







简介:XSL是一种用于转换XML文档的样式表语言,通过ECNU提供的PPT资源,学习者可以深入理解XSL的核心概念、组成以及转换技术。教程详细介绍了XSLT、XPath和XML解析器的使用,并通过实例和进阶话题加深理解。这些资料包括XSL基本概念、组成元素、XSLT和XPath语法、输出方法及实例分析,以及XML解析器的类型和使用方法。此外,还包括一份可能的学习指南或习题解答,助力学生巩固所学知识,提升XML处理能力。 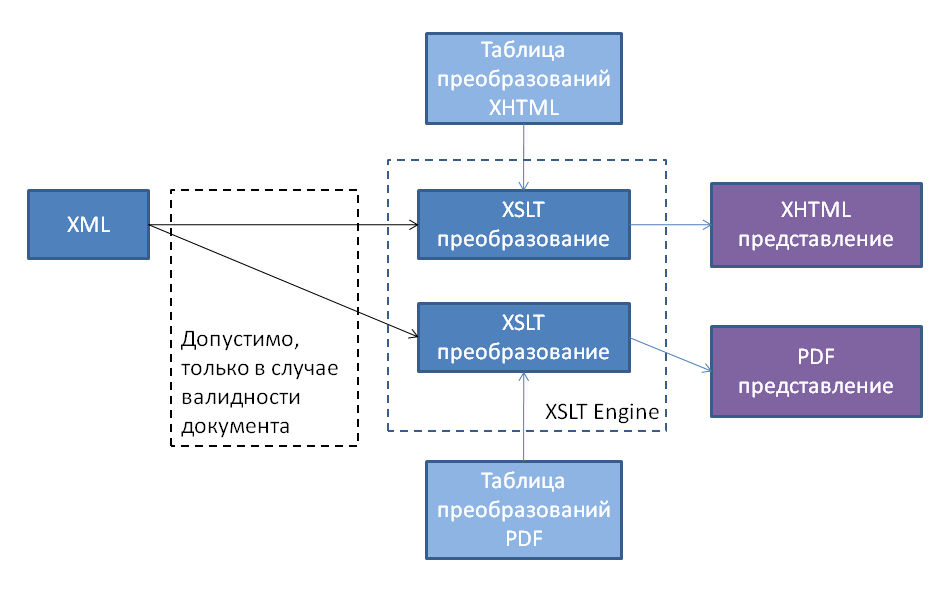
1. XSL基本概念及转换应用
XSL(Extensible Stylesheet Language)是一种用于转换和格式化XML文档的语言。它是XML技术的重要组成部分,广泛应用于各种基于XML的数据交换和呈现。本章将介绍XSL的基础知识,以及如何应用XSL来转换XML文档。
XSL的基本概念
XSL的概念涉及以下几个方面:
1.1 XSL的定义
XSL是用于描述如何展示XML文档样式的语言。它不仅可以定义文档的视觉布局,还能指定数据的结构化表示,从而实现从一种形式的XML到另一种形式或非XML格式的转换。
1.2 XSL转换的应用场景
XSL转换(XSLT)广泛应用于Web内容发布、数据交换和系统集成等领域。它允许开发者将XML文档转换为HTML、PDF或其他XML文档,适应不同的阅读器或显示设备。
1.3 XSL转换的工作原理
XSL转换的核心是将源XML文档的结构映射到目标文档的结构。这通过定义一系列转换规则来实现,规则基于XML文档中定义的模式(Schema)或文档类型定义(DTD)。
本章为读者提供了XSL的初步概念,以及转换应用的基础知识。在后续章节中,我们将深入探讨XSL的组成部分、语法、高级功能和实际应用,从而全面掌握XSL技术的使用。
2. XSL组成:XSLT、XSL-FO、XPath
XSL(Extensible Stylesheet Language)是一组用于定义XML文档如何转换为其他格式的语言规范。它包括三个主要部分:XSLT(XSL Transformations)、XSL-FO(XSL Formatting Objects)和XPath。这一章,我们将深入了解XSLT、XSL-FO和XPath的角色、结构和使用场景。
2.1 XSLT的定义和作用
XSLT是用于转换XML文档的语言。通过XSLT,开发者可以定义一套规则,把原始XML文档转换成HTML、PDF、另一种XML或其他文本格式。
2.1.1 XSLT的角色和转换流程
XSLT的核心是模板。一个模板定义了当文档中的节点与特定模式匹配时,应该如何转换这些节点。转换流程通常包含以下步骤:
- 解析原始XML文档。
- 应用XSLT样式表,根据定义的模板规则匹配节点。
- 将匹配到的节点转换为新的格式。
- 输出转换结果到目标文档。
2.1.2 XSLT与其他XSL组件的关系
XSLT与XSL-FO、XPath紧密协作,共同构建XSL的功能。XPath用于在XML文档中导航和定位数据,而XSL-FO则专注于如何格式化这些数据。因此,XSLT可以视为连接XSL-FO与XPath的桥梁,它使用XPath表达式来选择需要转换的节点,并借助XSL-FO来格式化输出结果。
2.2 XSL-FO格式化文档
XSL-FO允许开发者详细地定义XML文档的布局和格式。它包含了大量用于指定页面尺寸、边距、字体、颜色等属性的元素。
2.2.1 XSL-FO的基本结构和组成元素
XSL-FO文档由三个主要部分组成:布局结构、格式化对象和属性。其中:
- 布局结构定义了文档的整体布局。
- 格式化对象定义了内容的视觉表示,如块级对象、内联对象等。
- 属性定义了对象的具体样式,比如字体大小、颜色等。
2.2.2 XSL-FO在文档排版中的应用实例
假设要为一份报告生成PDF格式,可以使用XSL-FO来指定页面大小为A4,设置双列布局,定义一个页眉和页脚,以及一个包含报告标题、章节和段落的正文区域。通过特定的XSL-FO元素和属性,能够控制每个内容部分的位置和格式,从而生成美观的文档。
<fo:page-sequence master-reference="simple">
<fo:flow flow-name="xsl-region-body">
<fo:block font-size="16pt" font-weight="bold" space-after="6pt">
Report Title
</fo:block>
<fo:block>
Chapter 1: <fo:inline font-weight="bold">Introduction</fo:inline>
</fo:block>
<!-- 更多的 fo:block 和其他格式化对象 -->
</fo:flow>
</fo:page-sequence>
2.3 XPath的定位和查询功能
XPath是XSLT和XSL-FO中用于定位和查询XML文档节点的语言。它提供了一套丰富的路径表达式语法,使得能够快速找到需要的元素。
2.3.1 XPath的基本语法和数据类型
XPath使用路径表达式来定位XML文档中的节点。基本语法包括绝对路径和相对路径表达式,以及通配符和轴(axis)的概念。例如:
-
/bookstore/book[1]选取根元素下的第一个book元素。 -
//title[@lang='en']选取所有具有lang属性为"en"的title元素,无论它们在文档中的位置如何。
XPath还定义了数据类型,如节点集、布尔值、字符串、数字和节点类型等。
2.3.2 XPath的节点选择和路径表达式
节点选择和路径表达式是XPath中最为核心的特性之一。它们允许开发者精确地定位XML文档的各个部分。节点选择可以结合条件表达式,从而使得选择更加精确:
/bookstore/book[price>35]/title
此表达式选取bookstore元素下所有价格大于35的book元素,并获取这些book元素的title子元素。
通过对XSLT、XSL-FO和XPath的探讨,我们可以看到XSL技术在XML文档处理中的强大作用。下一章,我们将深入学习XSLT的语法和实际操作技巧,以及在现实场景中的应用案例。
3. XSLT语法详解与实例操作
3.1 XSLT模板的创建和匹配规则
3.1.1 模板匹配的条件和优先级
在XSLT中,模板提供了一种机制,用于定义如何将源XML文档中的数据转换为期望的输出格式。模板匹配基于节点的类型(元素、属性、文本等)和其名称来进行。模板匹配规则可以非常具体,也可以相对模糊。XSLT处理器遵循一组严格的规则来决定哪一个模板与特定的节点匹配。
匹配规则的优先级由具体性决定。具体性较高的规则将覆盖具体性较低的规则。例如,匹配特定元素的模板比匹配任意元素的模板具有更高的优先级。XSLT处理器会遍历所有模板规则,并选择一个最具体的模板应用于给定的节点。
具体性由以下三个因素决定: - 节点类型:例如,元素、属性、处理指令等。 - 节点名称:具体元素的名称或任意名称的通配符。 - 位置:是否匹配节点的祖先、后代或特定层级的子节点。
3.1.2 XSLT中的关键指令和属性
XSLT文档包含一系列的指令和属性来描述转换过程。其中一些关键的包括:
-
<xsl:template>:定义转换模板。 -
<xsl:apply-templates>:应用模板到当前节点的子节点。 -
<xsl:value-of select="expression">:输出选定节点的文本内容。 -
<xsl:for-each select="expression">:对每一个选定的节点执行模板。 -
<xsl:if test="expression">:仅当表达式结果为真时,执行模板。 -
<xsl:choose>、<xsl:when>和<xsl:otherwise>:多重条件语句。
此外,XSLT处理器还支持一些内置的函数,如字符串函数、数值函数、节点集函数等。
代码示例
下面是一个简单的XSLT模板应用实例,其中包含了一些基本的XSLT指令。
<xsl:template match="/books">
<html>
<head><title>Book List</title></head>
<body>
<h1>Book List</h1>
<xsl:apply-templates select="book"/>
</body>
</html>
</xsl:template>
<xsl:template match="book">
<p>
<strong>Title: </strong>
<xsl:value-of select="title"/>
<br/>
<strong>Author: </strong>
<xsl:value-of select="author"/>
<br/>
</p>
</xsl:template>
在这个例子中,首先匹配根节点 <books> 并生成HTML的框架结构,然后使用 <xsl:apply-templates select="book"/> 指令来递归地匹配并应用 <book> 节点的模板。每个 <book> 模板输出其标题和作者信息。这种方式允许XSLT处理器根据XML源文档动态生成所需的输出格式。
3.2 XSLT的高级转换技巧
3.2.1 处理不同数据类型的转换策略
在进行XSLT转换时,可能会遇到不同数据类型的情况,XSLT提供了灵活的方式来处理这些数据。XSLT使用数据类型转换,允许在不同数据类型之间转换,如字符串转换为数字,日期转换为字符串等。
例如,当需要从一个日期节点中提取特定部分(如年份)并进行显示时,可以使用 substring 或 format-date 函数来实现这一转换。又或者在处理数字时,可能需要对其格式进行格式化,比如将浮点数转换为带有两位小数的字符串。
3.2.2 高级XSLT函数和逻辑控制结构
XSLT包含了一系列高级函数和逻辑控制结构,以支持复杂的转换需求。这些包括条件逻辑、循环控制、键和查找表等。
条件逻辑
使用 <xsl:if> 和 <xsl:choose> 指令可以实现条件逻辑判断。 <xsl:if> 适用于单个条件的情况,而 <xsl:choose> 则可以支持多个条件判断。
<xsl:if test="@price > 50">
<span>Expensive Book</span>
</xsl:if>
<xsl:choose>
<xsl:when test="@price > 100">
<span>Very Expensive Book</span>
</xsl:when>
<xsl:when test="@price > 50">
<span>Expensive Book</span>
</xsl:when>
<xsl:otherwise>
<span>Cheap Book</span>
</xsl:otherwise>
</xsl:choose>
循环控制
XSLT利用 <xsl:for-each> 和 <xsl:apply-templates> 来实现循环控制结构。
<xsl:for-each select="authors/author">
<div class="author"><xsl:value-of select="."/></div>
</xsl:for-each>
键和查找表
XSLT中的键(key)是一种非常强大的机制,它允许定义一个查找表,能够基于特定的标识符快速查找节点。键的定义通过 <xsl:key> 指令实现,使用时通过 key() 函数调用。
<xsl:key name="author" match="author" use="@id"/>
<xsl:template match="book">
<div class="book">
<xsl:apply-templates select="key('author', @authorId)"/>
</div>
</xsl:template>
3.3 XSLT的实际应用案例
3.3.1 从简单到复杂的转换案例分析
在进行XSLT转换时,一个常见的方法是从简单的模板开始,然后逐渐增加复杂性。让我们从一个简单的例子开始,逐步深入到更复杂的场景。
简单转换
假设我们有一个简单的书籍列表,并希望将其转换为HTML格式。
<books>
<book>
<title>XML Fundamentals</title>
<author>John Doe</author>
</book>
<book>
<title>XSLT Basics</title>
<author>Jane Smith</author>
</book>
</books>
对应的XSLT模板可以非常直接:
<xsl:template match="book">
<div class="book">
<xsl:value-of select="title"/> by <xsl:value-of select="author"/>
</div>
</xsl:template>
复杂转换
随着需求的增长,转换可能变得越来越复杂。例如,我们需要添加一个包含书籍详细信息的表格,带有作者的完整姓名、出版日期、ISBN等信息。这需要更多的模板和更复杂的逻辑。
<xsl:template match="book">
<table class="book-info">
<tr>
<th>Title</th>
<th>Author</th>
<th>Published Date</th>
<th>ISBN</th>
</tr>
<xsl:apply-templates select="details"/>
</table>
</xsl:template>
<xsl:template match="details">
<tr>
<td><xsl:value-of select="title"/></td>
<td><xsl:value-of select="author/fullname"/></td>
<td><xsl:value-of select="published"/></td>
<td><xsl:value-of select="isbn"/></td>
</tr>
</xsl:template>
3.3.2 解决实际开发中的常见问题
XSLT转换中经常遇到的一个问题是处理空节点或未命名节点。例如,如果某个 <book> 元素没有 <details> 子节点,直接应用模板会导致错误。为了避免这类问题,XSLT提供了 <xsl:if> 和 <xsl:when> 指令来根据节点的存在与否进行条件判断。
<xsl:if test="details">
<xsl:apply-templates select="details"/>
</xsl:if>
此外,XSLT还提供了异常处理机制,如 <xsl:try> 、 <xsl:catch> 和 <xsl:finally> 指令,可以用于捕获和处理转换过程中可能发生的错误。
<xsl:template match="book">
<xsl:try>
<!-- 转换逻辑 -->
<xsl:apply-templates select="details"/>
</xsl:try>
<xsl:catch errors="*">
<!-- 错误处理 -->
<p>Error processing book.</p>
</xsl:catch>
</xsl:template>
通过这些技巧和结构,我们可以构建出更为健壮和灵活的XSLT转换代码,以满足多样化的业务需求。
4. XPath详解:表达式、数据模型和上下文
4.1 XPath表达式深入理解
4.1.1 表达式的基础和核心功能
XPath,即XML路径语言,是一种用于在XML文档中查找信息的语言。它是XSLT的核心部分,用于指定文档中信息的路径。XPath表达式可以是绝对路径,也可以是相对路径。绝对路径以根节点开头,而相对路径则以当前节点为基准。XPath利用节点测试和谓词来指定和过滤节点集。
表达式核心功能包括定位节点、执行算术和比较操作以及处理字符串。例如,路径表达式 /bookstore/book 定位了所有 bookstore 元素下的 book 子元素。通过使用谓词如 [price>35] ,可以进一步过滤这些节点,得到价格大于35的所有 book 元素。
XPath表达式的基本语法为:
轴名称 :: 节点测试[谓词]
- 轴名称(Axes)定义了节点的树结构关系。例如
child::、parent::、following-sibling::。 - 节点测试(Node Test)指定要选择的节点类型,比如元素、属性、注释等。
- 谓词(Predicate)用于进一步过滤节点集。例如,
[position()=2]将选择第二个节点。
4.1.2 表达式在不同环境下的应用差异
XPath表达式在不同的XML处理工具和库中可能会有不同的实现和应用差异。比如,在XSLT中,它用于定义模板匹配规则,而在XQuery中,它用于查询XML数据库。在不同的编程语言环境中,如Java的JAXP,C#的LINQ to XML等,XPath表达式的具体实现和性能优化也会有所不同。
4.2 XPath的数据模型和节点类型
4.2.1 数据模型的层次结构
XPath的数据模型是层次化的,它定义了一种逻辑结构,用于表示和访问XML文档的组成部分。数据模型主要包含七种节点类型:根节点、元素节点、属性节点、文本节点、命名空间节点、处理指令节点和注释节点。
层次结构从根节点开始,每个节点代表XML文档的一部分。例如,元素节点代表XML中的标签,属性节点代表属性,文本节点代表标签之间的文本内容。
理解这些节点类型对于构建准确的XPath表达式至关重要。例如,如果要选择包含文本内容的元素,可以使用包含文本节点的表达式。
4.2.2 节点类型与应用场景
每种节点类型都有其特定的应用场景。例如,当你需要处理XML文档中元素的所有属性时,使用属性节点是非常合适的。如果你需要选择具有特定文本内容的元素,那么你可能需要使用文本节点。
在XPath中,节点类型通常以简写的形式表示,比如 @ 用于属性节点, // 用于选择任意位置的节点。通过结合使用不同的节点类型和谓词,可以构建复杂的查询来满足各种数据处理需求。
4.3 XPath上下文及其在转换中的作用
4.3.1 上下文定义及如何影响路径表达式
XPath上下文是指在执行XPath表达式时,所处的环境和状态。上下文包括了当前节点(上下文节点)、上下文位置、上下文大小、变量和函数库等。这些因素共同决定了一个表达式的执行结果。
上下文节点是指当前正在被处理的节点。在XSLT模板匹配过程中,它可能代表了当前正在处理的XML元素。上下文位置和上下文大小则分别表示当前节点在父节点中的位置索引和同级节点的总数。
这些上下文信息对路径表达式有着直接的影响。例如, position() 函数将返回上下文节点在其父节点中的位置,而 last() 函数则返回同级节点的总数。
4.3.2 上下文在实际编程中的优化应用
理解并正确使用上下文信息是优化XPath表达式的关键。例如,在一个循环中,你可以使用 position() 来获取当前迭代的位置,并根据这个信息来决定是否包含或排除某个节点。
此外,上下文还可以通过变量来扩展。在XPath中可以声明变量,并给变量赋值,这些变量可以在后续的路径表达式中使用。例如:
<xsl:variable name="varName" select="/bookstore/book[price>35]"/>
<xsl:value-of select="$varName/title"/>
在此例中,变量 varName 被赋予了一个XPath表达式的结果,该结果是所有价格大于35的 book 元素。之后, title 子节点将仅从这些符合条件的 book 元素中检索。
在实际编程中,合理使用变量和上下文信息可以简化复杂的XPath表达式,提高查询效率。同时,它还可以使得查询更加灵活,能够根据不同的上下文动态地调整查询结果。
在这一章节中,我们深入探讨了XPath表达式的基础和核心功能,对数据模型和节点类型进行了细致的分析,并详细解释了XPath上下文的定义以及它在实际编程中的优化应用。理解和掌握这些概念对于高效的XML文档处理至关重要。下一章节,我们将继续探索XSLT的输出方法及其格式设定。
5. XSL输出方法及格式设定
5.1 输出格式的种类和选择
5.1.1 不同输出格式的特点和应用场景
在XSLT(Extensible Stylesheet Language Transformations)处理中,输出格式的选择对于最终的文档表现至关重要。XSLT支持多种输出格式,以满足不同的需求和场景。最为常见的输出格式包括:
- HTML:广泛用于Web页面的制作,支持丰富的交互功能。由于其轻量级特性,HTML特别适合用于将数据展示在浏览器中。
- XHTML:是HTML的一个更为严格的版本,符合XML的规范。它在Web开发中得到了广泛的应用,特别是在要求高度结构化的页面中。
- 文本(Text):适用于需要将数据导出为纯文本格式的场景,比如日志文件、简单的报告等。
- XML:保持数据的层次结构,适用于需要进一步处理或用于其他XSLT转换的数据。
- RTF(Rich Text Format):适用于需要在Microsoft Word等文字处理软件中进行进一步编辑的文档。
- PDF(Portable Document Format):适用于需要高度一致的版面设计和打印输出的场景。
选择合适的输出格式需要考虑目标文档的使用环境和目的。例如,如果输出是为了网页展示,那么HTML可能是最佳选择;而如果需要一个结构化数据表示,那么XML可能是更合适的选择。
5.1.2 如何根据需求选择合适的输出格式
选择输出格式时应考虑以下几个要素:
- 目标环境 :输出文档将在哪个平台或程序中使用?例如,是否需要在Web浏览器中查看,或者是否需要在特定的软件中打开?
- 交互性 :文档需要提供多少用户交互功能?比如,是否需要嵌入JavaScript来创建动态效果?
- 结构保持 :文档需要保持原始的结构层次吗?如果需要维持数据结构,XML可能是合适的选择。
- 内容格式化 :输出需要高度的格式控制吗?例如,是否需要精确控制字体、布局以及页面分页?
- 性能和可访问性 :输出的性能要求和目标用户群体是什么?对于有特殊需求的用户,比如视障用户,需要考虑文档的可访问性。
- 后期处理 :是否需要对文档进行进一步的编辑或转换?如果需要,选择可以被其他软件支持的格式会更加方便。
通过权衡以上要素,可以确定最适宜的输出格式,满足特定项目的需求。
代码块示例:XSLT转换输出为HTML和PDF格式
<xsl:stylesheet version="1.0"
xmlns:xsl="***">
<xsl:output method="html" encoding="UTF-8" indent="yes"/>
<!-- 处理转换逻辑 -->
<xsl:template match="/">
<html>
<head>
<title>Example HTML Output</title>
</head>
<body>
<!-- HTML内容 -->
</body>
</html>
</xsl:template>
</xsl:stylesheet>
<xsl:stylesheet version="1.0"
xmlns:xsl="***">
<xsl:output method="xml" encoding="UTF-8" indent="yes"/>
<!-- 处理转换逻辑 -->
<xsl:template match="/">
<fo:root xmlns:fo="***">
<fo:layout-master-set>
<!-- PDF布局设置 -->
</fo:layout-master-set>
<fo:page-sequence>
<!-- PDF页面内容 -->
</fo:page-sequence>
</fo:root>
</xsl:template>
</xsl:stylesheet>
以上代码块显示了如何在XSLT中设置输出方法为HTML和PDF。对于HTML输出, <xsl:output> 指令指定了输出方法为 html 并设置了编码为 UTF-8 。对于PDF输出,需要创建一个符合XSL-FO(Formatting Objects)标准的结构,通过 <fo:root> 元素定义了PDF的布局设置。
表格:不同输出格式的特性对比
| 输出格式 | 交互性 | 结构保持 | 格式控制 | 性能要求 | 后期处理 | |----------|--------|----------|-----------|-----------|-----------| | HTML | 高 | 中 | 中 | 低 | 低 | | XHTML | 高 | 高 | 中 | 中 | 低 | | 文本 | 无 | 低 | 低 | 高 | 高 | | XML | 无 | 高 | 低 | 中 | 高 | | RTF | 中 | 中 | 中 | 中 | 中 | | PDF | 无 | 高 | 高 | 高 | 低 |
此表格提供了对不同输出格式特性的快速对比,从而帮助开发人员为项目选择最适合的输出格式。
5.2 输出控制的高级特性
5.2.1 使用XSLT控制输出格式和布局
输出控制的高级特性主要集中在输出格式的选择、布局的设置和内容的渲染。通过XSLT的高级特性,开发者可以精确地控制输出的每一部分。例如,使用XSLT 2.0中的属性 xsl:output 可以定义输出的类型,通过 indent 属性可以控制输出是否缩进,以提高可读性。同时,可以利用模板匹配规则和条件判断来动态决定输出内容。
5.2.2 复杂文档输出的定制技巧
当处理较为复杂的文档时,可能需要使用多个XSLT样式表,并通过导入( <xsl:include> 或 <xsl:import> )机制来组织和重用样式。此外,使用 <xsl:output> 指令的 media-type 属性可以指定输出的MIME类型。对于非标准输出格式,可以创建用户定义的输出方法(UDOM)。
为了改善输出质量,可使用以下技巧:
- 利用
xsl:decimal-format定义数字格式,以符合特定的地区习惯。 - 使用
<xsl:attribute>和<xsl:namespace>元素动态创建属性和命名空间。 - 创建自定义的函数,以处理特定的业务逻辑。
- 使用键(
<xsl:key>)和匹配模式进行复杂的节点选择。
代码块示例:高级输出控制和布局定制
<xsl:stylesheet version="1.0"
xmlns:xsl="***">
<!-- 定义数字格式 -->
<xsl:decimal-format name="custom" decimal-separator="," grouping-separator=" "/>
<!-- 设置输出格式为HTML,并使用自定义数字格式 -->
<xsl:output method="html" version="5" encoding="UTF-8"
doctype-public="-//W3C//DTD HTML 5.0//EN"
indent="yes"
decimal-format-name="custom" />
<!-- 自定义函数 -->
<xsl:function name="my:formatNumber">
<xsl:param name="number" as="xs:double"/>
<xsl:value-of select="format-number($number, '#,###.00', 'custom')"/>
</xsl:function>
<!-- 模板匹配和输出 -->
<xsl:template match="/">
<html>
<head>
<!-- HTML头部信息 -->
</head>
<body>
<!-- 应用自定义函数格式化数字 -->
<p>Formatted number: <xsl:value-of select="my:formatNumber(12345.67)" /></p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
以上示例展示了如何在XSLT样式表中实现自定义数字格式和输出控制。首先定义了一个名为 custom 的数字格式,然后在输出设置中使用了这个格式,并展示了如何在模板中应用自定义函数 my:formatNumber 来格式化数字输出。
5.3 输出方法在实际项目中的应用
5.3.1 实际案例分析:电子出版物的排版设计
在电子出版物的排版设计中,通常需要精确地控制页面布局、字体、图片等元素的显示。XSLT结合XSL-FO提供了一个强大的方式来创建复杂的排版设计。
电子出版物排版流程可能包括:
- 使用XSLT转换XML源文档,生成XSL-FO文档。
- 对XSL-FO文档进行进一步的格式化设置,如定义页边距、行间距、字体样式等。
- 将XSL-FO文档转换为最终的输出格式,如PDF。
5.3.2 输出性能优化和调试方法
输出性能优化和调试是确保转换过程高效运行的关键。性能优化可以通过以下方法实现:
- 精简不必要的转换步骤和模板。
- 使用键(
<xsl:key>)减少重复的节点查找。 - 避免在循环中进行大量的计算或排序操作。
- 利用
xsl:strip-space和xsl:preserve-space指令对空白进行优化处理。 - 使用适合的分析器和转换工具来处理大型文件。
调试过程中可以使用XSLT处理器提供的错误和警告消息来查找问题。可以将XSLT处理器设置为在遇到错误时停止执行,或者在文档末尾输出调试信息。
代码块示例:调试和性能优化技巧
<!-- 调试技巧 -->
<xsl:template match="*[local-name()='error']">
<xsl:copy>
<xsl:apply-templates select="@* | node()"/>
<!-- 附加调试信息 -->
</xsl:copy>
</xsl:template>
<!-- 性能优化 -->
<xsl:template match="book">
<xsl:variable name="book-info" select="document('book-info.xml')/book-info"/>
<book>
<xsl:apply-templates select="@* | node()"/>
<!-- 使用变量缓存结果以提高性能 -->
<info>
<xsl:value-of select="$book-info/title"/>
</info>
</book>
</xsl:template>
以上代码块提供了XSLT中的调试和性能优化的例子。在调试过程中,可以创建一个模板来捕获并复制任何遇到的错误节点,以及提供附加的调试信息。为了提高性能,可以使用变量来缓存重复使用的数据,减少不必要的文件读取操作。
小结
在本章节中,我们深入了解了XSL(Extensible Stylesheet Language)输出方法以及格式设定的重要性。我们探讨了如何根据项目需求选择合适的输出格式,并学习了控制输出格式和布局的高级技巧。通过实际案例分析,我们看到了输出方法在电子出版物排版设计中的应用。最后,我们掌握了如何优化输出性能和调试XSLT转换过程。通过这些技巧,开发者可以更高效地创建出满足特定需求的文档,无论是为了Web展示还是打印输出。
6. XML解析器类型与应用场景(DOM与SAX解析器)
解析XML文档是数据处理的关键步骤,尤其在需要对文档结构进行详细分析的场景中。DOM和SAX是两种常用的XML解析器,它们各自有不同的工作原理和适用场景。
6.1 DOM解析器的工作原理和优缺点
6.1.1 DOM树的构建和遍历
DOM(文档对象模型)解析器将XML文档完全读入内存,并构建一个树形结构,这一结构允许程序以对象的形式遍历整个文档。每个节点代表XML文档中的一个部分(元素、属性、文本等)。通过这种方式,DOM允许开发者进行复杂的数据处理和修改。
// Java 示例:使用DOM解析器解析XML文档
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("example.xml");
// 遍历DOM树
NodeList personNodes = document.getElementsByTagName("person");
for (int i = 0; i < personNodes.getLength(); i++) {
Node person = personNodes.item(i);
NamedNodeMap attributes = person.getAttributes();
// 处理每个person节点的细节...
}
6.1.2 DOM在内存消耗和性能上的考量
DOM解析器的主要缺点是内存消耗较大,尤其是处理大型XML文档时。因为要构建整个文档树,所以对内存的需求相对较高。性能上,如果不需要频繁访问文档中的元素,DOM解析器可能不是最优选择。
6.2 SAX解析器的特点和适用场景
6.2.1 SAX事件驱动的工作机制
SAX(简单API用于XML)解析器采用事件驱动的模型,这种解析器在解析文档时会触发各种事件(如开始标签、结束标签、文本内容等),开发者可以通过注册事件处理器来响应这些事件。
// Java 示例:使用SAX解析器处理XML文档
class PersonHandler extends DefaultHandler {
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (qName.equals("person")) {
// 处理开始标签 person...
}
}
public void endElement(String uri, String localName, String qName) throws SAXException {
if (qName.equals("person")) {
// 处理结束标签 person...
}
}
}
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse("example.xml", new PersonHandler());
6.2.2 SAX在大文件处理中的优势
SAX解析器由于不需要构建整个文档树,所以处理大型文件时内存效率更高,速度也更快。尤其适合于只进行单遍扫描,无需多次访问文档数据的场景。
6.3 解析器选择与性能权衡
6.3.1 根据应用需求选择合适的解析器
选择哪种解析器需要根据应用场景来确定。如果需要频繁地随机访问XML文档中的数据,并且文档规模不大,DOM可能是更好的选择。相反,如果关注内存效率和文件处理速度,特别是在流式处理大型文件时,SAX更合适。
6.3.2 解析器性能比较和实际应用案例
在实际应用中,性能测试可以提供更直观的解析器选择依据。例如,可以通过构建一个基准测试,测量在不同负载下,DOM和SAX解析器分别对解析时间和内存占用的影响。以下是性能比较的示例代码。
public class ParserPerformanceTest {
public static void main(String[] args) {
// 测试DOM解析器的性能
// ...
// 测试SAX解析器的性能
// ...
}
}
根据测试结果和项目需求,开发者可以更精确地选择合适的解析器。在具体案例中,比如在后端服务中处理用户上传的大型XML文件,SAX提供了一种更为高效的数据处理方式。而如果是在前端开发中处理小型配置文件,DOM解析器的易用性和灵活性则可能更占优势。
简介:XSL是一种用于转换XML文档的样式表语言,通过ECNU提供的PPT资源,学习者可以深入理解XSL的核心概念、组成以及转换技术。教程详细介绍了XSLT、XPath和XML解析器的使用,并通过实例和进阶话题加深理解。这些资料包括XSL基本概念、组成元素、XSLT和XPath语法、输出方法及实例分析,以及XML解析器的类型和使用方法。此外,还包括一份可能的学习指南或习题解答,助力学生巩固所学知识,提升XML处理能力。

















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









