







根据数据结构不同的排序算法
在STL中根据容器类型的不同,排序规则也有所区别。
- 序列式容器
vector,deque,array等可以通过sort进行排序。因为查看std::sort的接口可以发现,他要求传入的容器迭代器类型为RandomAccessIterator。

而常用的容器的迭代器类型继承关系如下
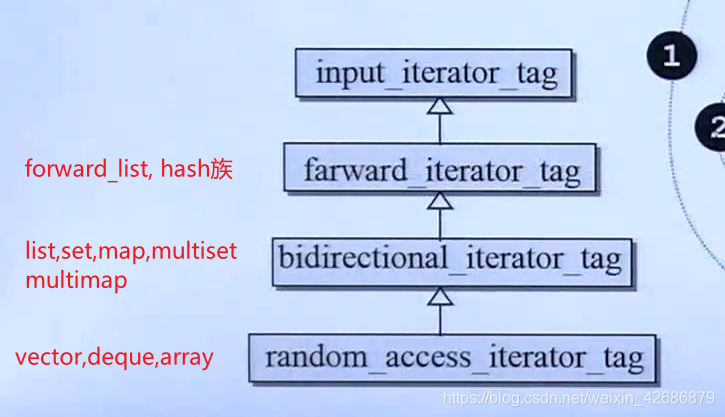
因此,对于关联式容器或者链表list,当我们需要插入自定义数据类型时,我们需要给定内部的排序规则。
接下来就逐一展开描述
STL中algorithm提供的sort函数
已经有许多现成的学习资料,我就不重复过多。
【C++&Leetcode】浅析map与sort的自定义排序
需要注意以下几个问题:
-
sort函数传入的自定义比较规则可以是两种类型
- 函数指针
- 函数对象
因此,我们通常可以采用三种方式设定自己的规则
//1. 构造仿函数
struct comp{
bool operator()(const T& lhs, const T& rhs)
{
//逻辑实现
}
} myComp; //这时候可以自动创建一个myComp对象
//2. 构造一个普通的bool函数
bool compFunc(const T& lhs, const T& rhs)
{
//逻辑实现
}
//3. 直接在传入参数的时候,构建一个lambda函数
//(这个操作显得比较高端,适合只需要定义一次排序规则的时候)
这时候,在我们的排序函数sort中就可以有如下的几种调用形式
vector<T> vec;
//vec的一些赋值操作
sort(vec.begin(), vec.end(), myComp); //传入创建好的函数对象
sort(vec.begin(), vec.end(), comp()); //通过class()生成临时函数 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









