






adaround就是优化量化取整的操作,正常量化公式如下:
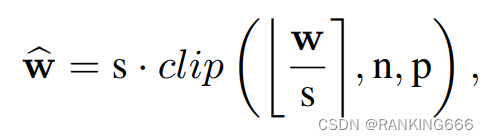
那么,[],到底是四舍五入还是取最近还是随机是个值得思考的问题。
首先,提高量化效果就是优化下面这项:
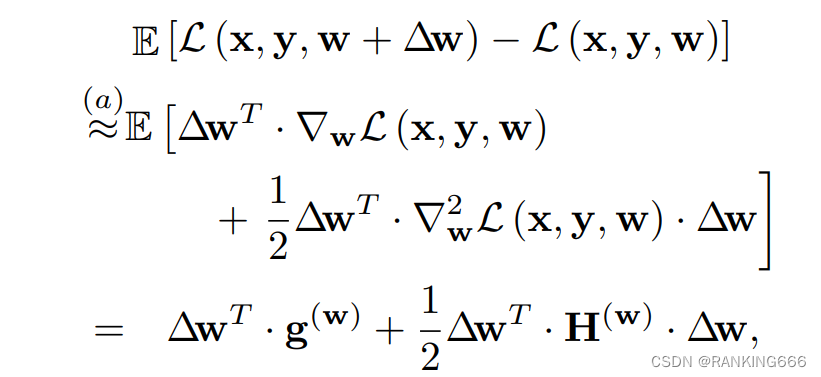
作者利用泰勒展开,展开为一阶项和二阶项,其中因为是PTQ量化,模型已训练收敛,故第一项可以忽略。那么优化公式改为
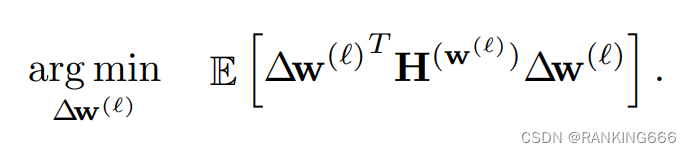
根据这个公式作者举了个例子来证明不同的取整方式对于精度的影响;
假设一个layer只有两个权重w1和w2,同时假设海森矩阵如图

故上面的公式可以化简为:
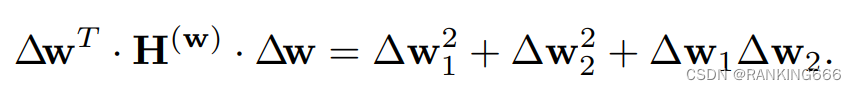
根据这个公式,如果我们取最近,那么第一项和第二项确实会小,但是第三项不确定,并且第三项是影响精度的,我们不能放任不管。同时对于n个weight值,并不是单独的每个weight的量化损失越少则整体损失就越小,weight之间的是存在相互的影响的,并且最终影响量化损失。
然后作者做了个小实验进行验证
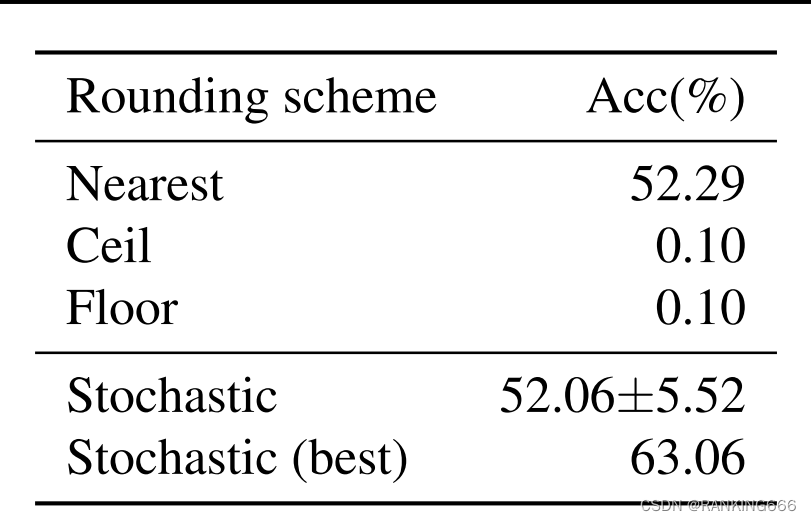
可以看到随机还是有可能会高的。
然后,那么如果优化这个取整呢?
首先作者做了如下三种假设
- scale值是一个固定值。
- 对于一个weight,其round方法只可能是floor round和ceil round二者中之一。
- 只考虑同layer内weight之间的相互影响,忽略了layer和layer之间weight的关系。
但是直接优化上面那个公式会存在一下两个问题
1.weight的海森矩阵非常巨大,求解很困难。
2. 求解也是一个NP-hard问题,无法直接求解。
什么是np-hard问题

然后就到了重要的部分(一堆推导和假设)
作者首先假设一个模型最后输出层l是一个只有两个weight的全连接,对weight计算二阶偏导即为:
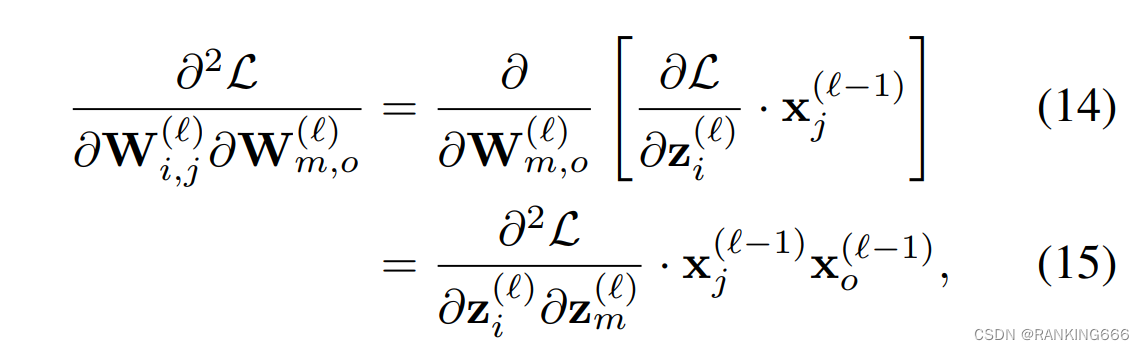 这里z(l)表示当前层的输入也就上一层w和x的乘,所以我们可以计算得出第l层权重的海森矩阵即为:
这里z(l)表示当前层的输入也就上一层w和x的乘,所以我们可以计算得出第l层权重的海森矩阵即为:
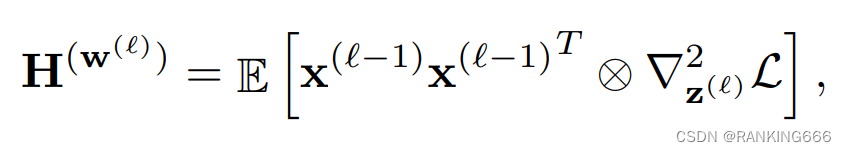
可以看出计算第L层weight的海森矩阵,需要借助第L-1层的二阶导信息,也就是这个原因导致直接计算每一层的海森矩阵是极其困难的,于是作者引入了一个假设:关于L-1层(也就是z(L))的海森矩阵是一个对角矩阵也就是L-1层的weights之间的相互关联对第L层weights的海森矩阵求导是不相关的。
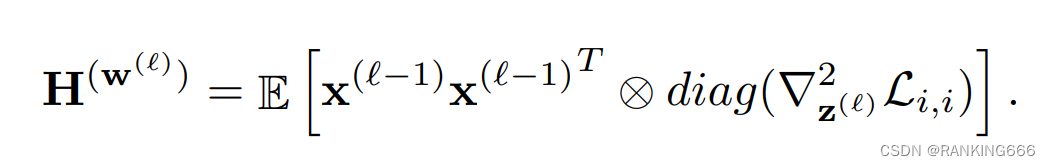
然后,作者引入了第二个假设:
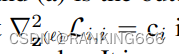
可以推导出
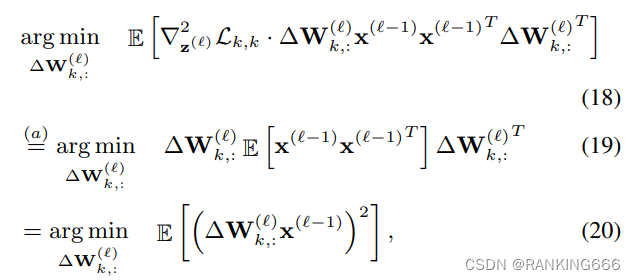
也就是说,作者假设在对第L层计算量化损失时,认为第L-1层对L层的量化损失影响是一个不依赖于校准数据集输入的常量,所以在公式(18)中可以直接省略。(在论文的实验中证明了该假设对最终结果的影响)。
于是通过多个假设,我们要求解的公式简化成了公式(20)。观察公式(20),可以发现此时待求解公式变成了一个每个layer独立的、不依赖于其它layer和task loss的求解公式。问题变成了找到可以使∆WX的MSE loss值最小的∆W。(转载)
而为了求解∆W,引出本文核心四个公式
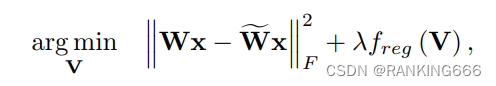
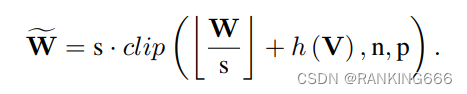
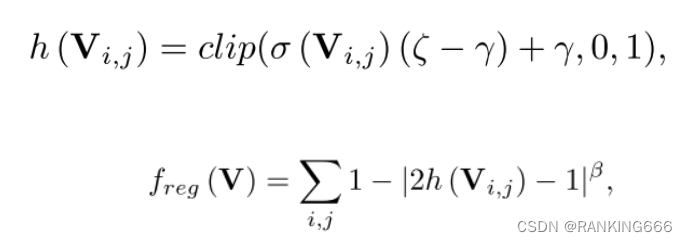
乍一看很复杂,其实非常好理解,我理解的就是在量化的[ ] 后加一个可训练的参数并且被限制在0-1,也就是相当于到底是up还是down,模型自己学,也就是h(v),这里引入了一个叫rectified sigmoid的东西,据说是可以解决传统的sigmoid梯度消失的问题。然后就很好理解了,练就完事,具体可以参考一篇知乎的讲解,侵删

同时,因为这里的量化是逐层计算的,并且不考虑其他层的影响,那么就会带来一个问题无法避免量化误差的不断累积也没有考虑到激活函数,所以最终公式如下:
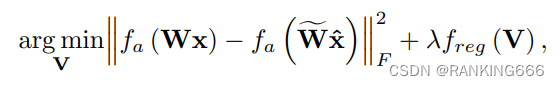
如有错误,欢迎批评指正!















 1779
1779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









