






MySQL 主从架构原理
一. 主从架构基本原理
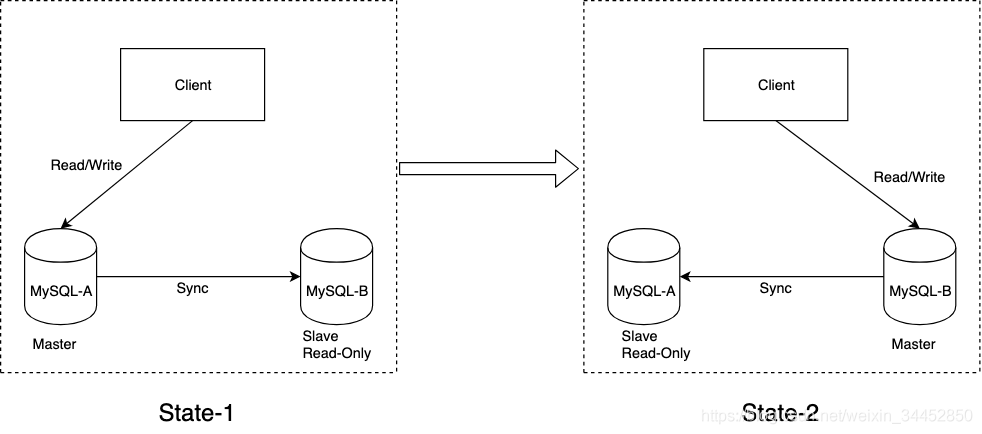
上图展示的是 MySQL 的主从切换流程。在 State-1 中,客户端的读写都直接访问节点 A,而节点 B 是 A 的备库,只是将 A 的更新都同步过来,到本地执行。这样可以保持节点 B 和 A 的数据是相同的。当需要切换的时候,就切成状态 2。这时候客户端读写访问的都是节点 B,而节点 A 是 B 的从库。
在主从架构下,建议把从库设置为 Read-Only 模式,这样做有以下几个考虑:
有时候一些运营类的查询语句会被放到备库上去查,设置为只读可以防止误操作;
防止切换逻辑有 bug,比如切换过程中出现双写,造成主备不一致;
可以根据 Read-Only 状态,来判断节点的角色。
可以通过命令来查看当前 MySQL 实例的 Read-Only 状态:
show global variables like 'read_only';
开启当前实例的 Read-Only 状态:
set global read_only=1;
Read-Only 模式对超级权限用户 (super) 是无效的,而用于同步更新的线程,就拥有超级权限。因此,从库可以正常同步主库的数据。
二. 主从架构下的更新操作流程
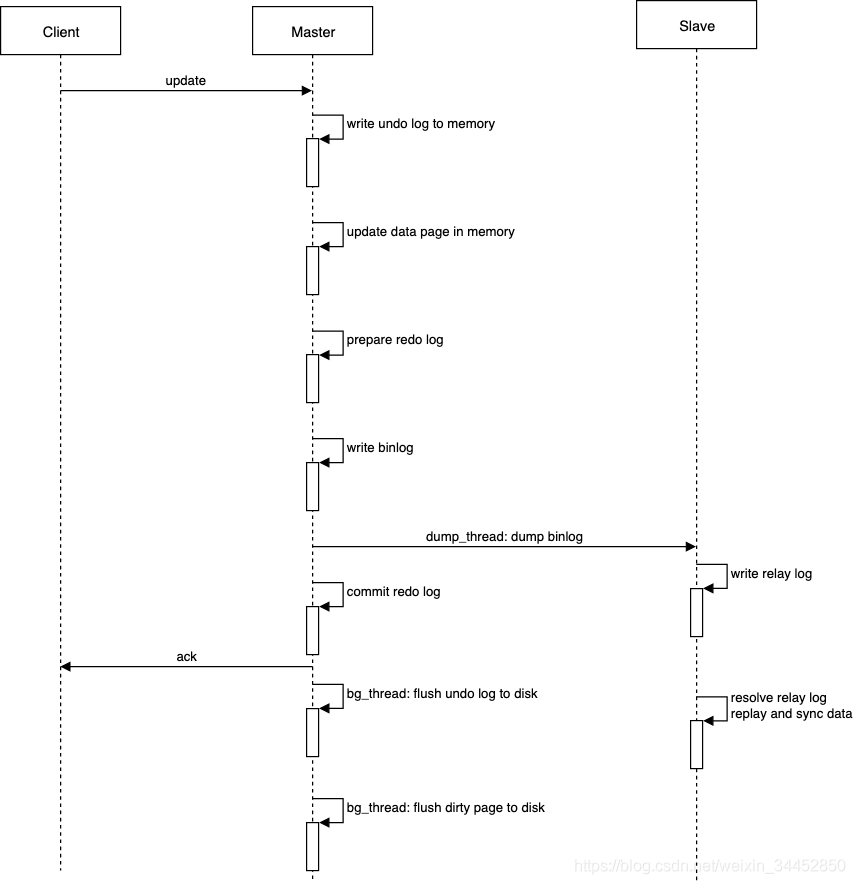
当 Master 收到一条客户端的更新操作后,其大致的执行流程如下:
Master Server将 undo log 写入内存。
Master Server更新内存中的数据页。
Master InnoDB 写入 redo log,并将redo log 置为 prepare 状态。
Master Server 写入 binlog 。Master 和 Slave 之间维持了一个长连接,且 Master 内部有一个线程专门用于服务这个长连接。Master 的 binlog 写入成功后,会由一个 dump_thread 线程将 binlog 导出并同步到 Slave。
Slave 收到 binlog 后,会将 binlog 写到本地文件,称为中转日志(relay log)。
Slave 内部有一个 sql_thread 线程,它会读取 relay log ,解析出日志里的命令并进行重放执行,这样就实现了主从数据同步。
Master 的 binlog 写入成功后,InnoDB 会提交 redo log。之后会给客户端 ACK,返回更新操作成功。
Master 内部有一个后台线程 bg_thread,它会定期将内存中的 undo log 写入磁盘,同时将内存脏页刷盘。
三. 关于 binlog
从上述主从同步的流程看,binlog 是至关重要的。实际上,MySQL 几乎所有的高可用架构,都直接依赖于 binlog。
binlog 有几种格式,可以通过命令查看:
show variables like '%binlog_format%';
statement
**当 binlog_format=statement 时,binlog 里面记录的就是 SQL 语句的原文。**由于 statement 格式下,记录到 binlog 里的是语句原文,因此可能会出现这样一种情况:在主库执行这条 SQL 语句的时候,用的是索引 a;而在备库执行这条 SQL 语句的时候,却使用了索引 b。因此 statement 格式是有风险的,可能会造成主从数据不一致,对于数据一致性要求较高的场景并不适用。
row
**当 binlog_format=row 时,binlog 会记录下每一行数据被修改的细节。**这样就不会出现数据不一致的情况,但是会造成 binlog 日志量会很大,特别是当执行 alter table 之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。
mixed
由于 statement 格式有数据不一致的风险,而 row 格式会造成日志文件特别大,因此出现了 mixed 格式。mixed 格式的意思是,MySQL 自己会判断这条 SQL 语句是否可能引起主备不一致,如果有可能,就用 row 格式,否则就用 statement 格式。
四. 主从同步延迟
主从延迟简介
正常情况下,只要主库执行更新生成的所有 binlog,都可以传到备库并被正确地执行,备库就能达到跟主库一致的状态,这就是最终一致性。但是,MySQL 要提供高可用能力,只有最终一致性是不够的,主从同步延迟是必须要考虑的问题。
在主从同步的过程中,有3个比较重要的时间点:
Master 执行完成一个事务,写入 binlog,这个时刻记为 T1;
Master 将 binlog 发送给 Slave ,Slave 接收完这个 binlog 的时刻记为 T2;
Slave 执行完成这个事务,这个时刻记为 T3。
所谓主从同步延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是上面的 T3-T1。
可以在 Slave 上执行 show slave status 命令,它的返回结果里面会显示 seconds_behind_master,用于表示当前 Slave 的数据延迟了多少秒。
需要说明的是,在网络正常的时候,日志从 Master 传给 Slave 所需的时间是很短的,即 T2-T1 的值是非常小的。也就是说,网络正常情况下,主从延迟的主要来源是 Slave 接收完 binlog 和执行完这个事务之间的时间差。
所以说,主从同步延迟最直接的表现是,Slave 消费中转日志(relay log)的速度,比 Master 生产 binlog 的速度要慢。下面我们来分析下,主从同步延迟的产生原因有哪些。
产生主从延迟的原因
Slave 所在的机器性能比 Master 差
在生产环境下,建议所以主库和从库都选用相同规格的机器,并且做对称部署,因为主备可能发生切换,Slave 随时可能切换成 Master。
Slave 的查询压力过大
如果 Slave 承担了过多的查询、分析类请求,就可能耗费大量的 CPU 资源,影响数据同步速度,进而造成主从同步延迟。
针对这种情况,可以考虑采用一主多从架构,让多个从库来共同分担读请求的压力。
大事务
如果一个大事务在主库上执行了 10 分钟,那这个事务很可能就会导致主从延迟 10 分钟。因此应该尽量避免大事务操作,比如一次删除大量的数据,或者大表的 DDL 等。
五. 主从切换策略
由于主从同步延迟的存在,所以在主从切换的时候,就相应的有不同的策略。
可靠性优先策略
具体步骤:
判断 Slave 当前的 seconds_behind_master,如果小于某个值(比如 5 秒)继续下一步,否则持续重试这一步;
把 Master 修改为只读状态,即把 Read-Only 设置为 true;
判断 Slave 的 seconds_behind_master 的值,直到这个值变成 0 为止;
把 Slave 改成可读写状态,也就是把 readonly 设置为 false;
把业务请求切到原来的 Slave (新 Master)。
可以看到,这个切换流程中是有不可用时间的。因为在步骤 2 之后,Master 和 Slave 都处于 Read-Only 状态,也就是说这时系统处于不可写状态,直到步骤 5 完成后才能恢复。
在这个不可用状态中,比较耗费时间的是步骤 3,可能需要耗费好几秒的时间。这也是为什么需要在步骤 1 先做判断,确保 seconds_behind_master 的值足够小。
这种方式为了保证主从数据的一致性,导致数据库可能出现一段不可写的时间,称为可靠性优先策略。
可用性优先策略
如果强行把上面的步骤 4、5 调整到最开始执行,也就是说不等主从数据同步,直接把连接切到 Slave 上,并且让 Slave 可以读写,那么系统几乎就没有不可用时间了。这种策略就是可用性优先。而这个策略的代价,就是可能出现数据不一致的情况。
可用性优先策略可能会导致数据不一致。因此,大多数情况下,都建议你使用可靠性优先策略。毕竟对数据服务来说的话,数据的可靠性一般还是要优于可用性的。















 2828
2828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









