







 本文介绍了如何使用Python爬虫从东方财富网抓取股票数据,并详细解析了爬取过程中的关键步骤,包括分析网页结构、获取参数以及完整代码展示。最后,数据被保存为CSV文件,适合Python爬虫初学者学习。
本文介绍了如何使用Python爬虫从东方财富网抓取股票数据,并详细解析了爬取过程中的关键步骤,包括分析网页结构、获取参数以及完整代码展示。最后,数据被保存为CSV文件,适合Python爬虫初学者学习。
专栏导读
🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手
🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注
👍 该系列文章专栏:请点击——>Python办公自动化专栏求订阅
🕷 此外还有爬虫专栏:请点击——>Python爬虫基础专栏求订阅
📕 此外还有python基础专栏:请点击——>Python基础学习专栏求订阅
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
❤️ 欢迎各位佬关注! ❤️
爬取页面
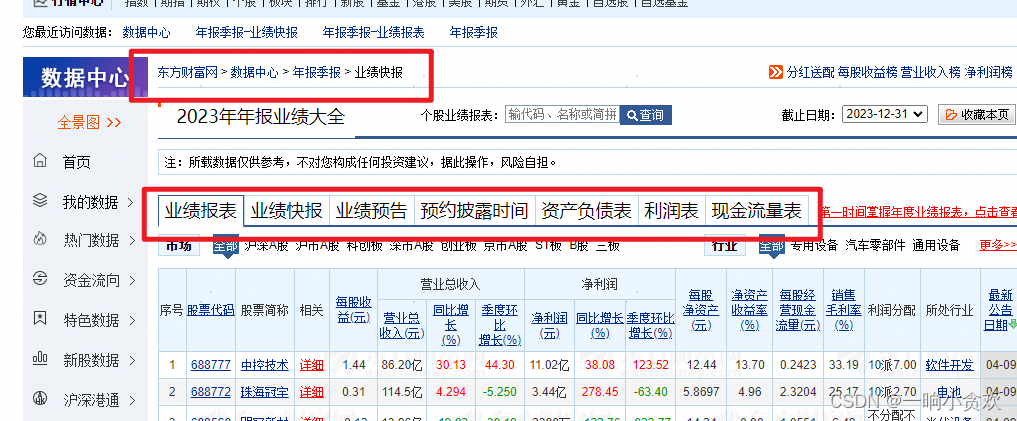
分析1
-
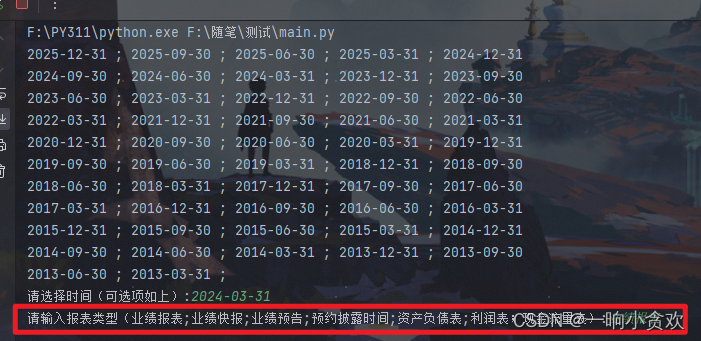
我们可以看到,这是事件的跨度,首首先我们需要获取您想知道的事件跨度
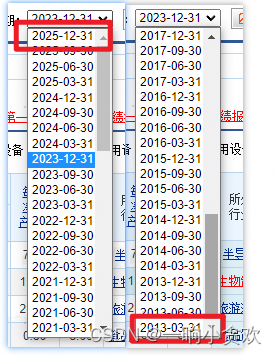
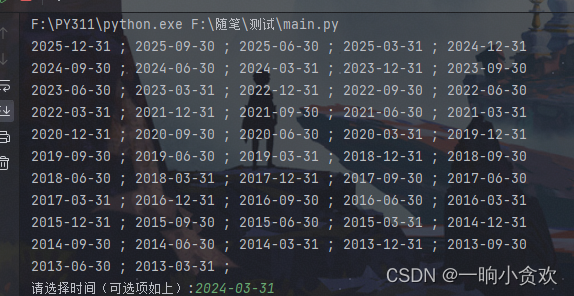
分析2
-
选择您想获取的分类
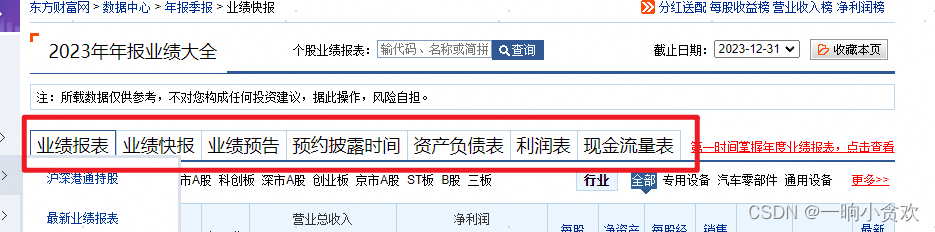
分析3
-
我们发现每一个类型,都有一个对应的参数【reportName】
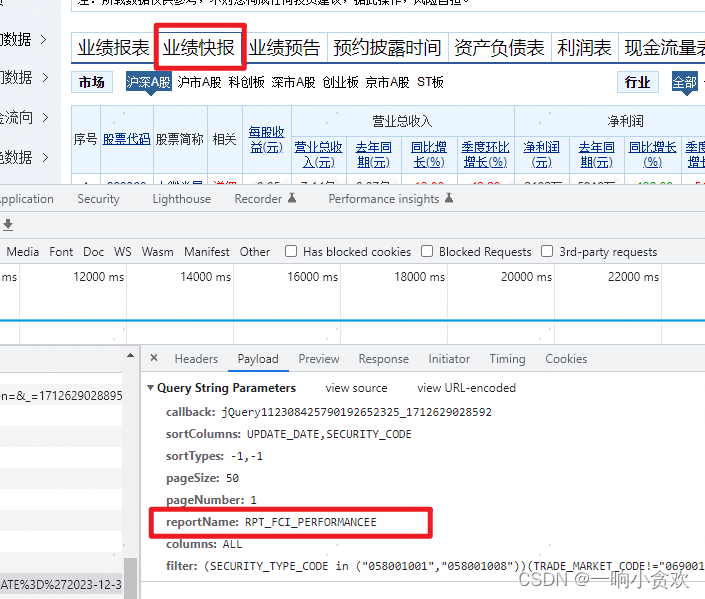
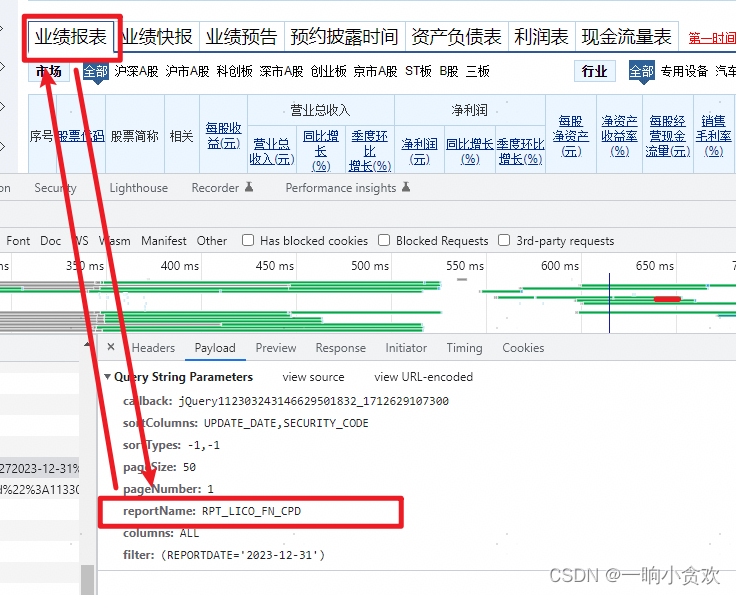
pagename_type = {
"业绩报表": "RPT_LICO_FN_CPD",
"业绩快报": "RPT_FCI_PERFORMANCEE",
"业绩预告": "RPT_PUBLIC_OP_NEWPREDICT",
"预约披露时间": "RPT_PUBLIC_BS_APPOIN",
"资产负债表": "RPT_DMSK_FN_BALANCE",
"利润表": "RPT_DMSK_FN_INCOME",
"现金流量表": "RPT_DMSK_FN_CASHFLOW"
}
分析4
-
我们发现每一个类型所对应的网页都有一个类型拼音的参数【】
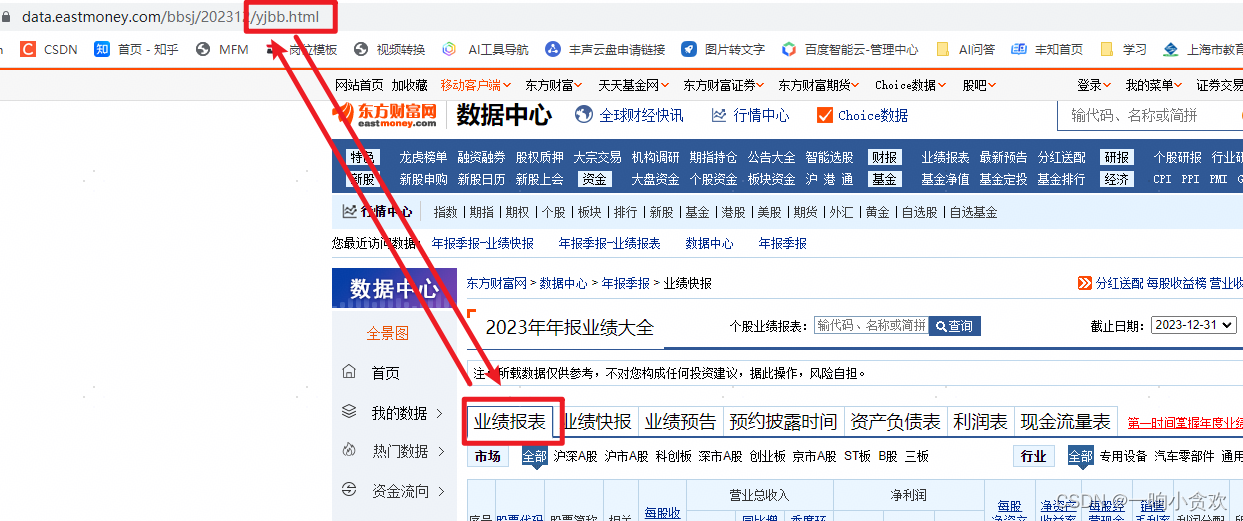
pagename_en = {
"业绩报表": "yjbb",
"业绩快报": "yjkb",
"业绩预告": "yjyg",
"预约披露时间": "yysj",
"资产负债表": "zcfz",
"利润表": "lrb",
"现金流量表": "xjll"
}
完整代码
import csv # 用于读写 CSV 文件
import json # 用于解析 JSON 数据
import requests # 用于发送 HTTP 请求
from lxml import etree # 用于解析 HTML 文档
# 定义 DataScraper 类,实现数据抓取功能
class DataScraper:
# 初始化函数
def __init__(self):
# 定义一个字典,用于存储页面名称和页面英文名称的对应关系
self.pagename_type = {
"业绩报表": "RPT_LICO_FN_CPD",
"业绩快报": "RPT_FCI_PERFORMANCEE",
"业绩预告" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











