from torchvision import models,transforms
from PIL import Image
import torch
import torchvision
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
device = torch.device("cuda"if torch.cuda.is_available()else"cpu")
classVGGNet(nn.Module):def__init__(self):super(VGGNet,self).__init__()
self.select =['0','5','10','19','28']
self.vgg = models.vgg19(pretrained=True).features
defforward(self,x):
features =[]for name,layer in self.vgg._modules.items():
x = layer(x)if name in self.select:
features.append(x)return features
target = content.clone().requires_grad_(True)#加这步说明target自身的像素参数需要更新
optimizer = torch.optim.Adam([target],lr=0.003,betas=[0.5,0.999])
vgg = VGGNet().to(device).eval()
target_features = vgg(target)
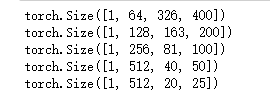
for i,feature inenumerate(target_features):print(feature.size())


























 3523
3523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









