









环境:
python3.10
ollama v0.6.1
问题描述:
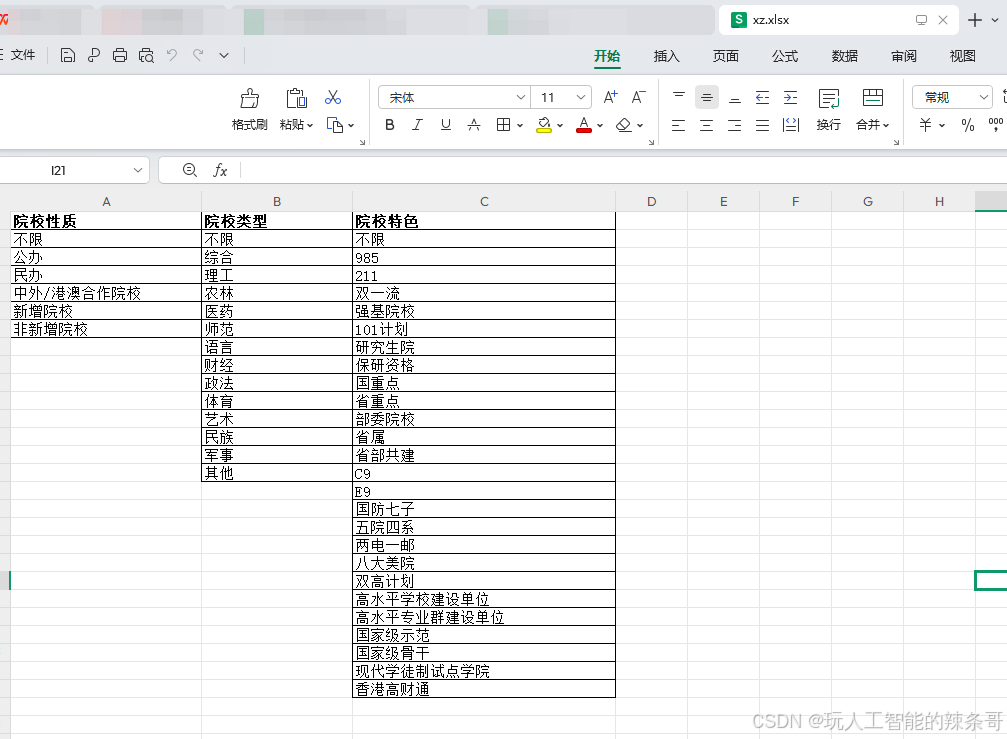
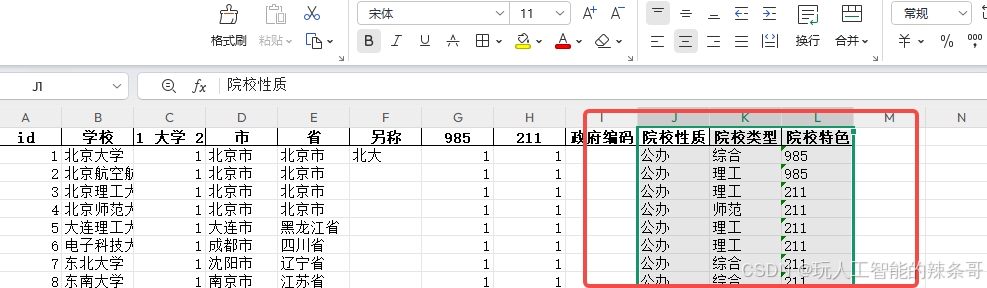
怎么使用python+本地大模型,根据tx.xlsx表格中B列学校对应J列院校性质、K列院校类型 L列院校特色,去xz.xlsx表格A列判断并找到对应A列院校性质、B列院校类型 C列院校特色数据填入tx.xlsx表格中J、K、L单元格,示例:北京大学 J列院校性质 是公办 K列院校类型 综合类 L列院校特色985.

解决方案:
利用本地部署的 Ollama 和 72B Qwen 大模型 这种方法可以通过自然语言处理(NLP)技术,动态分析学校名称并推断其属性,从而解决手动匹配和动态规则覆盖不全的问题。
以下是实现方法和代码:
实现思路
-
Ollama 和 Qwen 模型:
- 确保已经在本地部署了 Ollama,并加载了 72B Qwen 大模型。
- 使用 Qwen 模型的文本生成能力,根据学校名称推断其属性。
-
调用模型:
- 通过 API 或命令行调用 Ollama 的 Qwen 模型,输入学校名称,获取模型生成的属性描述。
- 解析模型输出,提取院校性质、院校类型和院校特色。
-
填充表格:
- 将模型推断的结果填入
tx.xlsx的 J、K、L 列。
- 将模型推断的结果填入
-
缓存机制:
- 为了提高效率,可以将已经匹配的学校名称和属性缓存起来,避免重复调用模型。
实现代码
以下是完整的 Python 脚本:
import pandas as pd
import requests
import json
# Ollama API 地址
OLLAMA_API_URL = "http://192.168.208.123:11434/api/generate"
# 缓存已匹配的学校名称和属性
school_cache = {}
# 调用 Ollama API 推断学校属性
def infer_school_properties(school_name):
if school_name in school_cache:
return school_cache[school_name]
# 构造提示词
prompt = f"根据学校名称推断其属性。学校名称:{school_name}。请返回以下属性:院校性质(公办/民办/不限)、院校类型(综合/理工/师范/财经/医药/不限)、院校特色(985/211/双一流/不限)。"
# 调用 Ollama API
try:
print(f"正在调用 Ollama API,学校名称:{school_name}")
response = requests.post(
OLLAMA_API_URL,
json={
"model": "qwen2.5:72b",
"prompt": prompt,
"stream": False
},
timeout=10
)
response.raise_for_status()
output = response.json()["response"].strip()
print(f"API 返回结果:{output}")
except Exception as e:
print(f"调用 Ollama API 失败:{e}")
return {"院校性质": "不限", "院校类型": "不限", "院校特色": "不限"}
# 解析模型输出
properties = {"院校性质": "不限", "院校类型": "不限", "院校特色": "不限"}
if "公办" in output:
properties["院校性质"] = "公办"
elif "民办" in output:
properties["院校性质"] = "民办"
if "综合" in output:
properties["院校类型"] = "综合"
elif "理工" in output:
properties["院校类型"] = "理工"
elif "师范" in output:
properties["院校类型"] = "师范"
elif "财经" in output:
properties["院校类型"] = "财经"
elif "医药" in output:
properties["院校类型"] = "医药"
if "985" in output:
properties["院校特色"] = "985"
elif "211" in output:
properties["院校特色"] = "211"
elif "双一流" in output:
properties["院校特色"] = "双一流"
# 缓存结果
school_cache[school_name] = properties
return properties
# 读取 tx.xlsx 文件
try:
print("正在读取 tx.xlsx 文件")
tx_df = pd.read_excel('tx.xlsx')
print("成功读取 tx.xlsx 文件")
print("列名:", tx_df.columns) # 打印列名
print(tx_df.head()) # 打印前几行数据
except Exception as e:
print(f"读取 tx.xlsx 文件失败:{e}")
exit()
# 遍历每一行,根据学校名称填充属性
for index, row in tx_df.iterrows():
school_name = row['学校'] # 使用实际的列名
print(f"正在处理学校:{school_name}")
properties = infer_school_properties(school_name)
tx_df.at[index, '院校性质'] = properties["院校性质"]
tx_df.at[index, '院校类型'] = properties["院校类型"]
tx_df.at[index, '院校特色'] = properties["院校特色"]
# 保存修改后的 tx.xlsx 文件
try:
print("正在保存文件")
tx_df.to_excel('tx_updated.xlsx', index=False)
print("数据处理完成,结果已保存到 tx_updated.xlsx")
except Exception as e:
print(f"保存文件失败:{e}")
示例
输入 tx.xlsx
| A | B | C | … | J | K | L |
|---|---|---|---|---|---|---|
| 1 | 北京大学 | … | … | |||
| 2 | 清华大学 | … | … | |||
| 3 | 未知学校 | … | … |
输出 tx_updated.xlsx
| A | B | C | … | J | K | L |
|---|---|---|---|---|---|---|
| 1 | 北京大学 | … | … | 公办 | 综合 | 985 |
| 2 | 清华大学 | … | … | 公办 | 理工 | 985 |
| 3 | 未知学校 | … | … | 不限 | 不限 | 不限 |
优化后脚本:
import pandas as pd
import requests
import json
import os
import re
# 先安装 debugpy:pip install debugpy
import debugpy
# 监听 5678 端口,等待IDE连接
#print("等待调试器 attach ...")
#debugpy.listen(("0.0.0.0", 5678))
#debugpy.wait_for_client()
#print("调试器已连接,可以执行远程命令")
# Ollama API 地址
OLLAMA_API_URL = "http://192.168.2.103:11434/api/generate"
# 缓存已匹配的学校名称和属性
school_cache = {}
# 断点保存文件
CHECKPOINT_FILE = "checkpoint.json"
# 调用 Ollama API 推断学校属性
def infer_school_properties(school_name):
if school_name in school_cache:
return school_cache[school_name]
# 构造提示词
prompt = (
f"根据学校名称推断其属性。学校名称:{school_name}。"
"请仅返回以下属性(用中文逗号分隔):"
"院校性质(不限、公办、民办、中外、港澳合作院校、新增院校、非新增院校),"
"院校类型(不限、综合、理工、农林、医药、师范、语言、财经、政法、体育、艺术、民族、军事、其他),"
"院校特色(不限、985、211、双一流、强基院校、101计划、研究生院、保研资格、国重点、省重点、部委院校、省属、省部共建、CE国防七子、五院四系、两电一邮、八大美院、双高计划、高水平学校建设单位、高水平专业群建设单位、国家级示范、国家级骨干、现代学徒制试点学院、香港高财通)。"
"例如返回格式:公办, 理工, 985"
)
# 调用 Ollama API
try:
print(f"正在调用 Ollama API,学校名称:{school_name}")
response = requests.post(
OLLAMA_API_URL,
json={
"model": "qwen2.5:72b",
"prompt": prompt,
"stream": False
},
timeout=10
)
response.raise_for_status()
output = response.json()["response"].strip()
print(f"API 返回结果:{output}")
except Exception as e:
print(f"调用 Ollama API 失败:{e}")
return {"院校性质": "不限", "院校类型": "不限", "院校特色": "不限"}
# 初始化默认值
properties = {"院校性质": "不限", "院校类型": "不限", "院校特色": "不限"}
# 定义所有可能的选项
院校性质列表 = ["不限", "公办", "民办", "中外", "港澳合作院校", "新增院校", "非新增院校"]
院校类型列表 = ["不限", "综合", "理工", "农林", "医药", "师范", "语言", "财经", "政法", "体育",
"艺术", "民族", "军事", "其他"]
院校特色列表 = ["不限", "985", "211", "双一流", "强基院校", "101计划", "研究生院", "保研资格",
"国重点", "省重点", "部委院校", "省属", "省部共建", "CE国防七子", "五院四系", "两电一邮",
"八大美院", "双高计划", "高水平学校建设单位", "高水平专业群建设单位", "国家级示范",
"国家级骨干", "现代学徒制试点学院", "香港高财通"]
# 拆分输出(按逗号或顿号或空格分割)
parts = re.split(r'[,,、\s]+', output)
parts = [p.strip() for p in parts if p.strip()]
# 尝试匹配每个属性
for p in parts:
if p in 院校性质列表 and properties["院校性质"] == "不限":
properties["院校性质"] = p
elif p in 院校类型列表 and properties["院校类型"] == "不限":
properties["院校类型"] = p
elif p in 院校特色列表 and properties["院校特色"] == "不限":
properties["院校特色"] = p
# 缓存结果
school_cache[school_name] = properties
return properties
# 保存断点
def save_checkpoint(index, df):
checkpoint = {
"last_index": index,
"data": df.to_dict(orient="records")
}
with open(CHECKPOINT_FILE, "w", encoding="utf-8") as f:
json.dump(checkpoint, f, ensure_ascii=False, indent=2)
print(f"已保存断点,最后处理的行索引:{index}")
# 加载断点
def load_checkpoint():
if os.path.exists(CHECKPOINT_FILE):
with open(CHECKPOINT_FILE, "r", encoding="utf-8") as f:
checkpoint = json.load(f)
return checkpoint["last_index"], pd.DataFrame(checkpoint["data"])
return 0, None
# 读取 tx.xlsx 文件
try:
print("正在读取 tx.xlsx 文件")
tx_df = pd.read_excel('tx.xlsx')
print("成功读取 tx.xlsx 文件")
print("列名:", tx_df.columns) # 打印列名
print(tx_df.head()) # 打印前几行数据
except Exception as e:
print(f"读取 tx.xlsx 文件失败:{e}")
exit()
# 加载断点
start_index, checkpoint_df = load_checkpoint()
if checkpoint_df is not None:
tx_df = checkpoint_df
print(f"从断点继续执行,最后处理的行索引:{start_index}")
# 遍历每一行,根据学校名称填充属性
for index, row in tx_df.iterrows():
if index < start_index:
continue # 跳过已处理的行
school_name = row['学校'] # 使用实际的列名
print(f"正在处理学校:{school_name}")
properties = infer_school_properties(school_name)
tx_df.at[index, '院校性质'] = properties["院校性质"]
tx_df.at[index, '院校类型'] = properties["院校类型"]
tx_df.at[index, '院校特色'] = properties["院校特色"]
# 每处理 50 条保存一次
if (index + 1) % 50 == 0:
save_checkpoint(index, tx_df)
# 保存最终结果
try:
print("正在保存文件")
tx_df.to_excel('tx_updated.xlsx', index=False)
print("数据处理完成,结果已保存到 tx_updated.xlsx")
# 删除断点文件
if os.path.exists(CHECKPOINT_FILE):
os.remove(CHECKPOINT_FILE)
print("断点文件已删除")
except Exception as e:
print(f"保存文件失败:{e}")
运行脚本
- 确保已安装
pandas库,并正确部署了 Ollama 和 Qwen 模型。 - 将脚本保存为
update_excel_with_ollama.py,并确保tx.xlsx文件与脚本在同一目录下。 - 运行脚本:
python update_excel_with_ollama.py - 处理结果将保存到
tx_updated.xlsx文件中。
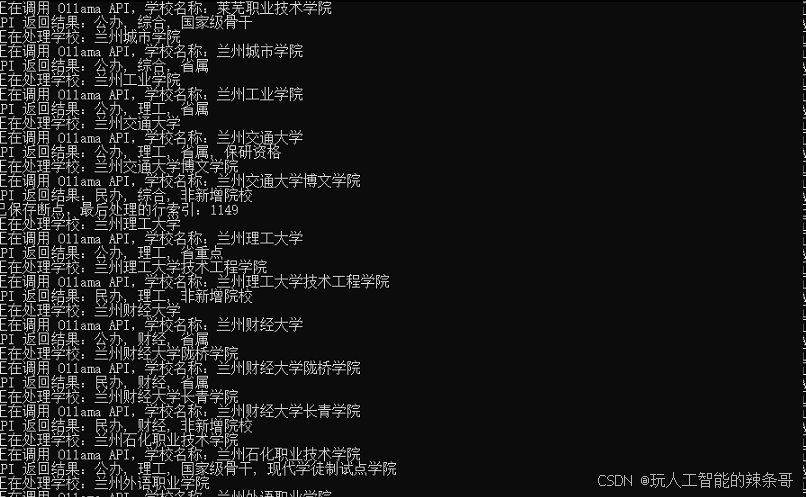
用时1小时多完成3138条数据匹对
注意事项
-
模型调用速度:
- 调用本地模型可能需要一定时间,建议对大量数据时优化调用逻辑或使用缓存机制。
-
模型输出解析:
- 需要根据模型的实际输出调整解析逻辑,确保提取的属性准确。
-
错误处理:
- 如果模型调用失败或输出不符合预期,可以捕获异常并填入默认值。



















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











