







传统方法
1.传统的认证方法集中通过声波图特征区分个体,但不能处理掺假攻击。bob这个用户对着智能手机说话的话,系统录下他的声音,传送到语音验证系统,就可以知道是bob。
2.对于攻击者,使用扬声器通过replay、Sythesis、Conversion向手机播放语音,系统记录并传送语音信号,如果语音信号足够好,系统将攻击者视为bob。
文字处理方法是寻找用户与攻击者信号的差异,如果使用高质量的设备,通过技术提高转化率,两者信号的差异很小,系统难以检测到信号。

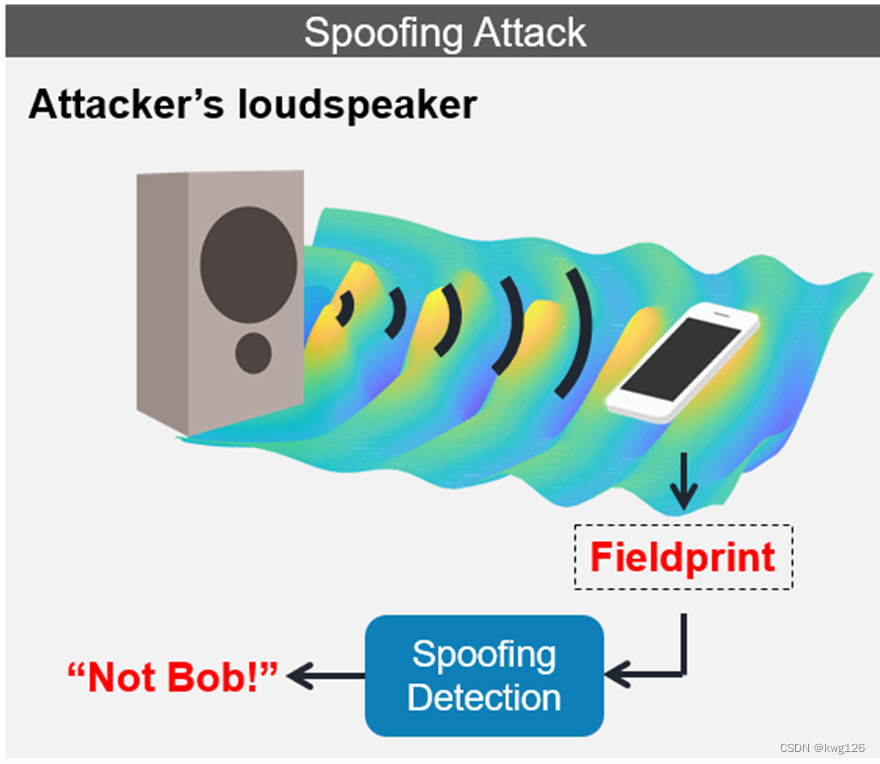
Fieldprint
1.无论是用户还是扬声器,实际上都制造了"Fieldprint",因此从该图像中可以看出用户的声音与攻击者不同,我们将"场打印"发送到探测系统,很容易区分攻击者。即使攻击者可以发出与用户非常相似的声音,也很难复制"Fieldprint"

Cafield
Cafield是一种基于现场打印的掺假检测系统。
CaField由信号处理、现场打印提取、现场打印匹配、决策逻辑等4个主要模块组成。
上面是注册模式,下面是认证模式。 智能手机上的两个麦克风同时记录用户的语音输入。
在注册模式下,利用目标说话者的特征向量训练说话者模型。
通过将认证模式下未知说话者提取的特征向量与突出显示的身份模型进行比较来给出评分。 如果分数比预定分数高,就要验证说话者的身份,否则就拒绝。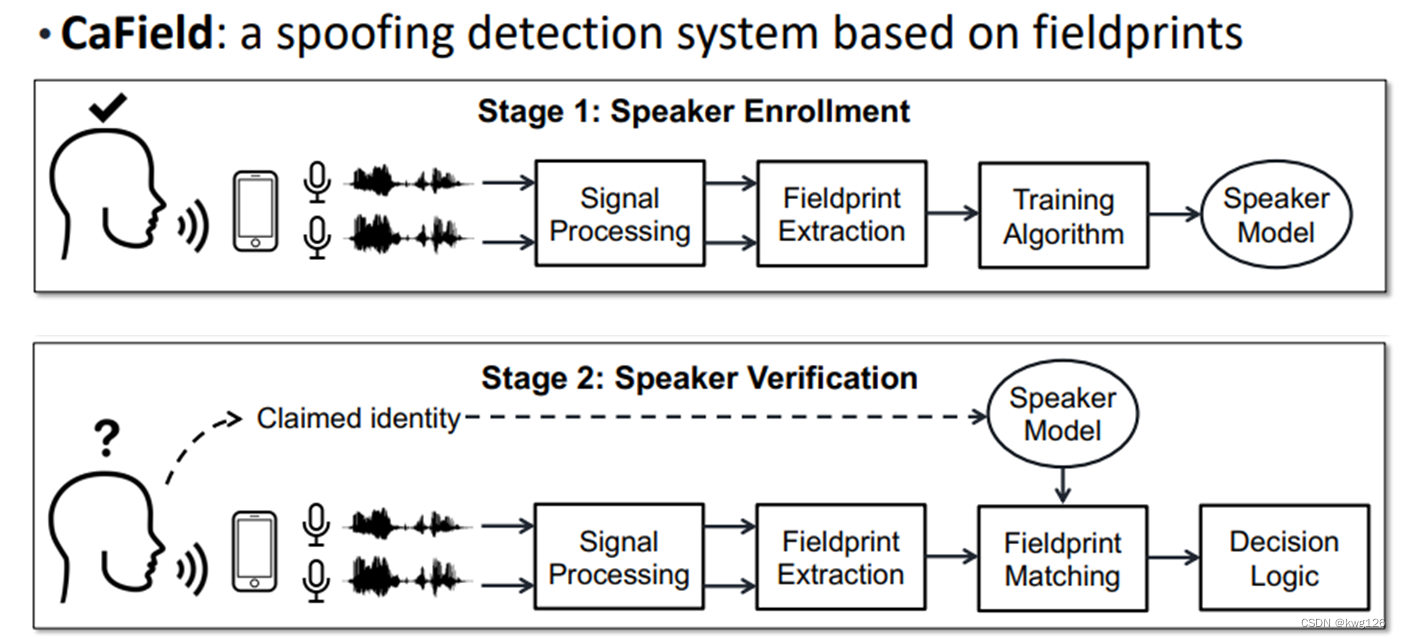
短时傅里叶变换
1.在信号处理中,我们还使用短时傅里叶变换对负波形图进行了光谱转换,以下为例子。
这是周期性的语音波形图。
2.第一步是将周期性函数分解为多组正余弦函数。

3. 第二步将所有正余弦函数置于第三轴。

4.5.第三步是旋转坐标轴,将第三轴的坐标旋转到横轴上,就完成了short-time Fourier transform。


6.这是短时间Fourier Transform的三维图。
从正面看是阴性波形图,从侧面看是光谱图。
Fieldprint
信号处理好了,我们就开始Fidleprint了。
这是五个场元音素的"Fieldprint"和消除噪音的Fieldprint,以进行更明确的观察。 它表明音素的Fieldprint不同,这是对文本无关性的挑战。
2. 因此,提出了Long-Time Average Fieldprint来解决这一问题。这基本上是不同Fieldprint的平均值。
我们提出了这个想法,因为我们发现人的声音可以接近更大的声音平衡状态。
3.此处考察该因素持续时间的影响。 该图显示了5个句子相邻时间之间的LTAF的欧几里得距离,并发现随着时间的推移,LTAF的值也越来越稳定。
我们录制了用户所说的5个不同的句子,选择了1.2~1.6秒的LTAF。尽管这些句子存在差异,但它们的"场打印"看起来非常相似,尤其是在不到4,000赫兹的情况下。
4. 高斯混合模型(GMM)采用机器学习算法进行频繁匹配。 模型根据概率分布将数据分类为不同的类别。使用高斯混合模型学习用户的统计分布功能,验证计算的似然值,比较预定义的阈值。
评估
我们使用八个扬声器收集了二十名参与者的马匹,包括14名女性和14名男性。
在整个评价过程中,采用以下指标。
准确性:衡量系统接受和拒绝合法用户。
错误合格率(False Acceptance Rate) : 错误视为攻击者被系统用户的比率 。
错误拒绝率(False Rejection Rate):用户拒绝率系统错误拒绝率。
相同错误率(Equal Error Rate):显示 FAR 和 FRR 的平衡图。
总准确率为99.16%,错误合格率为0.82%,错误拒绝率为0.97%,相同错误率为0.85%。结果发现,系统在拒绝接受和冒充实际用户方面非常有效。
1.该图显示了三个扬声器的现场打印,其中一个人和人声完全相同。下图显示了五个人说同样话的现场打印。如果将这两幅画与一个人的"field print"进行比较,就可以看出人和人、人和扬声器直接不同。
2.20名参与者的特征向量是利用概率邻居嵌入降低分量的画面。 结果表明,通过现场打印可以区分各种人类说话者。
 结论
结论
cafield的攻击检测能力很强。
在多国语言应用程序中也可以使用cafield。
虽然只要有手机就可以检测到,但是手机离得太远的话效果会下降。
如果呆在有回声的小房间里就会受到影响,用户和手机之间有遮挡也会受到影响。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









