







视频资源:https://www.bilibili.com/video/BV12741177Cu?p=6&spm_id_from=pageDriver
from __future__ import division
%matplotlib inline
from torchvision import models
from PIL import Image
import argparse
import torch
import torchvision
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("torch version:", torch.__version__)
print("torchvision version:", torchvision.__version__)
torch version: 1.2.0+cu92
torchvision version: 0.4.0+cpu
图片风格迁移
# 读取两张图片
def load_image(image_path, transform=None, max_size=None, shape=None):
image = Image.open(image_path)
if max_size:
scale = max_size / max(image.size)
size = np.array(image.size) * scale
image = image.resize(size.astype(int), Image.ANTIALIAS)
if shape:
image = image.resize(shape, Image.LANCZOS)
if transform:
image = transform(image).unsqueeze(0)
return image.to(device)
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 注释这一行以查看原图
])
content = load_image("png/content.jpg", transform, max_size=400)
style = load_image("png/style.jpg", transform, shape=[content.size(2), content.size(3)])
unloader = torchvision.transforms.ToPILImage()
plt.ion()
def imshow(tensor, title=None):
image = tensor.cpu().clone()
image = image.squeeze(0)
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001)
plt.figure()
imshow(style[0], title="image")
结果:

class VGGNet(nn.Module):
def __init__(self):
super(VGGNet, self).__init__()
self.select = ['0', '5', '10', '19', '28']
self.vgg = models.vgg19(pretrained=True).features
def forward(self, x):
features = []
for name, layer in self.vgg._modules.items():
x = layer(x)
if name in self.select:
features.append(x)
return features
vgg = VGGNet().to(device).eval()
vgg = models.vgg19(pretrained=True)
# Downloading: "https://download.pytorch.org/models/vgg19-dcbb9e9d.pth" to
# C:\Users\Ken/.cache\torch\checkpoints\vgg19-dcbb9e9d.pth
vgg.features
# Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# ... 直到(36)
vgg = models.vgg19(pretrained=True)
# Downloading: "https://download.pytorch.org/models/vgg19-dcbb9e9d.pth" to
# C:\Users\Ken/.cache\torch\checkpoints\vgg19-dcbb9e9d.pth
vgg.features
# Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# ... 直到(36)
features = vgg(content)
print(len(features)) # output 5
for f in features:
print(f.shape)
结果:
5
torch.Size([1, 64, 400, 400])
torch.Size([1, 128, 200, 200])
torch.Size([1, 256, 100, 100])
torch.Size([1, 512, 50, 50])
torch.Size([1, 512, 25, 25])
target = content.clone().requires_grad_(True) # 模型里面的参数默认被训练,但是传入Tensor默认不被训练
optimizer = torch.optim.Adam([target], lr=0.003, betas=[0.5, 0.999]) # 目标竟然不是优化model.parameters()而是优化图片
num_steps = 2000
for step in range(num_steps):
target_features = vgg(target)
content_features = vgg(content)
style_features = vgg(style)
content_loss = 0.
style_loss = 0.
for f1, f2, f3 in zip(target_features, content_features, style_features):
content_loss += torch.mean((f1 - f2) ** 2)
_, c, h, w = f1.size()
f1 = f1.view(c, h*w)
f3 = f3.view(c, h*w)
f1 = torch.mm(f1, f1.t()) # c*c
f3 = torch.mm(f3, f3.t()) # c*c
style_loss += torch.mean((f1-f3)**2) / (c*w*h)
loss = content_loss + style_loss * 100.
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 10 == 0:
print("Step [{}/{}], Content Loss: {:.4f}, Style Loss: {:.4f}"
.format(step, num_steps, content_loss.item(), style_loss.item()))
结果:
Step [0/2000], Content Loss: 0.0534, Style Loss: 272.7734
Step [10/2000], Content Loss: 2.8618, Style Loss: 225.7414
Step [20/2000], Content Loss: 5.8346, Style Loss: 187.9423
Step [30/2000], Content Loss: 8.2275, Style Loss: 161.5069
Step [40/2000], Content Loss: 9.9225, Style Loss: 144.4485
Step [50/2000], Content Loss: 11.1214, Style Loss: 132.5195
denorm = torchvision.transforms.Normalize([-2.12, -2.04, -1.80], [4.37, 4.46, 4.44]) # 上面 Normalize 的反向操作
img = target.clone().squeeze()
img = denorm(img).clamp_(0, 1)
imshow(img, title="Target Image")
结果:

GAN
batch_size = 32
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.5,), std=(0.5,)) # 必须是tuple不能是list
])
mnist_data = torchvision.datasets.MNIST("./mnist_data", train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset=mnist_data, batch_size=batch_size, shuffle=True)
plt.imshow(next(iter(dataloader))[0][1][0], cmap=plt.cm.gray) # 本来不是彩色的,是plt做了转换
<matplotlib.image.AxesImage at 0x1d5c68bb9b0>
结果:
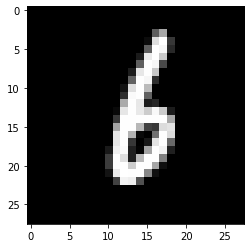
image_size = 28 * 28
hidden_size = 256
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid()
)
latent_size = 64
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh()
)
D = D.to(device)
G = G.to(device)
loss_fn = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=2e-4)
g_optimizer = torch.optim.Adam(G.parameters(), lr=2e-4)
total_steps = len(dataloader)
num_epochs = 30
for epoch in range(num_epochs):
for i, (images, _) in enumerate(dataloader):
batch_size = images.shape[0]
images = images.reshape(batch_size, image_size).to(device)
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 优化判别器:1 判别真图片
outputs = D(images) # 让判别器判断真图片
d_loss_real = loss_fn(outputs, real_labels)
real_score = outputs # 对于判别器,越大越好
# 优化判别器:2 生成并判别假图片
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z) # 生成假图片
outputs = D(fake_images.detach()) # detach: 从计算图中分离,不再反向传播
d_loss_fake = loss_fn(outputs, fake_labels)
fake_score = outputs # 对于判别器,越小越好
# 优化判别器:3 计算loss之和并优化
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 优化生成器:1 生成假图片
outputs = D(fake_images) # 这个输出不从计算图分离
g_loss = loss_fn(outputs, real_labels) # 让outputs接近1
# 优化生成器:2 计算loss并优化
d_optimizer.zero_grad()
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
if i % 100 == 0:
print("Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.4f}, D(G(z)): {:.4f}"
.format(epoch, num_epochs, i, total_steps, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item()))
结果:
Epoch [0/30], Step [0/1875], d_loss: 0.0436, g_loss: 4.4450, D(x): 0.9819, D(G(z)): 0.0247
Epoch [0/30], Step [100/1875], d_loss: 0.1032, g_loss: 3.4560, D(x): 0.9726, D(G(z)): 0.0719
Epoch [0/30], Step [200/1875], d_loss: 0.1581, g_loss: 4.6352, D(x): 0.9543, D(G(z)): 0.0824
Epoch [0/30], Step [300/1875], d_loss: 0.2218, g_loss: 5.6603, D(x): 0.9099, D(G(z)): 0.0539
Epoch [0/30], Step [400/1875], d_loss: 0.0425, g_loss: 5.0872, D(x): 0.9829, D(G(z)): 0.0233
...
# 查看生成的假图片
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
fake_images = fake_images.view(batch_size, 28, 28).data.cpu().numpy()
plt.imshow(fake_images[2], cmap=plt.cm.gray)
<matplotlib.image.AxesImage at 0x1d580162978>
结果:
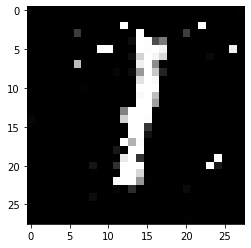
数据集下载:https://pan.baidu.com/s/149qNt8EKDcpclUEeoFBhrA
image_size = 64
batch_size = 128
dataroot = "celeba"
num_workers = 2
dataset = torchvision.datasets.ImageFolder(root=dataroot, transform=torchvision.transforms.Compose([
torchvision.transforms.Resize(image_size),
torchvision.transforms.CenterCrop(image_size),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
real_batch = next(iter(dataloader))
im = torchvision.utils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True)
plt.figure(figsize=(8, 8))
plt.axis=("off")
plt.title("Traning Images")
plt.imshow(im.permute(1, 2, 0))
<matplotlib.image.AxesImage at 0x1d584cfec88>
结果:

def weight_init(m):
classname = m.__class__.__name__
if "Conv" in classname:
nn.init.normal_(m.weight.data, mean=0., std=0.02)
elif "BatchNorm" in classname:
nn.init.normal_(m.weight.data, mean=1.0, std=0.02)
nn.init.constant_(m.bias.data, val=0)
nz = 100
ngf = 64 # number of generated features
nc = 3 # number of channels
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(in_channels=nz, out_channels=ngf*8, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size: ngf*8, 4, 4 计算公式 卷积out-pad=(in-k+s)/s 反卷积in=(out-pad)*s-s+k 计算 1*1-1+4=4
nn.ConvTranspose2d(in_channels=ngf*8, out_channels=ngf*4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size: ngf*4, 8, 8 计算 (4-1)*2-2+4=8
nn.ConvTranspose2d(in_channels=ngf*4, out_channels=ngf*2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size: ngf*2, 16, 16 计算 (8-1)*2-2+4=16
nn.ConvTranspose2d(in_channels=ngf*2, out_channels=ngf, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size: ngf, 32, 32
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
return self.main(x)
G = Generator().to(device)
G.apply(weight_init)
print(G)
结果:
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
)
)
ndf = 64 # number of discriminator features
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# state size: nc, 64, 64 计算公式 out=int(in+p-k+s)/s
nn.Conv2d(in_channels=nc, out_channels=ndf, kernel_size=4, stride=2, padding=1, bias=True), # bias是padding两边
nn.LeakyReLU(0.2, inplace=True),
# state size: ndf, 32, 32 计算 (64+1*2-4+2)/2=32
nn.Conv2d(ndf, ndf*2, 4, 2, 1, bias=True),
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2, inplace=True),
# state size: ndf*2, 16, 16 计算 (32+1*2-4+2)/2=32
nn.Conv2d(ndf*2, ndf*4, 4, 2, 1, bias=True),
nn.BatchNorm2d(ndf*4),
nn.LeakyReLU(0.2, inplace=True),
# state size: ndf*4, 8, 8 计算 (16+1*2-4+2)/2=8
nn.Conv2d(ndf*4, ndf*8, 4, 2, 1, bias=True),
nn.BatchNorm2d(ndf*8),
nn.LeakyReLU(0.2, inplace=True),
# state size: ndf*8, 4, 4 计算 (8+1*2-4+2)/2=4
nn.Conv2d(ndf*8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.main(x)
D = Discriminator().to(device)
D.apply(weight_init)
print(D)
结果:
Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)
total_steps = len(dataloader)
num_epochs = 5
for epoch in range(num_epochs):
for i, data in enumerate(dataloader):
D.zero_grad()
real_images = data[0].to(device)
b_size = real_images.size(0)
label = torch.ones(b_size).to(device)
output = D(real_images).view(-1)
real_loss = loss_fn(output, label)
real_loss.backward()
D_x = output.mean().item() # 输出真实图片的判断结果
# 生成假图片
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake_images = G(noise)
label.fill_(0)
output = D(fake_images.detach()).view(-1)
fake_loss = loss_fn(output, label)
fake_loss.backward() # 因为D的grad没有清零所以会加起来
d_optimizer.step()
D_G_z1 = output.mean().item() # 输出假图片的判断结果
loss_D = real_loss + fake_loss # 输出D的loss
# 训练Generator
G.zero_grad()
label.fill_(1)
output = D(fake_images).view(-1)
loss_G = loss_fn(output, label)
loss_G.backward()
D_G_z2 = output.mean().item()
g_optimizer.step()
if i % 10 == 0:
print("Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.4f}, D(G(z)): {:.4f}"
.format(epoch, num_epochs, i, total_steps, loss_D.item(), loss_G.item(), D_x, D_G_z2))
Epoch [0/5], Step [0/235], d_loss: 0.0282, g_loss: 32.7521, D(x): 0.9752, D(G(z)): 0.0000
Epoch [0/5], Step [10/235], d_loss: 0.0007, g_loss: 35.9624, D(x): 0.9993, D(G(z)): 0.0000
Epoch [0/5], Step [20/235], d_loss: 0.0014, g_loss: 35.5913, D(x): 0.9987, D(G(z)): 0.0000
Epoch [0/5], Step [30/235], d_loss: 0.0003, g_loss: 35.4103, D(x): 0.9997, D(G(z)): 0.0000
Epoch [0/5], Step [40/235], d_loss: 0.0001, g_loss: 35.0586, D(x): 0.9999, D(G(z)): 0.0000
Epoch [0/5], Step [50/235], d_loss: 0.0001, g_loss: 34.8043, D(x): 0.9999, D(G(z)): 0.0000
Epoch [0/5], Step [60/235], d_loss: 0.0002, g_loss: 34.2846, D(x): 0.9998, D(G(z)): 0.0000
Epoch [0/5], Step [70/235], d_loss: 0.0002, g_loss: 32.7791, D(x): 0.9998, D(G(z)): 0.0000
...
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
with torch.no_grad():
fake = G(fixed_noise).detach().cpu()
real_batch = next(iter(dataloader))
# Plot the real images
plt.figure(figsize=(16,8))
plt.subplot(1,2,1)
plt.axis=("off")
plt.title("Real Images")
plt.imshow(np.transpose(torchvision.utils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis=("off")
plt.title("Fake Images")
plt.imshow(np.transpose(torchvision.utils.make_grid(fake, padding=2, normalize=True), (1,2,0)))
plt.show()















 1702
1702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









