







 超级会员免费看
超级会员免费看
环境:
云服务器Ubuntu系统
2张 NVIDIA H20 96GB
Qwen2.5-VL-72B-Instruct-AWQ Qint4量化
AWQ 是 “Activation - Aware Weight Quantization” 的缩写,即激活感知权重量化。它是一种针对大型模型的先进量化算法,通过在权重量化过程中引入对激活值的感知,最小化量化误差对模型输出的影响,实现在保持模型精度的同时,提高压缩比和推理速度提升。
问题描述:
服务器有2张显卡,在别的虚拟环境部署运行了Xinference,然后又建个虚拟环境再部署一个可以吗?
目前 xinference 的策略是只能运行一个模型
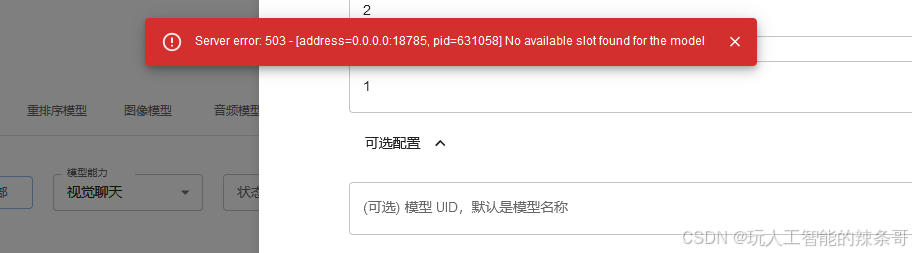
解决方案:
1. 可行性分析
- 硬件条件:2 张显卡(如 NVIDIA T4/A10G)可以分配给不同实例。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











