







环境:
WSL2
Ubuntu22.04
问题描述:
WSL2如何部署 Xinference

Xinference是一个用于加速和优化深度学习推理的平台。它提供了高性能、低延迟的推理解决方案,帮助开发者在生产环境中更高效地部署他们的深度学习模型。Xinference支持多种硬件平台,包括CPU、GPU和专用的AI加速器,同时提供了简单易用的API和工具,使用户能够轻松地集成和部署他们的模型。通过使用Xinference,开发者可以更快速地将他们的深度学习模型应用到实际应用中,提高推理性能和效率。
解决方案:
1.创建新的虚拟环境:
cd /mnt/e/work/
mkdir Xinference
cd Xinference
python3 -m venv Xinenv
2.激活虚拟环境:
source Xinenv/bin/activate

3.首先通过 PyPI 安装 Xinference:
pip install "xinference[all]"
大约20分钟
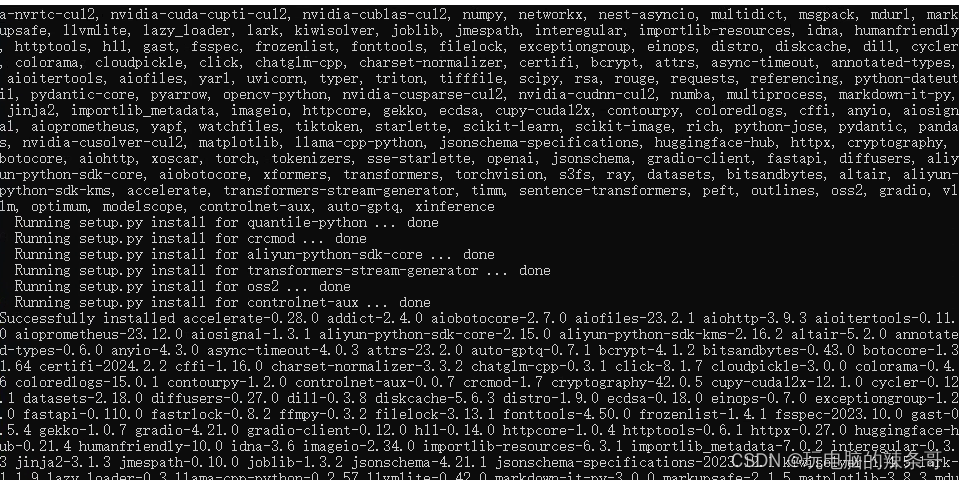
4.本地部署方式启动 Xinference:
xinference-local

5.Xinference 默认会在本地启动一个 worker,端点为:http://127.0.0.1:9997,端口默认为 9997。 默认只可本机访问,可配置 -H 0.0.0.0,非本地客户端可任意访问。 如需进一步修改 host 或 port,可查看 xinference 的帮助信息:xinference-local --help。
 6.默认情况下,Xinference 会使用 /.xinference 作为主目录来存储一些必要的信息,比如日志文件和模型文件,其中 就是当前用户的主目录。
6.默认情况下,Xinference 会使用 /.xinference 作为主目录来存储一些必要的信息,比如日志文件和模型文件,其中 就是当前用户的主目录。
你可以通过配置环境变量 XINFERENCE_HOME 修改主目录, 比如:
XINFERENCE_HOME=/tmp/xinference xinference-local --host 0.0.0.0 --port 9997
7.Xinference 也允许从其他模型托管平台下载模型。可以通过在拉起 Xinference 时指定环境变量,比如,如果想要从 ModelScope 中下载模型,可以使用如下命令:
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997
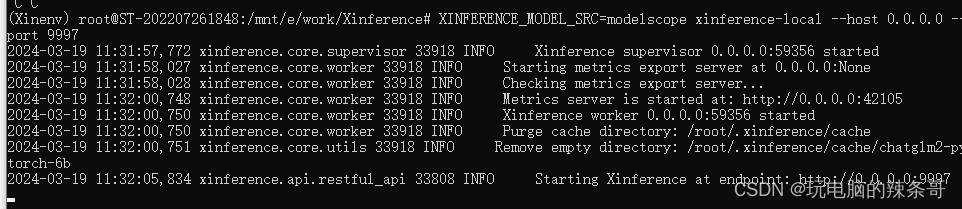
8.ctrl +c停止运行
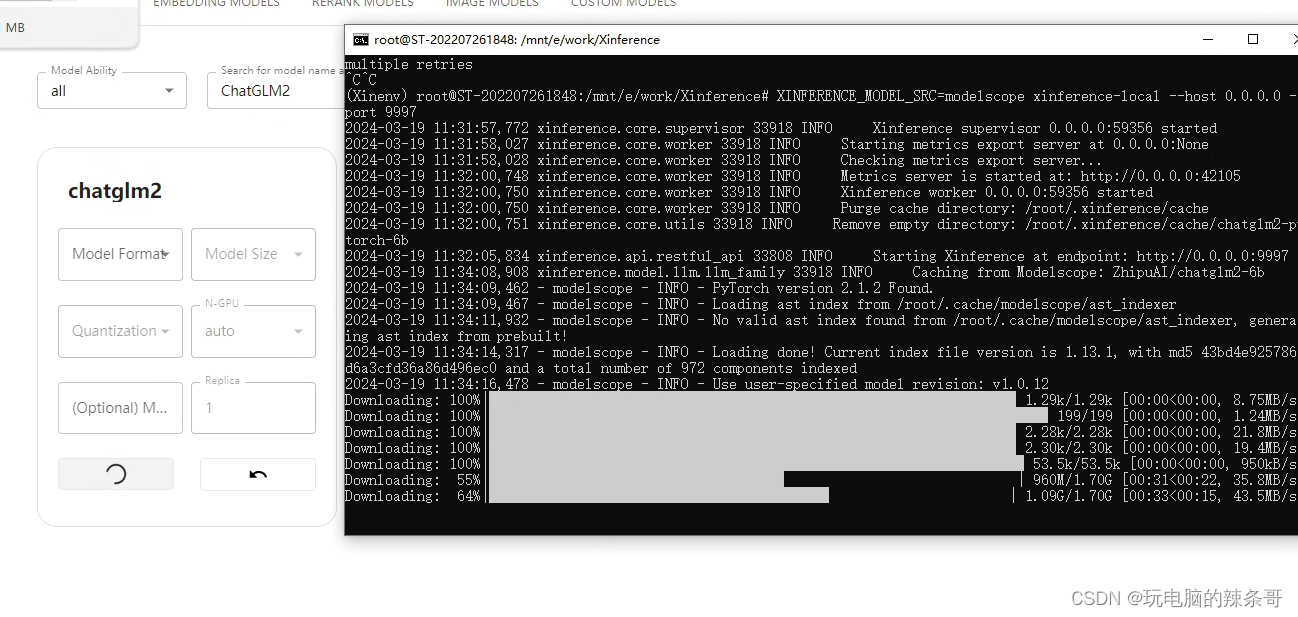 9.点击运行
9.点击运行
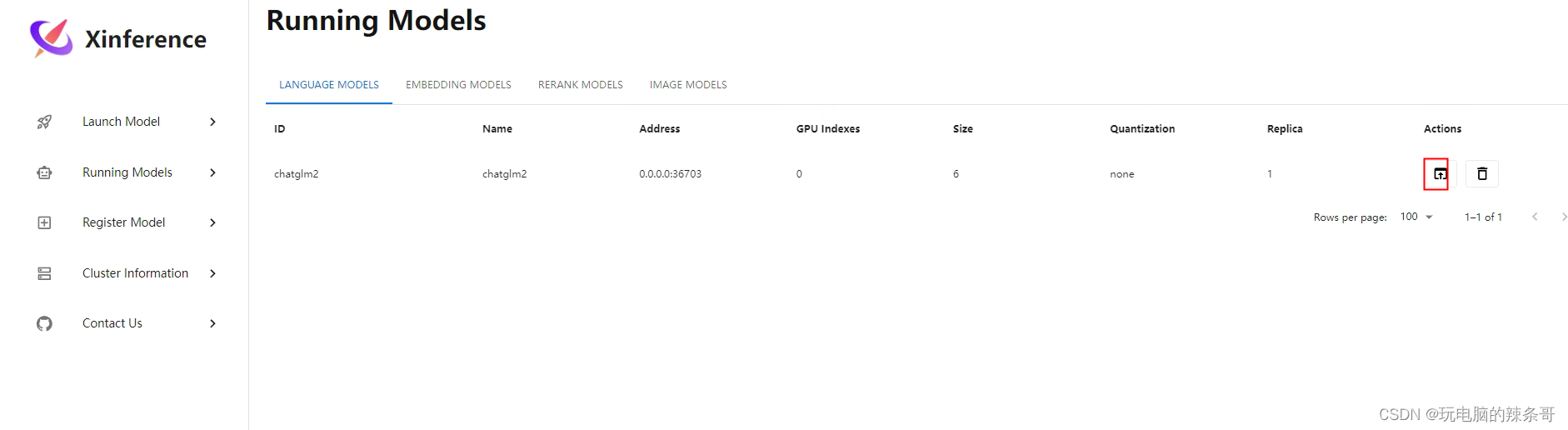
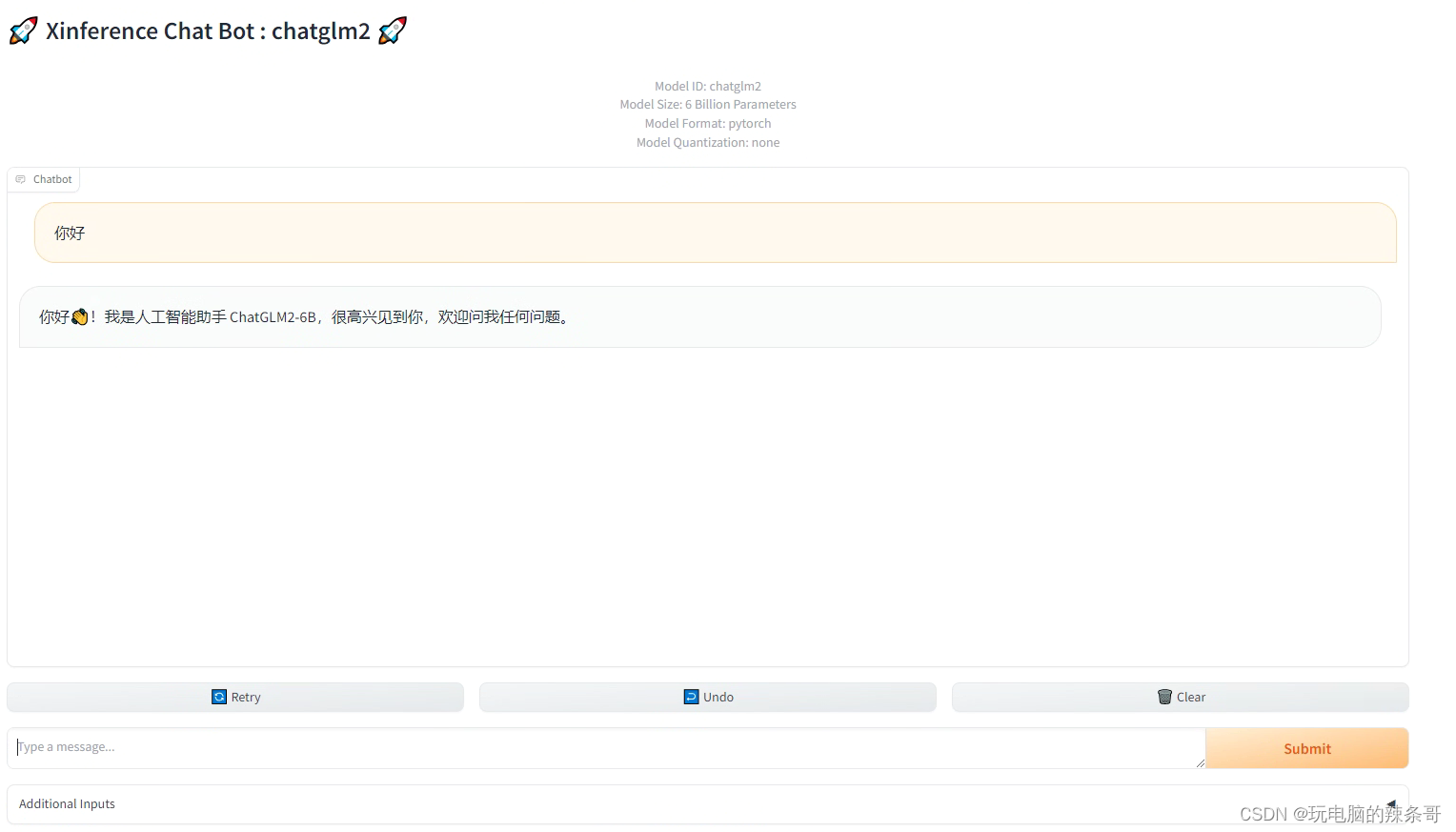
10.测试模型对话
docker一键部署
docker pull xprobe/xinference:latest
docker run -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
















 1851
1851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











