






一 python与Excel表格
Excel 是 Windows 环境下流行的、强大的电子表格应用。openpyxl 模块让 Python 程序能读取和修改 Excel电子表格文件
1)excel文档的基本定义
- 工作薄(workbook)
- 工作表(sheet)
- 活动表(active sheet)
- 行(row): 1,2,3,4,5,6……..
- 列(column): A,B,C,D……..
- 单元格(cell): B1, C1
2)python对于Excel表格操作的模块有很多种,这里选用openpyxl模块
但是openpyxl模块时需要进行安装的
pip install openpyxl利用以上命令来安装openpyxl模块
这是选作需要操作的表格

1> 打开一个excel文档
import openpyxl
# 1. 打开一个excel文档, class 'openpyxl.workbook.workbook.Workbook'实例化出来的对象
wb = openpyxl.load_workbook('Book.xlsx')
print(wb, type(wb))
# 获取当前工作薄里所有的工作表, 和正在使用的表;
print(wb.sheetnames)
print(wb.active)
输出的是一个对象
2> 选择要操作的工作表
# 2. 选择要操作的工作表, 返回工作表对象
sheet = wb['Sheet1']
# 获取工作表的名称
print(sheet.title)
3> 指定行指定列的单元格信息
# 3. 返回指定行指定列的单元格信息
print(sheet.cell(row=1, column=2).value)
cell = sheet['B1']
print(cell)
print(cell.row, cell.column, cell.value)
4> 获取工作表中行和列的最大值
# 4. 获取工作表中行和列的最大值
print(sheet.max_column)
print(sheet.max_row)
sheet.title = '学生信息'
print(sheet.title)
5> 访问单元格的所有信息
# 5. 访问单元格的所有信息
print(sheet.rows) # 返回一个生成器, 包含文件的每一行内容, 可以通过便利访问.
# 循环遍历每一行
for row in sheet.rows:
# 循环遍历每一个单元格
for cell in row:
# 获取单元格的内容
print(cell.value, end=',')
print()
6> 保存修改信息
# 6. 保存修改信息
wb.save(filename='Boom.xlsx')
因此操作Excel表格可详细的概括如下:
1.导入 openpyxl 模块。
2.调用 openpyxl.load_workbook()函数。
3.取得 Workbook 对象。
4.调用 wb.sheetnames和 wb.active 获取工作簿详细信息。
5.取得 Worksheet 对象。
6.使用索引或工作表的 cell()方法,带上 row 和 column 关键字参数。
7.取得 Cell 对象。
8.读取 Cell 对象的 value 属性
二 Excel简单实例
- 定义一个函数, readwb(wbname, sheetname=None)
- 如果用户指定sheetname就打开用户指定的工作表, 如果没有指定, 打开active sheet;
- 根据商品的价格进行排序(由小到大), 保存到文件中;商品名称:商品价格:商品数量
- 所有信息, 并将其保存到数据库中
import os
import openpyxl
def readwb(wbname, sheetname=None):
# 打开工作薄
wb = openpyxl.load_workbook(wbname)
# 获取要操作的工作表
if not sheetname:
sheet = wb.active
else:
sheet = wb[sheetname]
# 获取商品信息保存到列表中
#[ ['name', price, count]
all_info = []
for row in sheet.rows:
child = [cell.value for cell in row]
all_info.append(child)
return sorted(all_info, key=lambda item: item[1])
def save_to_excel(data, wbname, sheetname='sheet1'):
"""
将信息保存到excel表中;
[[' BOOK', 50, 3], ['APPLE', 100, 1], ['BANANA', 200, 0.5]]
"""
print("写入Excel[%s]中......." %(wbname))
# 打开excel表, 如果文件不存在, 自己实例化一个WorkBook对象
wb = openpyxl.Workbook()
# 修改当前工作表的名称
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
for row, item in enumerate(data): # 0 [' BOOK', 50, 3]
for column, cellValue in enumerate(item): # 0 ' BOOK'
sheet.cell(row=row+1, column=column+1, value=cellValue)
# ** 往单元格写入内容
# sheet.cell['B1'].value = "value"
# sheet.cell(row=1, column=2, value="value")
# 保存写入的信息
wb.save(filename=wbname)
print("写入成功!")
data = readwb(wbname='Book1.xlsx')
save_to_excel(data, wbname='Book2.xlsx', sheetname="排序商品信息")
* 三 更改表格的内容*
每一行代表一次单独的销售。列分别是销售产品的类型(A)、产品每磅的价格
(B)、销售的磅数(C),以及这次销售的总收入。TOTAL 列设置为 Excel 公式,将每磅的成本乘以销售的磅数,
并将结果取整到分。有了这个公式,如果列 B 或 C 发生变化,TOTAL 列中的单元格将自动更新.
需要更新的价格如下:
Celery 1.19
Garlic 3.07
Lemon 1.27
现在假设 Garlic、 Celery 和 Lemons 的价格输入的不正确。这让你面对一项无聊
的任务:遍历这个电子表格中的几千行,更新所有 garlic、celery 和 lemon 行中每磅
的价格。你不能简单地对价格查找替换,因为可能有其他的产品价格一样,你不希
望错误地“更正”。对于几千行数据,手工操作可能要几小时
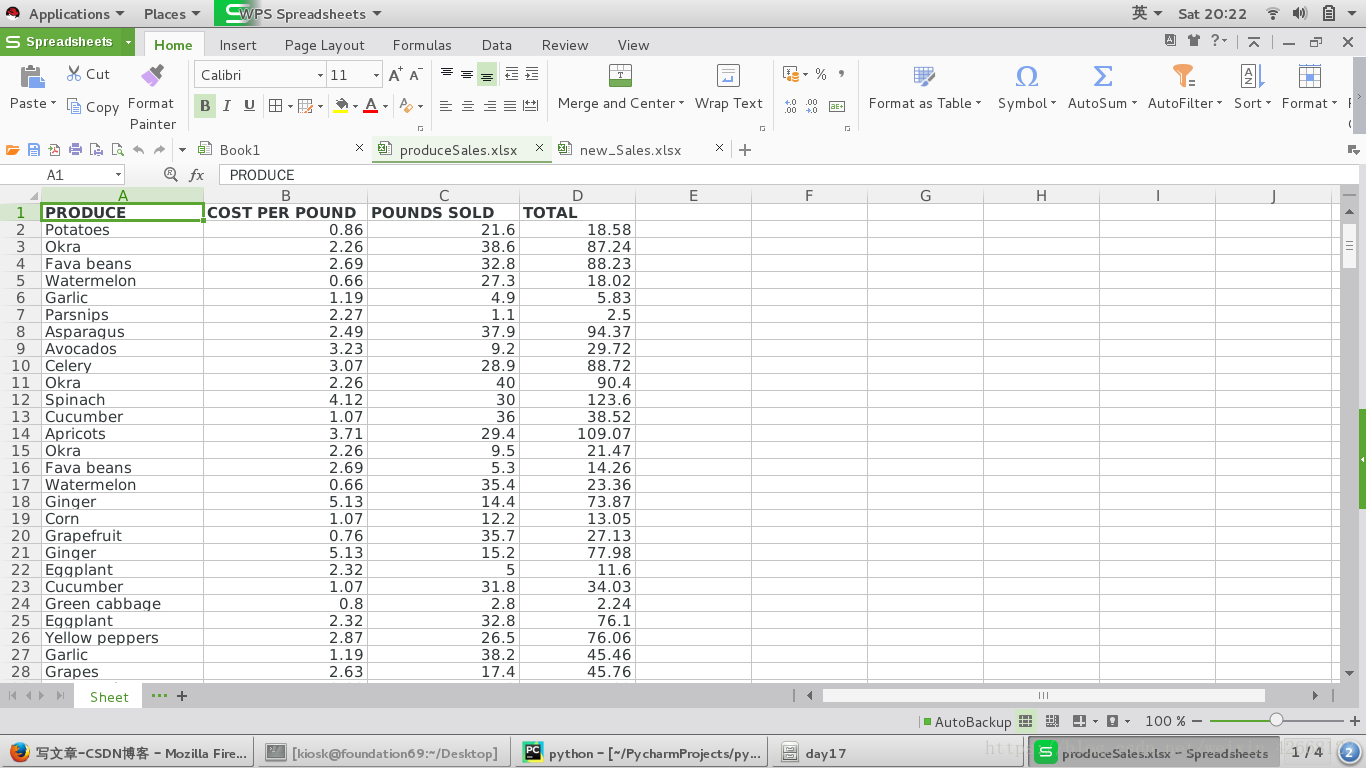
下载文件 : produceSales.xlsx
原文件打开情况:
1> 首先需要打开电子表格文件
2> 然后查找每一行内容,检查列 A (即列表的第一个索引)的值是不是 Celery、Garlic 或 Lemon
3> 如果是,更新列 B 中的价格(即列表第二个索引)
4> 最后将该表格保存为一个新的文件
import os
import openpyxl
def readwb(wbname, sheetname=None):
# 打开工作薄
wb = openpyxl.load_workbook(wbname)
# 获取要操作的工作表
if not sheetname:
sheet = wb.active
else:
sheet = wb[sheetname]
# 获取商品信息保存到列表中
all_info = []
for row in sheet.rows:
child = [cell.value for cell in row]
all_info.append(child)
if child[0] == 'Celery':
child[1] = 1.19
if child[0] == 'Garlic':
child[1] = 3.07
if child[0] == 'Lemon':
child[1] = 1.27
return all_info
def save_to_excel(data, wbname, sheetname='sheet1'):
"""
将信息保存到excel表中;
"""
print("写入Excel[%s]中......." % (wbname))
# 打开excel表, 如果文件不存在, 自己实例化一个WorkBook对象
wb = openpyxl.Workbook()
# 修改当前工作表的名称
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
for row, item in enumerate(data): # 0 [' BOOK', 50, 3]
for column, cellValue in enumerate(item): # 0 ' BOOK'
sheet.cell(row=row + 1, column=column + 1, value=cellValue)
# ** 往单元格写入内容
# sheet.cell['B1'].value = "value"
# sheet.cell(row=1, column=2, value="value")
# 保存写入的信息
wb.save(filename=wbname)
print("写入成功!")
data = readwb(wbname='/home/kiosk/Desktop/day17/produceSales.xlsx')
save_to_excel(data, wbname='new_Sales.xlsx', sheetname="商品信息")
表示写入新数据成功
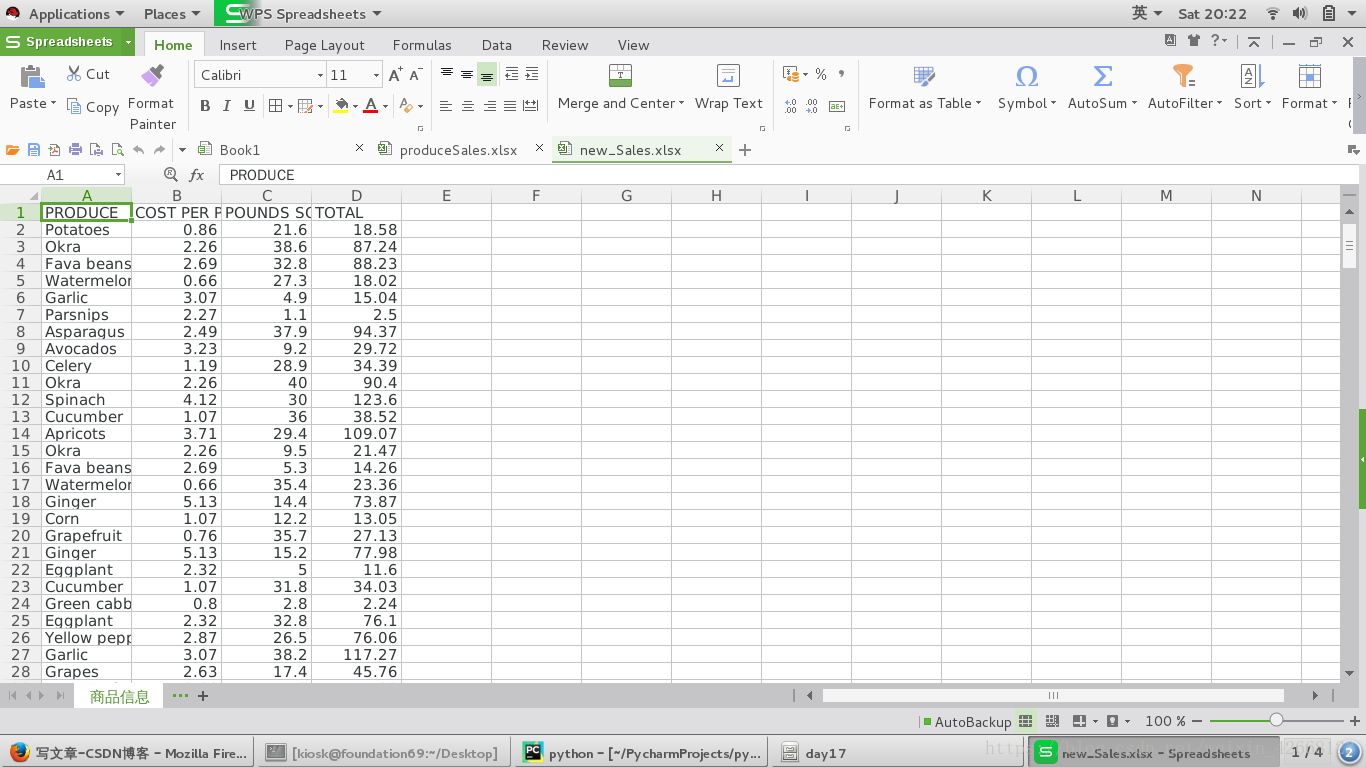
这是更改后的保存的新表格















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









