







一、巧用索引
- 一般索引
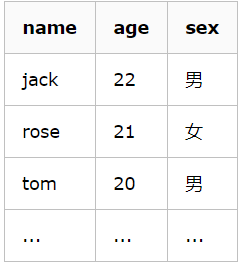
假设我们有一个用户表 tb_user,内容如下:
执行SQL语句:
SELECT name FROM tb_user WHERE age = 20;
默认情况下,MySQL需要遍历整张表,才能找到符合条件的记录。如果在age字段上建立索引,那么MySQL可以很快找到所有符合条件的记录(索引本身通过B+树实现,查起来很快。简单起见,想象一下二分查找和遍历查找的区别。)
- 1 用冗余的联合索引加速查询
SELECT name FROM tb_user WHERE age = 20;
接着上面的例子,我们假设,tb_user表有一百万行,通常情况下,"WHERE age = 20"这样的语句,会返回几万行数据,实际测试下发现,速度不够快。
原因是,MySQL根据索引查询到符合条件的记录后,还需要到表空间里一一查找这些记录(实际上,索引里同时记录了age字段和关联记录的物理行号),这意味着,MySQL必须读取表空间多达几万次,才能返回最终结果。
但是 ,如果age字段的索引上有name字段的值话,MySQL就不用再费事地去访问表空间了。
最终解决方案:
建立联合索引,让MySQL直接从索引中取出name字段的值
ALTER TABLE tb_user ADD INDEX age_with_name(`age`,`name`)
注意这里的顺序,必须是先age后name,反之不行(除非你是根据name查age)。
2.2 用冗余的联合索引加速排序
依然是之前的表,假设要做这样的查询:
SELECT * FROM tb_user ORDER BY age;
因为我们在age上有索引,所以排序是很快的(索引的本质就是将表记录的物理行号按照特定规则排序)
但在实际项目中,SQL可能比这个复杂些,比如:
SELECT * FROM tb_user WHERE sex='男' ORDER BY age;
这个时候,age字段上的索引就派不上用场了。因为,此时是在排序,筛选后的表和age索引是对应不上的。
解决方案:
依然是联合索引
ALTER TABLE tb_user ADD INDEX age_with_name(`sex`,`age`)
这个联合索引,同时记录了sex和age,并且排序的规则是,先按sex排,sex相同时按age排。那么,通过"WHERE sex=‘男’",筛选后剩下的索引还是按照age排序。因此,整个SQL的排序速度依然很快。
.
.
,
.
.
二、Limit语句优化
假设有如下SQL语句:
SELECT * FROM tableName LIMIT offset, rows
这是一条典型的LIMIT语句,他表示对此时表内下标为offset的行(Mysql下标由0开始)开始选取rows条数据,常见的使用场景一般是:某些查询返回的内容特别多,而处理能力有限,希望每次只取一部分结果进行处理。
该语句实现的机制:
- 从表中直接从第一条开始读取offset+rows条数据
- 抛弃前offset条数据,最后rows条作为查询结果
显然这样一来,比如我们需要从10000行开始选取10条数据,那么他会直接查询10010条数据,这样的效率必然是相当低下的,可以这么说:limit查询的效率取决于offset的大小,offset大的情况下查询效率低
(1)对于简单查询的Limit语句优化
当需要查询的数据范围是按主键自增的
优化前:
SELECT * FROM message LIMIT 998000,1000
SELECT * FROM message LIMIT 999000,1000
优化后:
SELECT * FROM message WHERE uid>998000 LIMIT 1000
SELECT * FROM message WHERE uid>999000 LIMIT 1000
在这种情况下,因为查询的结果是按主键排列的,因此直接用where条件限定主键,后LIMIT 1000条数据即可,这种方法利用了索引,定位到offset的速度非常快
(2)对于复杂查询的Limit语句优化
那么当我们要查询的结果并不是按主键自增的呢?比如,多表查询、条件查询。这种情况下,查询结果通常不是按照自增主键的顺序逐一排列的。
例如:在下面这个例子中,查询的结果和主键顺序无关
SELECT * FROM student WHERE score >60 LIMIT 999000,1000;
优化方案:将条件下所有数据插入临时表,临时表内含有自增的主键,这样的话就可以照样用(1)中的方法对数据用LIMIT ROWS快速提取
建立临时表
CREATE TEMPORARY TABLE tmp_student(
`uid` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
'score' int(3) NOT NULL,
PRIMARY KEY (`uid`))
插入至临时表
INSERT INTO tmp_student
SELECT null,name,score FROM student
WHERE score >60;
分多次查询临时表
SELECT * FROM tmp_student where uid > 0 LIMIT 1000
……
SELECT * FROM tmp_student where uid > 999000 LIMIT 1000
避免了offset的使用后,这样查询下每一条都能保证微秒级的速度















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









