







前文:
hudi一般用作ods入湖使用;公司简单业务展示。
一、心得
1.资源:使用大部分离线数据可通过spark-hudi入库,流量日志可用flink-hudi;
2.业务:流量日志通过生成分布式雪花id方便下游追踪数据;曝光数据由于业务原因需要解析;如果采用nginx日志涉及多次url解码问题;
3.技术:采集json数据入库,可以通过配置表实现代码通用;
初始化使用bulk_insert入湖(并行度调大点);后续用 流量数据 insert,业务数据 update;
二、入湖示例
2.0 采集方案示例
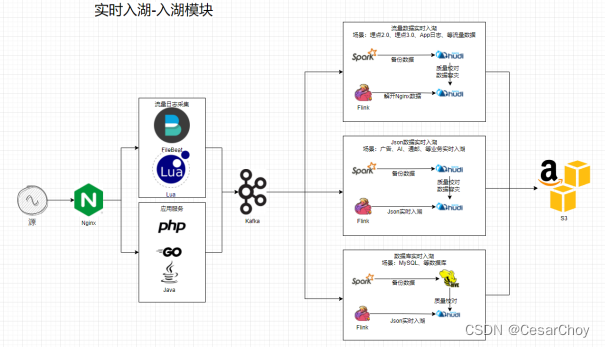
三种格式:JSON入湖、流量数据入湖、MySQL等业务库数据入湖
2.1 hudi 配置
public class HudiConfig {
public String db;
public String tableName;
public String topic;
public String startupMode;
public String specificOffsets;
public String recordKey;
public String precombineKey;
public String writeOperation;
public String indexBootstrap;
public String indexGlobal;
public String dropDuplicates;
public String indexTTL;
public String writeTasks;
public String writeBucketAssign;
public String writeTaskMaxSize;
public String writeBatchSize;
public String partitionKey;
public String javaBeanClass;
public HudiConfig(ParameterTool parameterTool) {
db = parameterTool.get("db", "");
tableName = parameterTool.get("table", "");
topic = parameterTool.get("topic", "");
// 消费kafka的开始位点,specific-offsets,latest-offset,earliest-offset,group-offsets
startupMode = parameterTool.get("scan.startup.mode", "group-offsets");
// 如果消费位点是specific-offsets那就需要填,partition:0,offset:29841814;partition:1,offset:29841848;partition:2,offset:29841821
specificOffsets = parameterTool.get("scan.startup.specific-offsets", "");
// hudi 主键
recordKey = parameterTool.get("hoodie.datasource.write.recordkey.field", "");
// hudi 的对比字段
precombineKey = parameterTool.get("write.precombine.field", "ts");
// insert,upsert
writeOperation = parameterTool.get("write.operation", "upsert");
// 是否索引加载
indexBootstrap = parameterTool.get("index.bootstrap.enabled", "false");
// 是否全局索, true就是多 partition 去重
indexGlobal = parameterTool.get("index.global.enabled", "true");
// 是否去重,如果insert模式主键不唯一给false,否则主键相同会去重
dropDuplicates = parameterTool.get("write.insert.drop.duplicates", "true");
// 索引保留时间
indexTTL = parameterTool.get("index.state.ttl", "0.5D");
// 写的并行度,不会影响初始文件格式
writeTasks = parameterTool.get("write.tasks", "3");
// 写的并行度,会影响初始文件个数
writeBucketAssign = parameterTool.get("write.bucket_assign.tasks", "1");
writeTaskMaxSize = parameterTool.get("write.task.max.size", "512D");
writeBatchSize = parameterTool.get("write.batch.size", "128D");
partitionKey = parameterTool.get("partition_key", "dctime");
javaBeanClass = parameterTool.get("java.bean.class", "");
}
}2.2 写入 kafka
public class BeanKafkaToHudi {
public static StreamExecutionEnvironment env = null;
public static StreamTableEnvironment tableEnv = null;
public static ParameterTool parameterTool;
public static boolean isProd;
public static HudiConfig hudiConfig;
public static void main(String[] args) throws ClassNotFoundException {
parameterTool = ParameterTool.fromArgs(args);
System.out.println("参数为:" + parameterTool.toMap());
isProd = parameterTool.getBoolean("is_prod", false);
hudiConfig = new HudiConfig(parameterTool);
// 初始化环境
FlinkUtils.initEnv(isProd, true);
env = FlinkUtils.env;
tableEnv = FlinkUtils.tableEnv;
new BeanKafkaToHudi().run();
}
public void run() throws ClassNotFoundException {
Class javaBeanClass = Class.forName(hudiConfig.javaBeanClass);
FlinkSqlUtils.initPojoToSql(javaBeanClass);
increment();
}
private void increment() {
createKafkaTable();
createHudiTable();
String insertHudi = "insert into flink_catalog." + hudiConfig.tableName +
" select " + FlinkSqlUtils.jointFieldSql +
" from flink_catalog.source_" + hudiConfig.tableName;
System.out.println("插入数据语句:\n" + insertHudi);
tableEnv.executeSql(insertHudi);
}
private void createHudiTable() {
String hudiTableSql = "CREATE TABLE IF NOT EXISTS flink_catalog." + hudiConfig.tableName + "(\n" +
FlinkSqlUtils.jointCreateFieldSql +
")\n" +
"PARTITIONED BY (" + hudiConfig.partitionKey + ")\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 's3://bgapps/apps/hive/warehouse/" + hudiConfig.db + ".db/" + hudiConfig.tableName + "',\n" +
" 'table.type' = 'COPY_ON_WRITE',\n" +
" 'write.operation' = '" + hudiConfig.writeOperation + "',\n" +
" 'write.precombine.field' = '" + hudiConfig.precombineKey + "',\n" +
" 'hoodie.datasource.write.recordkey.field' = '" + hudiConfig.recordKey + "',\n" +
" 'hive_sync.table'='" + hudiConfig.tableName + "',\n" +
" 'hive_sync.db'='" + hudiConfig.db + "', \n" +
" 'write.tasks' = '" + hudiConfig.writeTasks + "',\n" +
" 'write.bucket_assign.tasks' = '" + hudiConfig.writeBucketAssign + "',\n" +
" 'hive_sync.enable' = 'true',\n" +
" 'hive_sync.mode' = 'hms',\n" +
" 'hive_sync.metastore.uris' = 'thrift://ip1:9083,thrift://ip2:9083,thrift://ip3:9083',\n" +
" 'index.bootstrap.enabled' = '" + hudiConfig.indexBootstrap + "',\n" + //是否索引加载
" 'index.global.enabled' = '" + hudiConfig.indexGlobal + "',\n" + //true就是多 partition 去重,原理是先删除再新增
" 'write.insert.cluster' = 'true',\n" +//insert 模式合并小文件,合并作用不大
" 'write.insert.drop.duplicates' = '" + hudiConfig.dropDuplicates + "',\n" + // true 会去重,insert模式给false
" 'index.state.ttl' = '" + hudiConfig.indexTTL + "',\n" + //索引保留时间
" 'hoodie.cleaner.policy' = 'KEEP_LATEST_FILE_VERSIONS',\n" +
" 'hoodie.cleaner.fileversions.retained' = '24'\n" +
")";
System.out.println("建hudi表:\n" + hudiTableSql);
tableEnv.executeSql(hudiTableSql);
}
private void createKafkaTable() {
String createKafkaSql = "CREATE TABLE IF NOT EXISTS flink_catalog.source_" + hudiConfig.tableName + "(\n" +
FlinkSqlUtils.jointCreateFieldSql +
")\n" +
"WITH (" +
" 'connector' = 'kafka',\n" +
" 'topic' = '" + hudiConfig.topic + "',\n" +
" 'properties.bootstrap.servers' = 'kafka1.bigdata:9092,kafka2.bigdata:9092,kafka3.bigdata:9092',\n" +
" 'scan.startup.mode' = '" + hudiConfig.startupMode + "',\n" + //specific-offsets
" 'scan.startup.specific-offsets' = '" + hudiConfig.specificOffsets + "',\n" +
" 'properties.group.id' = 'flink_on_hudi',\n" +
" 'format' = 'json'\n" +
")";
System.out.println("kafka建表语句:\n" + createKafkaSql);
tableEnv.executeSql(createKafkaSql);
}
}
关闭索引,只保留一个版本,并行度一般设置3即可。
当 'write.operation' = 'bulk_insert' 时,可调优 'write.bulk_insert.sort_by_partition' = 'false'。
2.3 job提交
job_name="xxx.hudi.BeanKafkaToHudi"
app_name="flink_kafka_to_hudi_dr_banner_origin"
class_name="xxx.hudi.BeanKafkaToHudi"
topic=collect_dr_event_exposure_origin
table=${topic}_realtime
write_recordkey_field=snowflake_id
write_precombine_field=add_time_ms
db=event_log
write_operation=upsert
write_bucket_assign_tasks=3
write_insert_drop_duplicates=true
scan_startup_mode=earliest-offset
is_prod=true
source ~/.bashrc
/opt/flink/soft/flink-1.12.5/bin/flink run-application -t yarn-application \
-Dyarn.application.name="$app_name" \
-Dyarn.application.queue="default" \
-Dparallelism.default=3 \
-Dstate.backend="rocksdb" \
-Dstate.backend.incremental="true" \
-Dexecution.checkpointing.tolerable-failed-checkpoints=24 \
-Dstate.checkpoints.dir="s3://bgapps/tmp/flink/checkpoints3/${app_name}" \
-Dstate.checkpoints.num-retained=2 \
-D execution.checkpointing.externalized-checkpoint-retention="RETAIN_ON_CANCELLATION" \
-D execution.checkpointing.interval="5min" \
-D execution.checkpointing.snapshot-compression="true" \
-D execution.checkpointing.timeout="10 min" \
-D execution.checkpointing.min-pause="3 min" \
-Dtaskmanager.numberOfTaskSlots=3 \
-Djobmanager.memory.process.size=1g \
-Dtaskmanager.memory.process.size=6g \
-Dmetrics.reporter.promgateway.class="org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter" \
-Dmetrics.reporter.promgateway.host="nginx-slave.bigdata-aws.bg" \
-Dmetrics.reporter.promgateway.port="9091" \
-Dmetrics.reporter.promgateway.jobName="user_monitor_job:${app_name}" \
-Dmetrics.reporter.promgateway.randomJobNameSuffix="true" \
-Dmetrics.reporter.promgateway.deleteOnShutdown="true" \
-Dmetrics.reporter.promgateway.interval="60 SECONDS" \
-Dtaskmanager.memory.network.fraction="0.01" \
-c $job_name \
/efs/bigdata/flink/flink_project_code/bigdata-flink-dataplaform/flink-job-gw-1.0-SNAPSHOT-jar-with-dependencies.jar \
--is_prod ${is_prod} \
--db ${db} \
--table ${table} \
--topic ${topic} \
--scan.startup.mode ${scan_startup_mode} \
--write.insert.drop.duplicates ${write_insert_drop_duplicates} \
--hoodie.datasource.write.recordkey.field ${write_recordkey_field} \
--write.precombine.field ${write_precombine_field} \
--write.operation ${write_operation} \
--write.bucket_assign.tasks ${write_bucket_assign_tasks} \
--java.bean.class ${class_name} \
&














 2124
2124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









