







01Neural Style Transfer
图片风格迁移

图片表示
使用VGG network来表示
内容图片
风格图片
风格迁移后的新图片
Content Loss

Style Loss

02 Generative Adversarial Network
Generator: 生成器,目标是让生成的数据接近真实数据
Discriminator: 分类器,目标是能够鉴别真实数据和生成的假数据
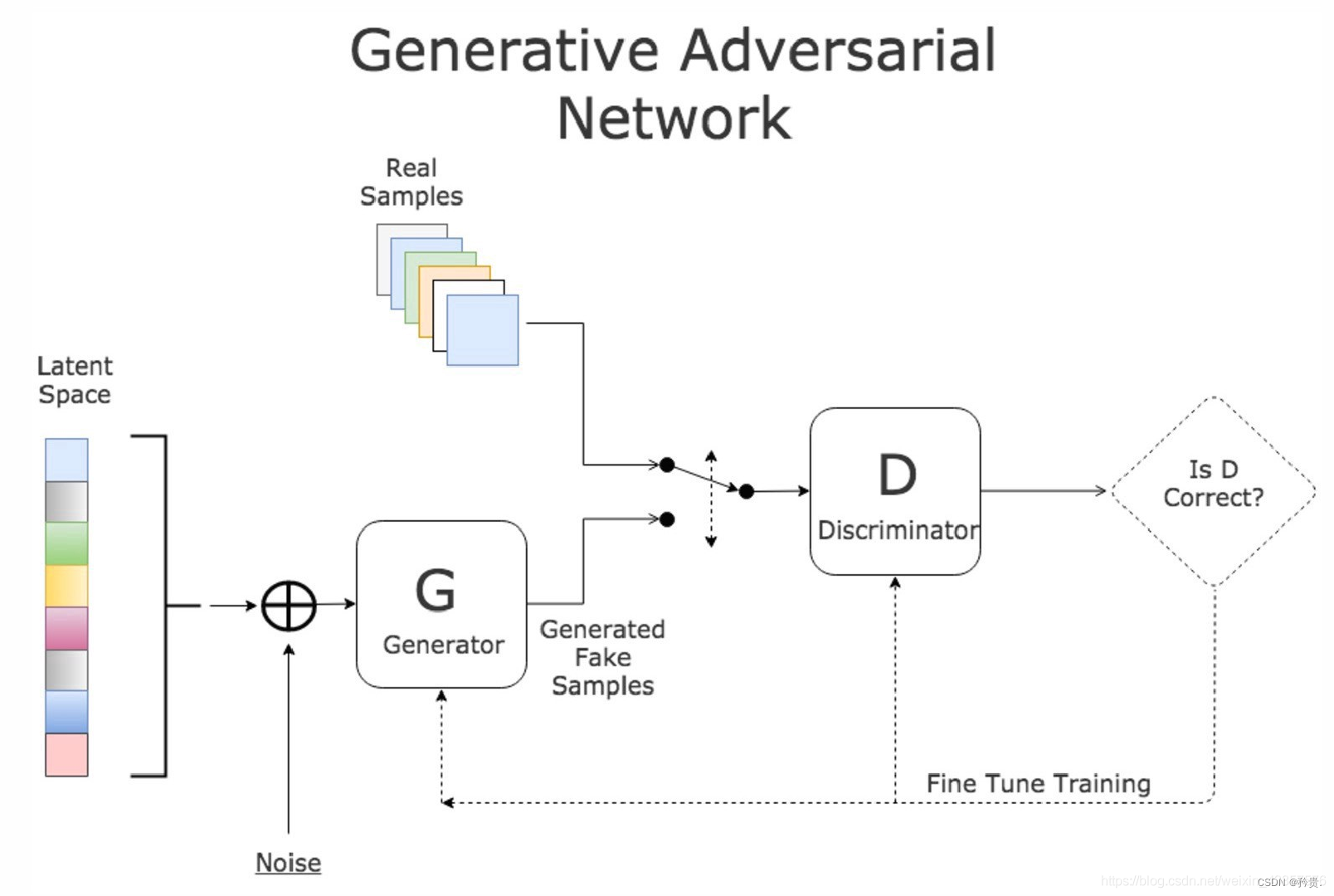
DCGAN

03 CycleGAN
Network
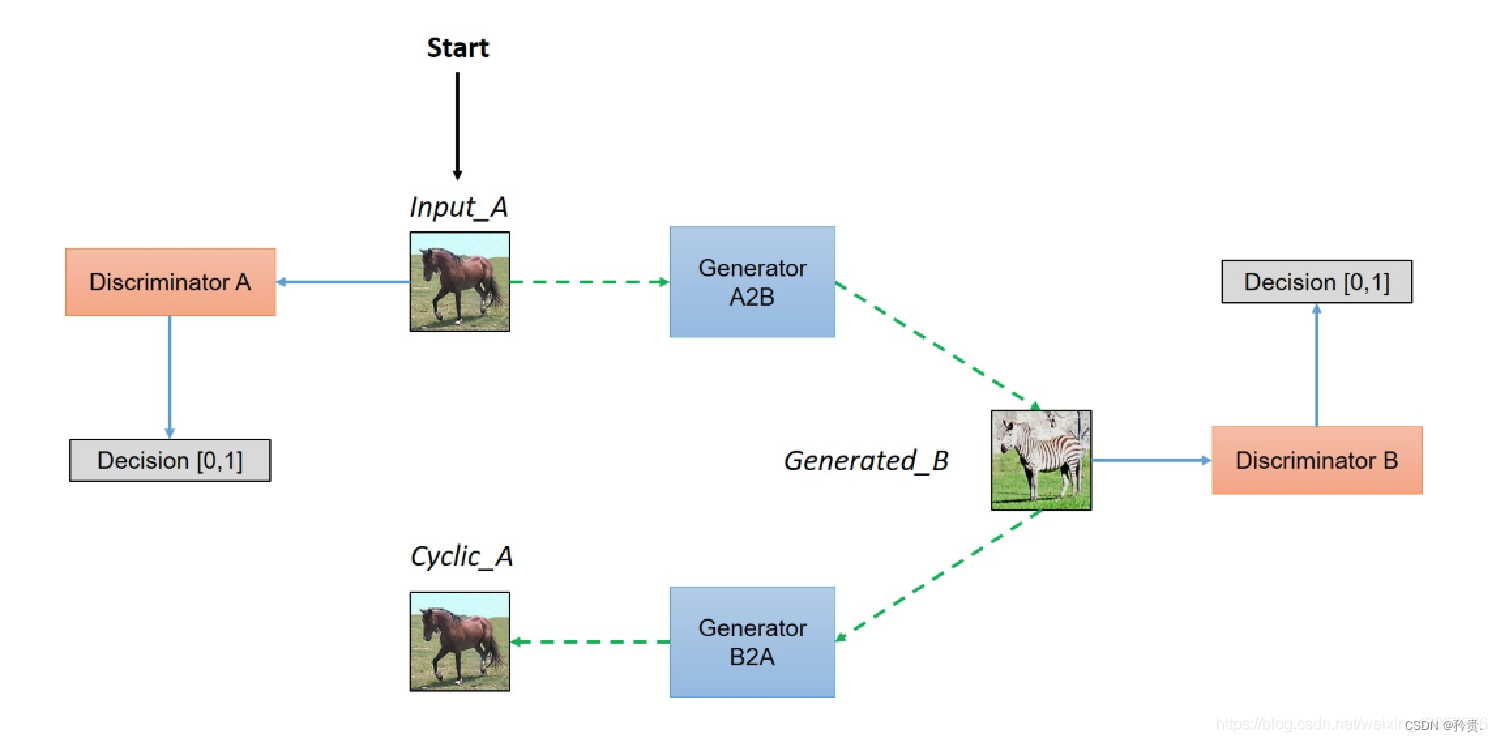
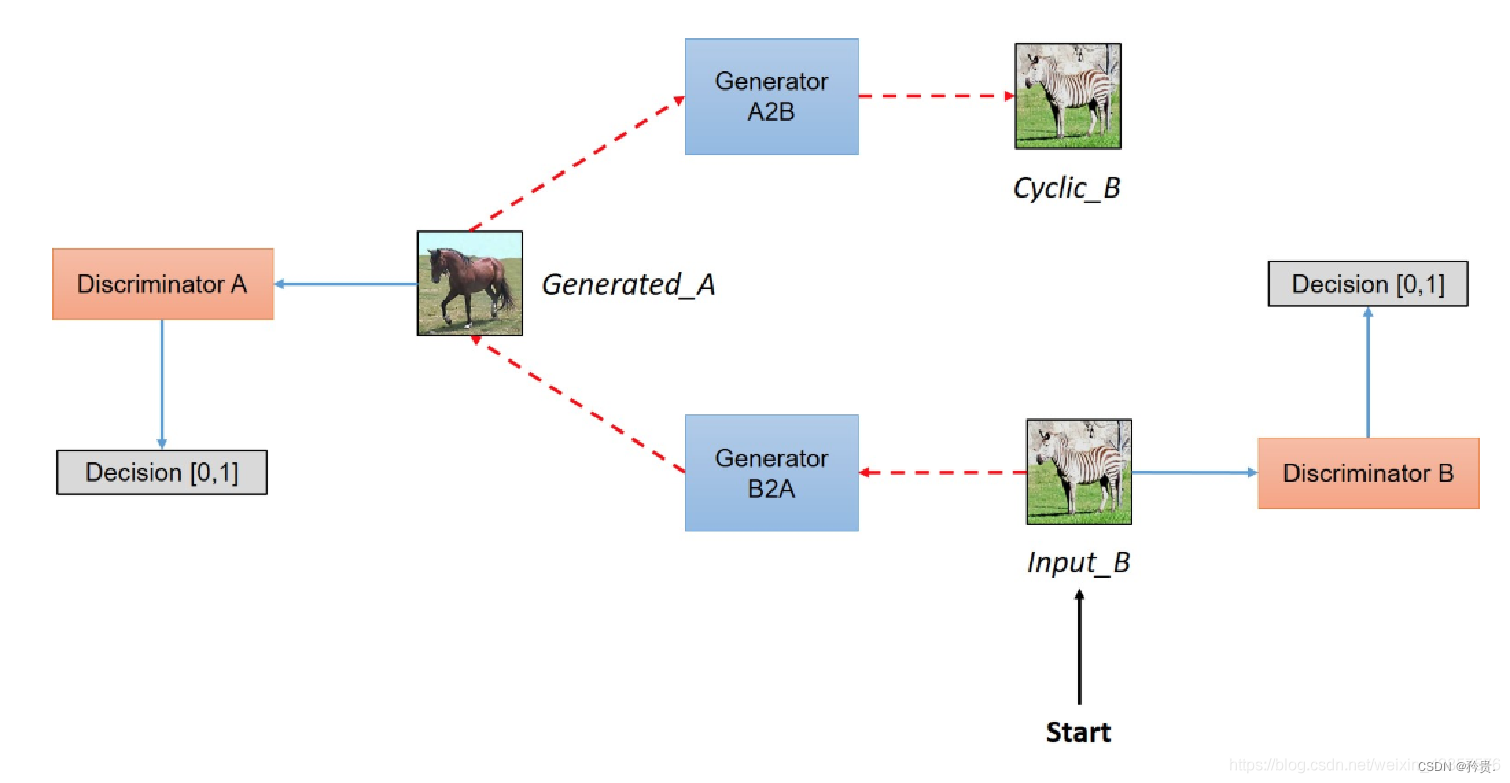
模型架构
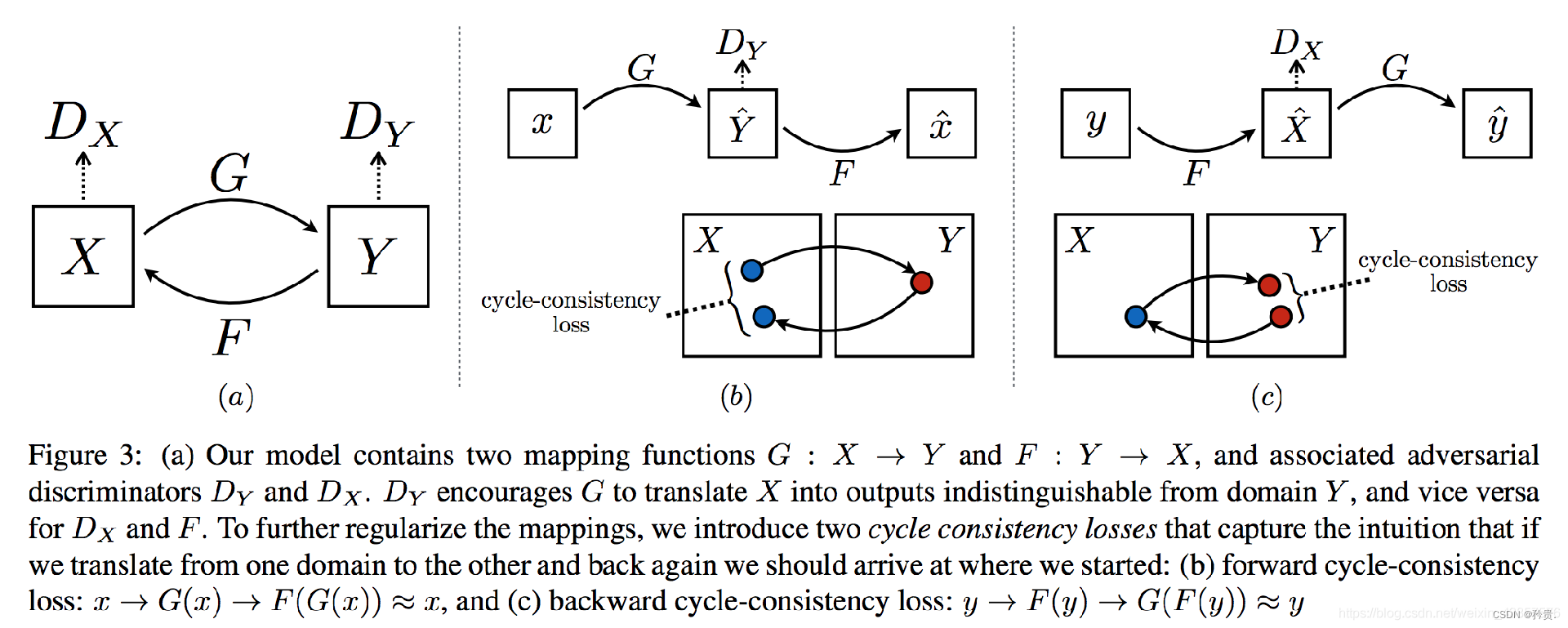
损失函数
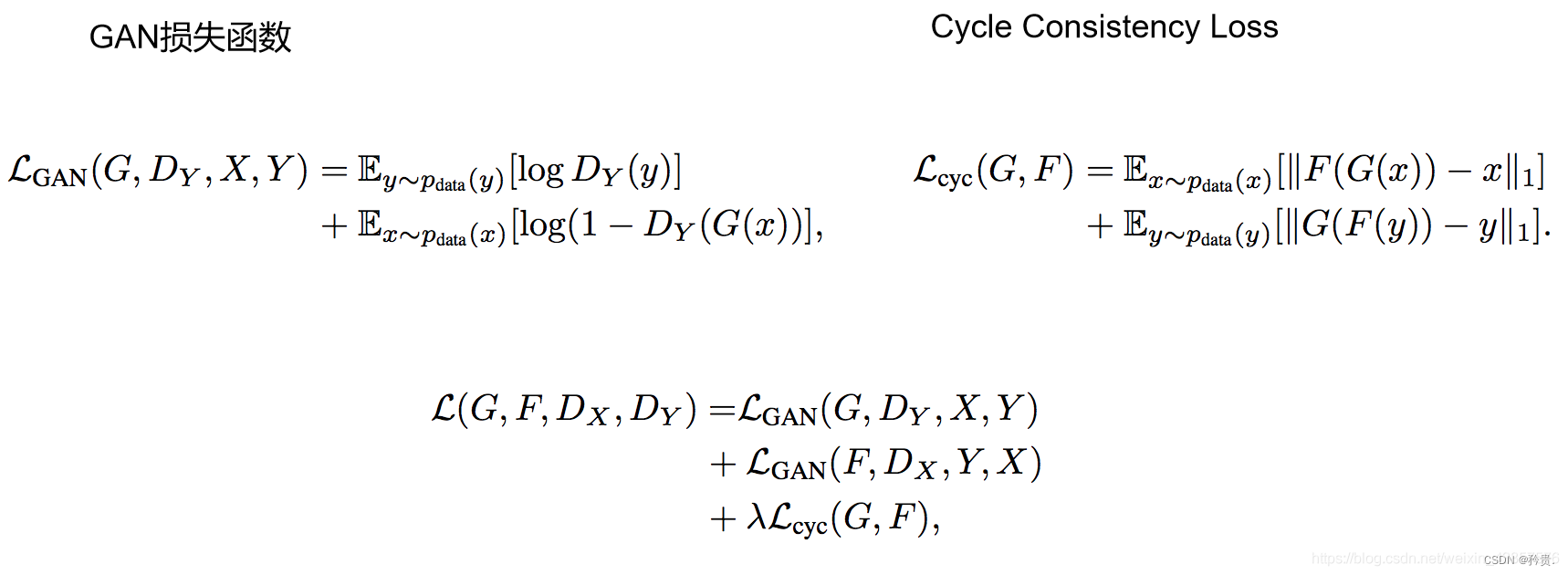
**
模型代码
**
图片风格迁移
读取两张图片
def load_image(image_path, transform=None, max_size=None, shape=None):
image = Image.open(image_path)
if max_size:
scale = max_size / max(image.size)
size = np.array 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









