






一、前文
oneid 是用户画像的核心,此文提供图计算的具体方案。
二、方案
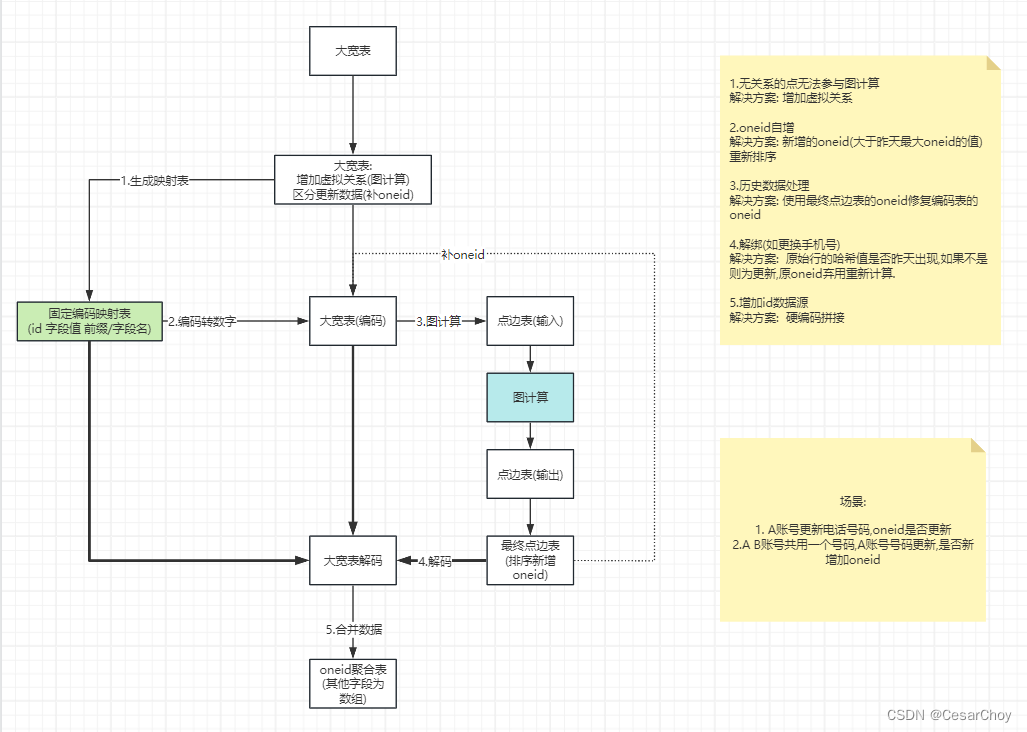
注意事项:
1. 业务存在解绑信息,当不与其他业务系统产生关联时,沿用旧oneid。
2. oneid 需要自增,下游系统会用到bitmap等数据类型,有利于人群包计算。
3. 标签与oneid 解耦,最后通过映射表关联,可大大调高计算效率。
三、开发
| 输入数据处理 | 大宽表(原始) | 100% | dwd_portrait_oneid_user_d_a |
| 映射码表 | 100% | dwd_portrait_oneid_user_col_d_a | |
| 映射id码表 | 100% | dwd_portrait_oneid_user_col_relation_d_a | |
| 大宽表(编码) | 100% | dwd_portrait_oneid_user_encode_d_a | |
| 图输入点边关系表 | 100% | dwd_portrait_oneid_graph_input_d_a | |
| 输出数据处理 | 图输出点边关系表 | 100% | dwd_portrait_oneid_graph_output_d_a |
| 映射oneid码表 | 100% | dwd_portrait_oneid_user_col_relation_minid_d_a | |
| 大宽表(解码) | 100% | dwd_portrait_oneid_user_decode_d_a | |
| 结果表 | 100% | dwd_portrait_oneid_user_total_d_a |
3.1 生成大宽表,拉宽不同业务的用户信息/关系;
CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_d_a
(
union_id STRING COMMENT 'union_id'
,phone STRING COMMENT '电话号码'
,parent_id STRING COMMENT '家长账号id'
,student_id STRING COMMENT '学生账号id'
,machine_no STRING COMMENT '内码'
,flowcode STRING COMMENT '外码'
)
COMMENT '用户画像基础明细表'
PARTITIONED BY
(
ds STRING COMMENT '分区字段'
)
;
INSERT OVERWRITE TABLE yxp.dwd_portrait_oneid_user_d_a PARTITION (ds = '${bizdate}')
SELECT union_id
,phone
,parent_id
,student_id
,machine_no
,flowcode
FROM (
SELECT union_id
,phone
,NULL AS parent_id
,NULL AS student_id
,NULL AS machine_no
,NULL AS flowcode
FROM dim_operation_clue_channel_d_a_v4
WHERE ds = '${bizdate}'
AND COALESCE(union_id,phone) <> ''
UNION ALL
SELECT wx_union_id AS union_id
,phone_num AS phone
,user_id AS parent_id
,NULL AS student_id
,NULL AS machine_no
,NULL AS flowcode
FROM dim_public_parent_user_d_a
WHERE ds = '${bizdate}'
UNION ALL
SELECT NULL AS union_id
,NULL AS phone
,user_id AS parent_id
,NULL AS student_id
,machine_no
,NULL AS flowcode
FROM dim_pad_device_parent_bind_d_a
WHERE ds = '${bizdate}'
UNION ALL
SELECT NULL AS union_id
,NULL AS phone
,NULL AS parent_id
,NULL AS student_id
,machine_no
,NULL AS flowcode
FROM dim_pad_device_d_a
WHERE ds = '${bizdate}'
UNION ALL
SELECT NULL AS union_id
,NULL AS phone
,NULL AS parent_id
,NULL AS student_id
,softwarecode AS machine_no
,flowcode
FROM ods_pad_bigdata_softwarecodeflowcodebind_mid1_d_a
WHERE ds = '${bizdate}'
UNION ALL
SELECT NULL AS union_id
,phone_num AS phone
,NULL AS parent_id
,user_id AS student_id
,NULL AS machine_no
,NULL AS flowcode
FROM dim_pad_user_d_a
WHERE ds = '${bizdate}'
UNION ALL
SELECT NULL AS union_id
,NULL AS phone
,NULL AS parent_id
,user_id AS student_id
,machine_no
,NULL AS flowcode
FROM dim_pad_device_account_mapping_d_a
WHERE ds = '${bizdate}'
UNION ALL
SELECT NULL AS union_id
,NULL AS phone
,phone_num AS parent_id
,NULL AS student_id
,machine_no
,sn AS flowcode
FROM tab_warranty
WHERE ds = '${bizdate}'
)
;3.2映射码表(提取字段为oneid做准备)
from odps import ODPS
# (1) 参数:
# 表名
input_tb = 'dwd_portrait_oneid_user_d_a'
output_tb = 'dwd_portrait_oneid_user_col_d_a'
# CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_col_d_a
# (
# col_name STRING COMMENT '列名'
# ,col_value STRING COMMENT '列值'
# )
# COMMENT '用户画像列表'
# PARTITIONED BY
# (
# ds STRING COMMENT '分区字段'
# )
# ;
# 分区名
ds = args['bizdate']
# (2) 组装SQL
# 提取列名 和 列值
t = o.get_table(input_tb)
col_sql = []
for col in t.schema.names :
col_sql.append(" select '{col}' AS col_name,{col} AS col_value from {input_tb} where ds = '{ds}' and {col} <> '' ".format(col=col,input_tb=input_tb,ds=ds))
union_sql = ' union all '.join(col_sql)
alldata_sql = "select col_name,col_value from ({union_sql})t1 group by col_name,col_value".format(union_sql=union_sql)
final_sql = " INSERT OVERWRITE TABLE {output_tb} PARTITION (ds = '{ds}') {alldata_sql} ".format(output_tb=output_tb,alldata_sql=alldata_sql,ds=ds)
# (3) 写入数据
print(final_sql)
o.execute_sql(final_sql)3.3映射id码表(生成oneid)
CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_col_relation_d_a
(
id BIGINT COMMENT '映射id'
,col_name STRING COMMENT '字段名'
,col_value STRING COMMENT '字段值'
)
COMMENT '用户画像id映射表'
PARTITIONED BY
(
ds STRING COMMENT '分区字段'
)
;
WITH tmp_today AS
(
SELECT col_name
,col_value
FROM dwd_portrait_oneid_user_col_d_a
WHERE ds = '${bizdate}'
)
,tmp_yes AS
(
SELECT id
,col_name
,col_value
FROM dwd_portrait_oneid_user_col_relation_d_a
WHERE ds = TO_CHAR(DATE_ADD(TO_DATE('${bizdate}','yyyymmdd'),-1),'yyyyMMdd')
)
,tmp_today_added AS
(
SELECT t1.col_name
,t1.col_value
,ROW_NUMBER() OVER (ORDER BY t1.col_name,t1.col_value ASC ) AS rk
FROM tmp_today t1
LEFT JOIN tmp_yes t2
ON t1.col_name = t2.col_name
AND t1.col_value = t2.col_value
WHERE t2.col_name IS NULL -- 新增
)
INSERT OVERWRITE TABLE yxp.dwd_portrait_oneid_user_col_relation_d_a PARTITION (ds = '${bizdate}')
SELECT rk + COALESCE((
SELECT MAX(id) maxid
FROM tmp_yes
) ,0) AS id
,col_name
,col_value
FROM tmp_today_added -- 今天
UNION ALL
SELECT id
,col_name
,col_value
FROM tmp_yes -- 昨天
;3.4大宽表(编码),将原来的字段值隐射成oneid用于图计算.
from odps import ODPS
# (1) 参数:
# 表名
input_tb = 'dwd_portrait_oneid_user_d_a'
id_tb = 'dwd_portrait_oneid_user_col_relation_d_a'
output_tb = 'dwd_portrait_oneid_user_encode_d_a'
# 输入输出表字段要保持一致
# CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_encode_d_a
# (
# union_id BIGINT COMMENT 'union_id'
# ,phone BIGINT COMMENT '电话号码'
# ,parent_id BIGINT COMMENT '家长账号id'
# ,student_id BIGINT COMMENT '学生账号id'
# ,machine_no BIGINT COMMENT '内码'
# ,flowcode BIGINT COMMENT '外码'
# )
# COMMENT '用户画像基础明细表'
# PARTITIONED BY
# (
# ds STRING COMMENT '分区字段'
# )
# ;
# 分区名
ds = args['bizdate']
# (2) 组装SQL
# 提取列名 和 列值
t = o.get_table(input_tb)
arr_select = []
arr_join = []
for col in t.schema.names :
arr_select.append('tmp_{col}.id as {col}'.format(col=col))
arr_join.append("left join (select col_value,id from {id_tb} where ds = '{ds}' and col_name = '{col}') tmp_{col} on {input_tb}.{col} = tmp_{col}.col_value".format(id_tb=id_tb,col=col,ds=ds,input_tb=input_tb))
final_sql = " INSERT OVERWRITE TABLE {output_tb} PARTITION (ds = '{ds}') select ".format(output_tb=output_tb,ds=ds) + ','.join(arr_select) + " from {input_tb} ".format(input_tb=input_tb) + ' '.join(arr_join) + " where ds = '{ds}' ".format(ds=ds)
# (3) 写入数据
print(final_sql)
o.execute_sql(final_sql)3.5 图输入点边关系表(用于图计算的结构)
from odps import ODPS
# (1) 参数:
# 表名
input_tb = 'dwd_portrait_oneid_user_encode_d_a'
output_tb = 'dwd_portrait_oneid_graph_input_d_a'
# CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_graph_input_d_a
# (
# v1 BIGINT COMMENT '顶点1'
# ,v2 BIGINT COMMENT '顶点2'
# )
# COMMENT '用户画像关系表(编码)'
# PARTITIONED BY
# (
# ds STRING COMMENT '分区字段'
# )
# ;
# 分区名
ds = args['bizdate']
# (2) 组装SQL
# 提取列名 和 列值
t = o.get_table(input_tb)
col_arr = []
for col in t.schema.names :
col_arr.append(col)
mapping_arr = []
index = 0
while index < len(col_arr) :
right = index + 1
while right < len(col_arr) :
mapping_arr.append(" select {col1} AS v1,{col2} AS v2 from {input_tb} where ds = '{ds}' and {col1} is not null and {col2} is not null ".format(col1=col_arr[index],col2=col_arr[right],input_tb=input_tb,ds=ds))
right += 1
index += 1
final_sql = "INSERT OVERWRITE TABLE {output_tb} PARTITION (ds = '{ds}') ".format(output_tb=output_tb,ds=ds) + ' union all '.join(mapping_arr)
# (3) 写入数据
print(final_sql)
o.execute_sql(final_sql)3.6 图计算输出

3.7映射oneid码表(将每个字段绑定最小oneid)
CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_col_relation_minid_d_a
(
id BIGINT COMMENT '映射id'
,col_name STRING COMMENT '字段名'
,col_value STRING COMMENT '字段值'
,minid BIGINT COMMENT 'minid'
,oneid BIGINT COMMENT 'oneid'
)
COMMENT '用户画像id映射输出表'
PARTITIONED BY
(
ds STRING COMMENT '分区字段'
)
;
INSERT OVERWRITE TABLE yxp.dwd_portrait_oneid_user_col_relation_minid_d_a PARTITION (ds = '${bizdate}')
SELECT t1.id
,t1.col_name
,t1.col_value
,t2.minid
,COALESCE(t2.minid,t1.id) AS oneid -- 没有边关系时最小oneid 既是自己
FROM dwd_portrait_oneid_user_col_relation_d_a t1
LEFT JOIN dwd_portrait_oneid_graph_output_d_a t2
ON t1.id = t2.v
AND t2.ds = '${bizdate}'
WHERE t1.ds = '${bizdate}'
;3.8大宽表(解码,将oneid字段回填大宽表最终输出)
from odps import ODPS
# (1) 参数:
# 表名
input_tb = 'dwd_portrait_oneid_user_d_a'
id_tb = 'dwd_portrait_oneid_user_col_relation_minid_d_a'
output_tb = 'dwd_portrait_oneid_user_decode_d_a'
# 输出表比原始表多一个字段要保持一致
# CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_decode_d_a
# (
# oneid BIGINT COMMENT '唯一id'
# ,union_id STRING COMMENT 'union_id'
# ,phone STRING COMMENT '电话号码'
# ,parent_id STRING COMMENT '家长账号id'
# ,student_id STRING COMMENT '学生账号id'
# ,machine_no STRING COMMENT '内码'
# ,flowcode STRING COMMENT '外码'
# )
# COMMENT '用户画像基础明细表(解码)'
# PARTITIONED BY
# (
# ds STRING COMMENT '分区字段'
# )
# ;
# 分区名
ds = args['bizdate']
# (2) 组装SQL
# 提取列名 和 列值
t = o.get_table(input_tb)
arr_select_oneid = []
arr_select = []
arr_join = []
for col in t.schema.names :
arr_select_oneid.append('tmp_{col}.oneid'.format(col=col))
arr_select.append("{input_tb}.{col}".format(input_tb=input_tb,col=col))
arr_join.append("left join (select col_value,oneid from {id_tb} where ds = '{ds}' and col_name = '{col}') tmp_{col} on {input_tb}.{col} = tmp_{col}.col_value".format(id_tb=id_tb,col=col,ds=ds,input_tb=input_tb))
final_sql = " INSERT OVERWRITE TABLE {output_tb} PARTITION (ds = '{ds}') select coalesce({sql_oneid}) as oneid,{sql_col} from {input_tb} {sql_join} where ds = '{ds}' " \
.format(sql_oneid=','.join(arr_select_oneid) \
, sql_col=','.join(arr_select) \
,sql_join=' '.join(arr_join) \
,output_tb=output_tb ,input_tb=input_tb ,ds=ds )
# (3) 写入数据
print(final_sql)
o.execute_sql(final_sql)3.9 结果表(可通过oneid与字段值互查)
CREATE TABLE IF NOT EXISTS yxp.dwd_portrait_oneid_user_total_d_a
(
oneid BIGINT COMMENT '唯一id'
,union_id ARRAY<STRING> COMMENT 'union_id'
,phone ARRAY<STRING> COMMENT '电话号码'
,parent_id ARRAY<STRING> COMMENT '家长账号id'
,student_id ARRAY<STRING> COMMENT '学生账号id'
,machine_no ARRAY<STRING> COMMENT '内码'
,flowcode ARRAY<STRING> COMMENT '外码'
)
COMMENT '用户画像基础结果表'
PARTITIONED BY
(
ds STRING COMMENT '分区字段'
)
;
-- EXPLAIN
INSERT OVERWRITE TABLE yxp.dwd_portrait_oneid_user_total_d_a PARTITION (ds = '${bizdate}')
SELECT oneid
,COLLECT_SET(union_id) AS union_id
,COLLECT_SET(phone) AS phone
,COLLECT_SET(parent_id) AS parent_id
,COLLECT_SET(student_id) AS student_id
,COLLECT_SET(machine_no) AS machine_no
,COLLECT_SET(flowcode) AS flowcode
FROM dwd_portrait_oneid_user_decode_d_a
WHERE ds = '${bizdate}'
GROUP BY oneid
;













 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









