






前一段时间接了个业务比较特殊,它的场景是这样的:
–每天入库数据量3亿左右
–写多读少,每隔5分钟写入10w数据
–按天分表,多年同一天的数据在一个表里
–同一天的数据每隔5分钟更新一次
–数据来源,经过Hadoop分析过后的csv文件
--类似于这样的,会有并发同时跑,但是数据量和间隔时间不一样
数据库配置:普通sas盘,24G内存,16核CPU,单实例,1主1备
优化前的做法是:
1. 把原来的前几分钟的数据根据日期delete掉
2. 使用程序读取分析过的csv文件,拼装成insert into tbname (col1,col2,......) values (val1,val2,....,),(val3,val4,.......,),.......;
存在问题:
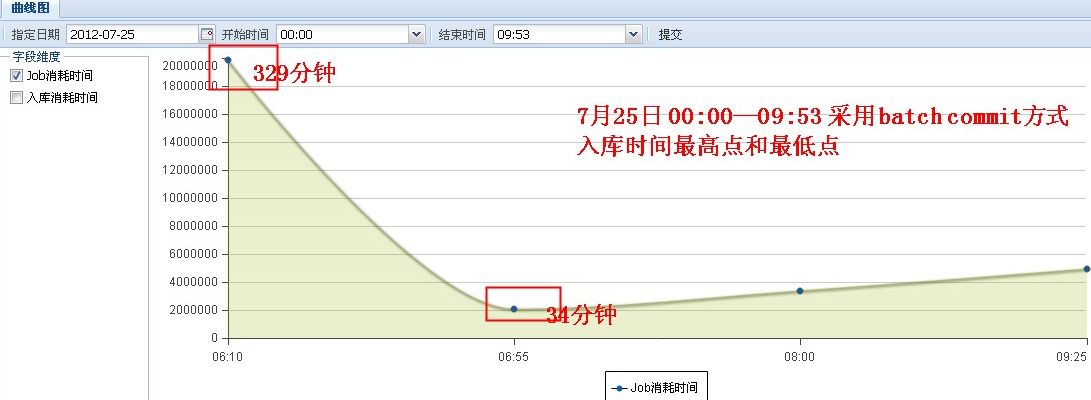
1. 主库写入太慢最长的一个表插入时间要329分钟
2. 备库延迟太大(>20w秒),慢查询文件很大16G,存在单点故障
效率图:
优化做法:
把insert换成load
优化成果:
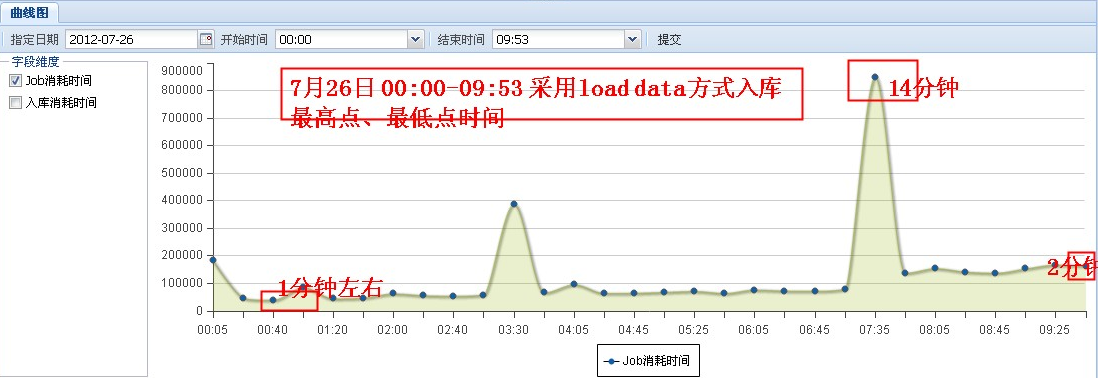
CPU消耗情况:
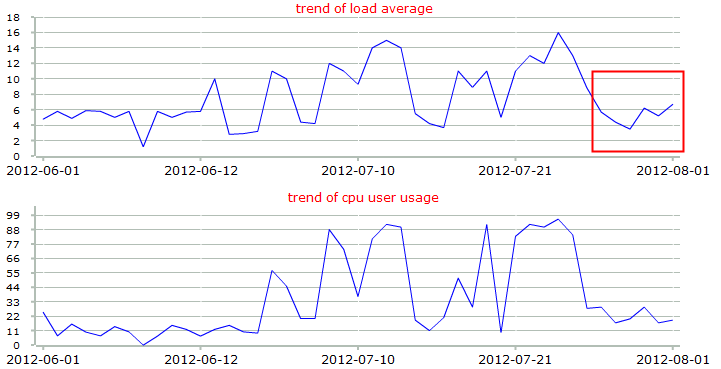
io情况有所好转,但是iowait仍然严重,因为本来就是io bound型,虽然减少了大部分记录慢日志的io,其他io情况,没有像写入效率那么明显。
备库没有延迟,解决了单点故障
原因:
MySQL手册里已经说得很清楚:
1. 关掉自动提交
2. 禁掉唯一索引
3. 禁掉外键
这样能节省大量物理io
原因:
load data跳过sql解析,直接生成数据文件;
load data在导入之前会关掉索引,导入完成后更新索引;
load data开始执行后占用的内存空间不会被purge掉
另外load data的速度和文件每行的大小有关,每行所占的字节数越少,load的速度越快;同样的前提,没有索引的要比有索引的要快;
如何提高插入表的效率,欢迎移步: http://www.informit.com/articles/article.aspx?p=377652&seqNum=4
http://www.innodb.com/doc/innodb_plugin-1.0/innodb-create-index.html
http://www.mysqlperformanceblog.com/2008/04/23/testing-innodb-barracuda-format-with-compression/
http://www.mysqlperformanceblog.com/2008/07/03/how-to-load-large-files-safely-into-innodb-with-load-data-infile/















 5700
5700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









