于对写操作的实时性要求较高,并且对数据一致性有一定要求的场景,例如:
-
在社交媒体平台上,如微信或Facebook,用户发布的状态更新不一定会立即在所有用户的设备上显示。这种延迟是可以接受的,因为几秒钟或几分钟的延迟并不会影响用户体验。最终一致性模型允许系统在性能和一致性之间找到一个平衡点。
-
社交媒体平台中用户点赞或评论可以在短时间内不同步,这个场景就非常适合最终一致性模式。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









