







在之前的文章中,介绍了Apache Kafka的重平衡协议是如何工作的。从Kafka消费者的角度来看,这个协议是用来协调如何给同一消费者组的不同消费者之间分配主题分区的。
这个协议的一个关键点是,作为开发人员,我们可以嵌入自己的分区策略来定制如何将分区分配给组成员。
对于 Kafka 消费者,分区策略决定了如何将主题中的分区分配给消费者组中的不同消费者实例。这种策略是在重新平衡(rebalance)期间生效的。
在这篇文章中,我们将看到Kafka消费者可以配置哪些分区策略以及如何编写一个自定义的分区策略。
PartitionAssignor策略
在创建新的Kafka消费者时,我们可以设置分区策略,分配策略可以通过属性partition.assignment.strategy进行配置。
以下代码片段展示了如何指定一个分区策略:
Properties props = new Properties();
...
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//...
注意:属于同一消费者组的所有消费者必须指定相同的分区策略。如果一个消费者试图以与其组内其它消费者不一致的分区策略加入组,您将会看到以下异常:
org.apache.kafka.common.errors.InconsistentGroupProtocolException: The group member’s supported protocols are incompatible with those of existing members or first group member tried to join with empty protocol type or empty protocol list.
一个分区策略就是一个实现了PartitionAssignor接口的类。
Kafka客户端提供了三种内置的分区策略:RangeAssignor、RoundRobinAssignor和StickyAssignor。
RangeAssignor
RangeAssignor 是 Kafka 消费者的默认分区分配策略。它的主要目的是在处理多个主题时,确保相同编号的分区能够分配给同一个消费者。这在某些场景下非常有用,例如,当你有两个主题,它们的分区数量相同,并且它们的消息是基于相同的键进行分区的。
具体而言,这种策略会按照以下步骤进行分区分配:
- 排序消费者:首先,RangeAssignor 会根据代理协调器分配的 member_id 对所有消费者进行字典顺序排序。
- 排序分区:接下来,它会按数字顺序排列可用的主题分区。
- 分配分区:最后,从第一个消费者开始,按照顺序为每个消费者分配分区。这样,同一个消费者会同时接收到来自不同主题的相同编号的分区。例如,主题 A 和主题 B 的分区 0 都会被分配给同一个消费者。
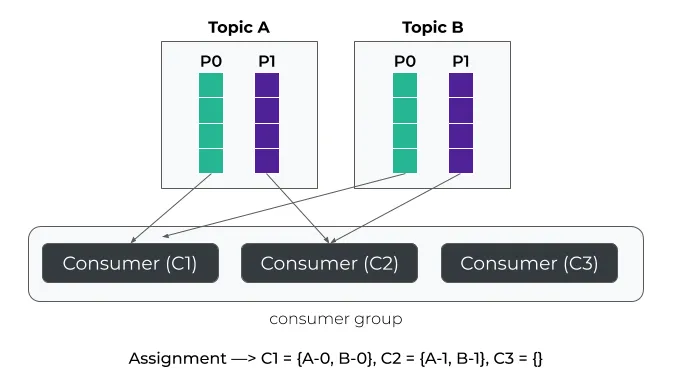
如上图所示,主题A和B的分区0被分配给同一个消费者,注意这里只有两个消费者分配到了分区,因为这两个主题都只有两个分区。可以看出,在特定条件下(主题分区数量少于消费组消费者数量)这种分区策略导致了消费者资源的浪费。
RoundRobinAssignor
RoundRobinAssignor可用于在所有消费者之间均匀分配可用分区。与之前一样,分配器将在分配每个分区之前按字典顺序排列分区和消费者,然后逐个分配分区,确保每个消费者尽可能均匀地分配到分区。
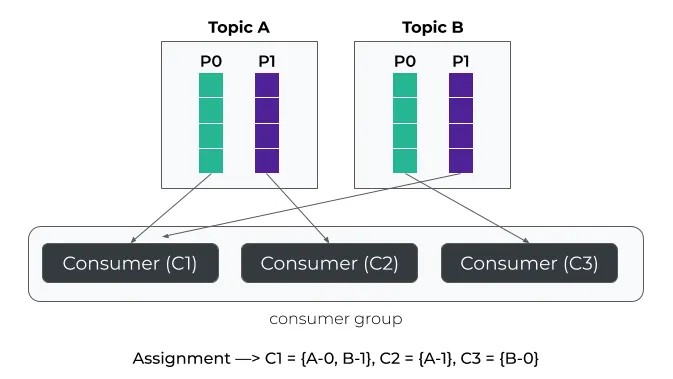
尽管RoundRobin分区策略最大化使用了消费者,但是它也有一个主要缺点:当消费者数量发生变化(例如,某个消费者离开或加入时导致重新平衡),RoundRobinAssignor 不会尝试减少分区的重新分配。
为了说明这种行为,让我们将消费者2从消费组中移除。在这种情况下,分区B-1从C1撤销并重新分配给C3。同时,分区B-0从C3撤销并重新分配给C1。其实理想的情况,直接将原本分配给消费者2的分区A-1分分配给消费者C效率是最高的。
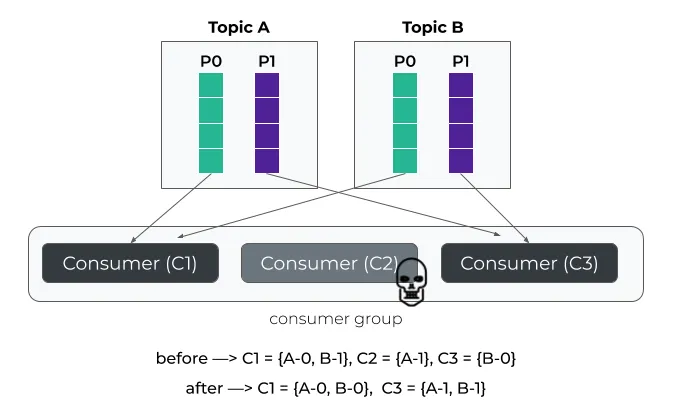
这些不必要的分区移动会导致额外的性能开销,进而影响消费者的整体性能。
StickyAssignor
StickyAssignor与RoundRobin非常相似,不同之处在于它会尝试在两次分配之间最小化分区移动,同时确保均匀分布。
使用前面的示例,如果消费者C2离开消费组,则只有分区A-1的分配会更改为C3。
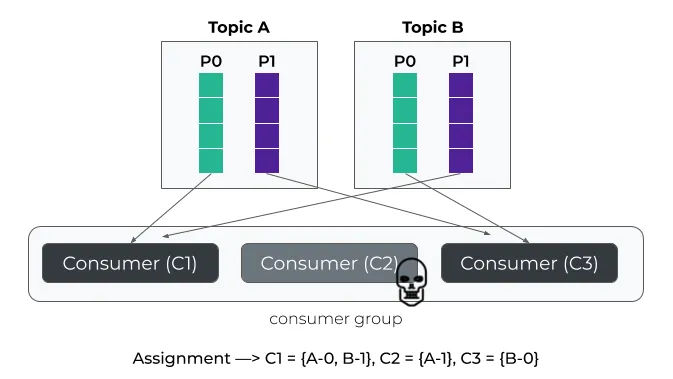
这种方式可以减少由于分区移动导致的额外开销,进而提高消费者的整体性能。
StreamsPartitionAssignor
Kafka Streams 自带了StreamsPartitionAssignor。它用于跨应用程序实例分配分区,
通常,前面介绍的三种基本分配器适可以满足大多数业务需求。然而,您可能有特定的业务场景,可能需要开发人员根据具体需求实现自定义的分配策略。
实现自定义策略就是实现PartitionAssignor接口,下面让我们看看如何实现PartitionAssignor接口。
实现自定义分区策略
PartitionAssignor接口
PartitionAssignor并不复杂,只有四个主要方法。
public interface PartitionAssignor {
Subscription subscription(Set<String> topics);
Map<String, Assignment> assign(
Cluster metadata,
Map<String, Subscription> subscriptions);
void onAssignment(Assignment assignment);
String name();
}
当启动一个Kafka消费者并订阅一个或多个主题时,Kafka消费者客户端会调用PartitionAssignor的subscription方法来创建订阅信息。
然后,消费者组的leader(即组内的一个消费者)会接收到所有消费者的订阅信息,并通过 assign() 方法来执行分区分配。
接下来,所有消费者将从leader那里接收他们的分配,并且每个消费者都会调用onAssignment()方法来处理分配的分区,通常用于更新内部状态。
最后,PartitionAssignor必须被分配一个唯一的名称,由name()方法返回(例如“range”或“roundrobin”或“sticky”)。
注意这些方法不需要我们在代码中显示调用,它们是在Kafka消费者组重平衡过程中由Kafka内部机制自动调用的。我们的任务是根据需要实现这些方法。
自定义FailoverAssignor策略
使用默认的分区器,消费组中的所有消费者都可以被分配到分区。我们可以将这种策略比作一种主动/主动模型,这意味着所有实例都可能同时获取消息。
但是,对于某些生产场景,可能需要执行主动/被动消费。。在这种情况下,我建议您考虑使用 FailoverAssignor 策略,这种策略在其他消息传递解决方案中也广泛应用。
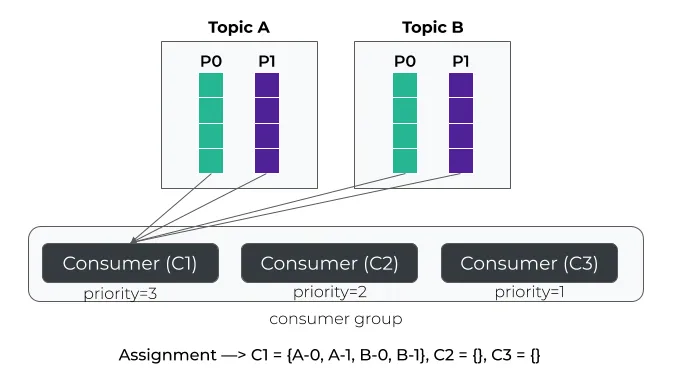
故障切换策略的基本思想是多个消费者可以加入同一组。然而,所有分区在同一时间只分配给一个消费者。如果该消费者失败或停止,则所有分区都分配给下一个可用消费者。通常,分区分配给第一个消费者,但在我们的示例中,我们将为每个实例附加一个优先级。因此,具有最高优先级的实例将优先于其他实例。
下面用一个例子来说明这个策略。在这个例子中,C1具有最高优先级,因此所有分区都分配给它。
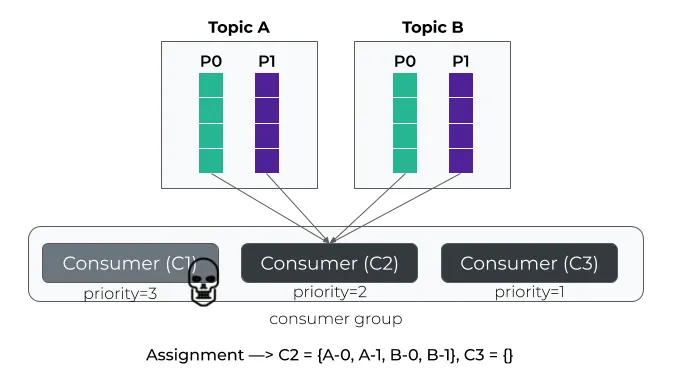
如果该消费者失败,则所有分区都分配给下一个消费者(即C2)。
实现
首先,让我们创建一个新的Java类,名为FailoverAssignor。我们将继承抽象类AbstractPartitionAssignor而不是直接实现PartitionAssignor接口。
AbstractPartitionAssignor这个类已经实现了assign(Cluster,Map<String, Subscription>)方法,并实现了获取每个订阅主题可用分区的逻辑。除此之外,它还声明了几个我们必须实现的抽象方法。
Map<String, List<TopicPartition>> assign(
Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions);
但在此之前,我们需要进行FailoverAssignor配置,以便我们可以为每个消费者分配优先级。幸运的是,Kafka提供了接口Configurable,我们可以实现该接口以获取客户端配置。
到目前为止,完整的代码如下:
public class FailoverAssignor extends AbstractPartitionAssignor implements Configurable {
@Override
public String name() {
return "failover";
}
@Override
public void configure(final Map<String, ?> configs) {
// TODO
}
@Override
public Subscription subscription(final Set<String> topics) {
// TODO
}
@Override
Map<String, List<TopicPartition>> assign(
Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
// TODO
}
}
在上面的代码中,configure方法在FailoverAssignor实例初始化后由KafkaConsumer调用。
为了遵循Kafka的编码约定,我们将创建名为FailoverAssignorConfig的第二个类,它继承通用类AbstractConfig,这个类将处理 FailoverAssignor 的配置逻辑,确保每个消费者都能根据配置获取其优先级:
public class FailoverAssignorConfig extends AbstractConfig {
public static final String CONSUMER_PRIORITY_CONFIG = "assignment.consumer.priority";
public static final String CONSUMER_PRIORITY_DOC = "The priority attached to the consumer that must be used for assigning partition. " +
"Available partitions for subscribed topics are assigned to the consumer with the highest priority within the group.";
private static final ConfigDef CONFIG;
static {
CONFIG = new ConfigDef()
.define(CONSUMER_PRIORITY_CONFIG, ConfigDef.Type.INT, Integer.MAX_VALUE,
ConfigDef.Importance.HIGH, CONSUMER_PRIORITY_DOC);
}
public FailoverAssignorConfig(final Map<?, ?> originals) {
super(CONFIG, originals);
}
public int priority() {
return getInt(CONSUMER_PRIORITY_CONFIG);
}
}
现在,configure()方法可以简单地实现如下:
public void configure(final Map<String, ?> configs) {
this.config = new FailoverAssignorConfig(configs);
}
接下来,我们需要实现subscription()方法,此方法的作用是将消费者订阅的主题以及它的优先级信息打包成一个订阅对象(Subscription),并将该对象传递给 Kafka 的分区分配策略,以便在故障转移时根据优先级来分配分区。
@Override
public Subscription subscription(final Set<String> topics) {
ByteBuffer userData = ByteBuffer.allocate(4)
//将消费者的优先级(config.priority())放入缓冲区中。
.putInt(config.priority())
//调用 flip() 方法是为了将缓冲区从写模式切换到读模式,这样缓冲区中的数据可以被读取和传输。
.flip();
return new Subscription(
//将订阅的主题集合转换为一个列表。
new ArrayList<>(topics),
ByteBuffer.wrap(userData)
);
}
接下来,我们可以实现assign()方法,它是一个分区分配器的核心逻辑:
//partitionsPerTopic: 一个 Map,键是主题名,值是该主题的分区数量。
//subscriptions: 一个 Map,键是消费者的 memberId,值是消费者的订阅信息(Subscription 对象)。
@Override
public Map<String, List<TopicPartition>> assign(
Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
// 使用每个订阅主题的分区数生成所有主题分区。
final List<TopicPartition> assignments = partitionsPerTopic
.entrySet()
.stream()
.flatMap(entry -> {
final String topic = entry.getKey();
final int numPartitions = entry.getValue();
//生成从 0 到 numPartitions-1 的整数流,代表每个分区的编号。
return IntStream.range(0, numPartitions)
//将每个分区编号与主题名结合,生成一个 TopicPartition 对象。
.mapToObj( i -> new TopicPartition(topic, i));
//将所有的 TopicPartition 对象收集到一个列表中,表示所有主题的所有分区。
}).collect(Collectors.toList());
// 从每个订阅中解码消费者优先级
Stream<ConsumerPriority> consumerOrdered = subscriptions.entrySet()
.stream()
.map(e -> {
int priority = e.getValue().userData().getInt();
String memberId = e.getKey();
return new ConsumerPriority(memberId, priority);
})
.sorted(Comparator.reverseOrder());
// 选择优先级最高的消费者
ConsumerPriority priority = consumerOrdered.findFirst().get();
final Map<String, List<TopicPartition>> assign = new HashMap<>();
subscriptions.keySet().forEach(memberId -> assign.put(memberId, Collections.emptyList()));
assign.put(priority.memberId, assignments);
return assign;
}
最后,我们可以像下面这样使用自定义分区器:
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, FailoverAssignor.class.getName());
props.put("assignment.consumer.priority", 100);
根据消费者配置的优先级,协调器将在消费组成员之间分配分区。
补充:AbstractConfig类
AbstractConfig类是Kafka配置框架的基础类,用于处理Kafka中各种组件的配置。这个类提供了一种方便的方法来管理配置参数,包括解析、验证和提供默认值。通过继承AbstractConfig类,开发人员可以定义自己所需的配置。
假设你要创建一个自定义的Kafka生产者配置类,通过继承AbstractConfig类并定义自己的配置参数。
以下是一个示例,展示如何创建一个自定义的Kafka生产者配置类MyProducerConfig。
public class MyProducerConfig extends AbstractConfig {
// 定义配置参数
public static final String MY_PARAM_CONFIG = "my.param";
private static final String MY_PARAM_DOC = "This is my custom parameter";
private static final String MY_PARAM_DEFAULT = "default_value";
public MyProducerConfig(Map<String, ?> originals) {
super(configDef(), originals);
}
// 定义配置规范:使用ConfigDef定义配置参数的类型、默认值、重要性和描述。
private static ConfigDef configDef() {
return new ConfigDef()
.define(MY_PARAM_CONFIG, ConfigDef.Type.STRING, MY_PARAM_DEFAULT, ConfigDef.Importance.HIGH, MY_PARAM_DOC);
}
// 提供获取配置参数的方法
public String getMyParam() {
return this.getString(MY_PARAM_CONFIG);
}
public static void main(String[] args) {
// 示例配置参数
Map<String, String> configMap = Map.of(MY_PARAM_CONFIG, "my_value");
// 创建配置实例
MyProducerConfig config = new MyProducerConfig(configMap);
// 获取并打印配置参数
System.out.println("My Param: " + config.getMyParam());
}
}
















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









