







主题管理相关
主题日常管理
创建主题
创建 Kafka 主题命令
Kafka 提供了自带的 kafka-topics 脚本,用于帮助用户创建主题
位于 Kafka 安装目录的 bin 子目录下。 Windows 位于 bin 路径的 windows 子目录下
bin/kafka-topics.sh
--bootstrap-server broker_host:port
--create 创建主题
--topic my_topic_name
--partitions 1 主题的分区数
--replication-factor 1 每个分区下的副本数
从 Kafka 2.2 版本开始,社区推荐用 --bootstrap-server 参数替换 --zookeeper 参数,并且显式地将后者标记为“已过期”
替换原因:
1. 使用 --zookeeper 会绕过 Kafka 的安全体系。这就是说,即使为 Kafka 集群设置了安全认证,
限制了主题的创建,如果使用 --zookeeper 的命令,依然能成功创建任意主题,不受认证体系的约束。
2. 使用 --bootstrap-server 与集群进行交互,越来越成为使用 Kafka 的标准姿势。
换句话说,以后会有越来越少的命令和 API 需要与 ZooKeeper 进行连接。
这样,只需要一套连接信息,就能与 Kafka 进行全方位的交互,不用同时维护 ZooKeeper 和 Broker 的连接信息。
查询主题
创建好主题之后,Kafka 允许使用相同的脚本查询所有主题的列表
bin/kafka-topics.sh --bootstrap-server broker_host:port --list
查询单个主题的详细数据
bin/kafka-topics.sh --bootstrap-server broker_host:port --describe --topic <topic_name>
如果 describe 命令不指定具体的主题名称,那么 Kafka 默认会返回所有“可见”主题的详细数据。
主题创建时,使用 --zookeeper 和 --bootstrap-server 的区别是一样的
主题查询时,
使用 --bootstrap-server 会对命令发起者进行权限验证,然后返回它能看到的主题
使用 --zookeeper 参数,默认会返回集群中所有的主题详细数据
所以, 建议最好统一使用 --bootstrap-server 连接参数
修改主题
- 修改主题分区。
其实就是增加分区,目前 Kafka 不允许减少某个主题的分区数
bin/kafka-topics.sh
--bootstrap-server broker_host:port
--alter 参数, 增加某个主题的分区
--topic <topic_name>
--partitions <新分区数>
注意: 指定的分区数一定要比原有分区数大,否则 Kafka 会抛出 InvalidPartitionsException 异常
- 修改主题级别参数
在主题创建之后,可以使用 kafka-configs 脚本修改对应的参数。
假设要设置主题级别参数 max.message.bytes,那么命令如下:
bin/kafka-configs.sh
--zookeeper zookeeper_host:port
--entity-type topics
--entity-name <topic_name>
--alter
--add-config max.message.bytes=10485760
为什么这个脚本就要指定 --zookeeper,而不是 --bootstrap-server 呢?
--bootstrap-server 用来设置动态参数
--zookeeper 设置常规的主题级别参数
后面详细介绍
-
变更副本数
使用自带的 kafka-reassign-partitions 脚本,增加主题的副本数
后面拿 Kafka 内部主题 __consumer_offsets 来演示如何增加主题副本数 -
修改主题限速
主要指设置 Leader 副本和 Follower 副本使用的带宽。
如果想要让某个主题的副本在执行副本同步机制时,不要消耗过多的带宽
先设置 Broker 端参数 leader.replication.throttled.rate 和 follower.replication.throttled.rate
不得占用超过 100MBps 的带宽. 大写 B,即每秒不超过 100MB
bin/kafka-configs.sh
--zookeeper zookeeper_host:port
--alter
--add-config 'leader.replication.throttled.rate=104857600,follower.replication.throttled.rate=104857600'
--entity-type brokers
--entity-name 0 (就是 Broker ID)
倘若该主题的副本分别在 0、1、2、3 多个 Broker 上,还要依次为 Broker 1、2、3 执行这条命令
还需要为该主题设置要限速的副本
bin/kafka-configs.sh
--zookeeper zookeeper_host:port
--alter
--add-config 'leader.replication.throttled.replicas=*,follower.replication.throttled.replicas=*'
--entity-type topics
--entity-name test
统一使用通配符 * 来表示为所有副本都设置限速
- 主题分区迁移
使用 kafka-reassign-partitions 脚本, 比如把某些分区批量迁移到其他 Broker 上, 后面介绍
删除主题
bin/kafka-topics.sh
--bootstrap-server broker_host:port
--delete
--topic <topic_name>
异步删除, Kafka 会在后台默默地开启主题删除操作, 需要等待一段时间
特殊主题的管理与运维
- Kafka 内部主题 __consumer_offsets
- Kafka 支持事务新引入的 __transaction_state
带有 __consumer_offsets 和 __transaction_state 前缀的子目录, 这两个内部主题默认都有 50 个分区, 分区子目录会非常得多
建议不要手动创建或修改它们
__consumer_offsets 的副本数问题:
- 在 Kafka 0.11 之前,当 Kafka 自动创建该主题时,它会综合考虑
当前运行的 Broker 台数和Broker 端参数 offsets.topic.replication.factor 值,然后取两者的较小值作为该主题的副本数,但这就违背了用户设置 offsets.topic.replication.factor 的初衷。 - 这正是很多用户感到困扰的地方:集群中有 100 台 Broker,offsets.topic.replication.factor 也设成了 3,为什么 __consumer_offsets 主题只有 1 个副本?其实,这就是因为
这个主题是在只有一台 Broker 启动时被创建的。 - 在 0.11 版本之后,Kafka 会
严格遵守 offsets.topic.replication.factor 值。如果当前运行的 Broker 数量小于 offsets.topic.replication.factor 值,Kafka 会创建主题失败,并显式抛出异常。
修改内部主题
如果该主题的副本值已经是 1 了,能否把它增加到 3 呢?
- 创建一个 json 文件,显式提供 50 个分区对应的副本数。注意,replicas 中的 3 台 Broker 排列顺序不同,目的是
将 Leader 副本均匀地分散在 Broker 上。该文件具体格式如下:
{"version":1, "partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[0,1,2]},
{"topic":"__consumer_offsets","partition":1,"replicas":[0,2,1]},
{"topic":"__consumer_offsets","partition":2,"replicas":[1,0,2]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1,2,0]},
...
{"topic":"__consumer_offsets","partition":49,"replicas":[0,1,2]}
]}
- 执行 kafka-reassign-partitions 脚本
bin/kafka-reassign-partitions.sh
--zookeeper zookeeper_host:port
--reassignment-json-file reassign.json
--execute
查看内部主题的消息内容
对于 __consumer_offsets 而言,由于它保存了消费者组的位移数据,有时候直接查看该主题消息是很方便的事情
直接查看消费者组提交的位移数据
bin/kafka-console-consumer.sh
--bootstrap-server kafka_host:port
--topic __consumer_offsets
--formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
--from-beginning
直接读取该主题消息,查看消费者组的状态信息
bin/kafka-console-consumer.sh
--bootstrap-server kafka_host:port
--topic __consumer_offsets
--formatter "kafka.coordinator.group.GroupMetadataManager\$GroupMetadataMessageFormatter"
--from-beginning
内部主题 __transaction_state 方法相同
指定 kafka.coordinator.transaction.TransactionLog\$TransactionLogMessageFormatter 即可
常见主题错误处理
常见错误 1:主题删除失败
常见的原因:
- 副本所在的 Broker 宕机了
重启对应的 Broker 之后,删除操作就能自动恢复 - 待删除主题的部分分区依然在执行迁移过程
不管什么原因,一旦碰到主题无法删除的问题,可以采用这样的方法:
- 手动删除 ZooKeeper 节点 /admin/delete_topics 下以待删除主题为名的 znode。
- 手动删除该主题在磁盘上的分区目录。
- 在 ZooKeeper 中执行 rmr /controller,触发 Controller 重选举,刷新 Controller 缓存。
最后一步可能造成大面积的分区 Leader 重选举
事实上,仅仅执行前两步也是可以的,只是 Controller 缓存中没有清空待删除主题罢了,也不影响使用。
常见错误 2:__consumer_offsets 占用太多的磁盘
一旦发现这个主题消耗了过多的磁盘空间,一定要显式地用 jstack 命令查看一下 kafka-log-cleaner-thread 前缀的线程状态。
通常情况下,这都是因为该线程挂掉了,无法及时清理此内部主题。
倘若真是这个原因导致的,那就只能重启相应的 Broker 了。
另外,请注意保留出错日志,因为这通常都是 Bug 导致的,最好提交到社区看一下。
小结

讨论: kafka为什么不允许减少分区数?
因为多个broker节点都冗余有分区的数据,减少分区数需要操作多个broker且需要迁移该分区数据到其他分区。如果是按消息key hash选的分区,那么迁移就不知道迁到哪里了,因为只有业务代码可以决定放在哪
增加分区,那旧分区的数据不会自动转移
Kafka 动态配置
什么是动态 Broker 参数配置
在 Kafka 安装目录的 config 路径下,有个 server.properties 文件
通常情况下,指定这个文件的路径来启动 Broker
如果要设置 Broker 端的任何参数,必须在这个文件中显式地增加一行对应的配置,之后启动 Broker 进程,令参数生效
常见的做法是,一次性设置好所有参数之后,再启动 Broker
当后面需要变更任何参数时,必须重启 Broker
但生产环境中的服务器,目前修改 Broker 端参数是非常痛苦的过程
基于这个痛点,社区于 1.1.0 版本中正式引入了动态 Broker 参数(Dynamic Broker Configs)
所谓动态,就是指修改参数值后,无需重启 Broker 就能立即生效,而之前在 server.properties 中配置的参数则称为静态参数(Static Configs)
1.1 版本之后(含 1.1)的 Kafka 官网,Broker Configs表中增加了 Dynamic Update Mode 列
该列有 3 类值,分别是
read-only
被标记为 read-only 的参数和原来的参数行为一样,只有重启 Broker,才能令修改生效per-broker
被标记为 per-broker 的参数属于动态参数,修改它之后,只会在对应的 Broker 上生效cluster-wide
被标记为 cluster-wide 的参数也属于动态参数,修改它之后,会在整个集群范围内生效,也就是说,对所有 Broker 都生效。也可以为具体的 Broker 修改 cluster-wide 参数
per-broker 和 cluster-wide 的区别eg:
- Broker 端参数 listeners 是一个 per-broker 参数,这表示只能为单个 Broker 动态调整 listeners,而不能直接调整一批 Broker 的 listeners
- log.retention.ms 参数是 cluster-wide 级别的,Kafka 允许为集群内所有 Broker 统一设置一个日志留存时间值。当然也可以为单个 Broker 修改此值。
使用场景
- 动态调整 Broker 端各种线程池大小,实时应对突发流量。
当 Kafka Broker入站流量(inbound data)激增时,会造成 Broker 端请求积压(Backlog)
有了动态参数,就能够动态增加网络线程数和 I/O 线程数,快速消耗一些积压
当突发流量过去后,可以将线程数调整回来,减少对资源的浪费, 整个过程都不需要重启 Broker
甚至可以将这套调整线程数的动作,封装进定时任务中,以实现自动扩缩容 - 动态调整 Broker 端连接信息或安全配置信息。
- 动态更新 SSL Keystore 有效期。
- 动态调整 Broker 端 Compact 操作性能。
- 实时变更 JMX 指标收集器 (JMX Metrics Reporter)。
动态配置保存机制
- Kafka 将动态 Broker 参数保存在 ZooKeeper 中

- changes 是用来实时监测动态参数变更的,不会保存参数值;
topics 是用来保存 Kafka 主题级别参数的。
虽然它们不属于动态 Broker 端参数,但其实它们也是能够动态变更的。 - users 和 clients 则是用于动态调整客户端
配额(Quota)的 znode 节点。
所谓配额,是指 Kafka 运维人员限制连入集群的客户端的吞吐量或者是限定它们使用的 CPU 资源。
其实, /config/brokers znode 才是真正保存动态 Broker 参数的地方。该 znode 下有两大类子节点。
- 第一类子节点只有一个, 固定的名字叫 < default >,保存的是前面说过的
cluster-wide 范围的动态参数; - 另一类则以 broker.id 为名,保存的是特定 Broker 的
per-broker 范围参数。由于是 per-broker 范围,因此这类子节点可能存在多个。
Kafka 集群环境上的动态 Broker 端参数图

红框1:
查看了 /config/brokers 下的子节点,有 < default > 节点和名为 0、1 的子节点。
< default > 节点中保存了设置的 cluster-wide 范围参数;
0 和 1 节点中分别保存了 Broker 0 和 Broker 1 设置的 per-broker 参数。
红框234:
分别展示了 cluster-wide 范围和 per-broker 范围的参数设置。
拿 num.io.threads 参数为例,其 cluster-wide 值被动态调整为 12,而在 Broker 0 上被设置成 16,在 Broker 1 上被设置成 8。
为 Broker 0 和 Broker 1 单独设置的值,会覆盖掉 cluster-wide 值,但在其他 Broker 上,该参数默认值还是按 12 计算。
优先级
per-broker 参数 > cluster-wide 参数 > static 参数 > Kafka 默认值。
ephemeralOwner 字段,值都是 0x0, 表示这些 znode 都是持久化节点,它们将一直存在
即使 ZooKeeper 集群重启,这些数据也不会丢失,这样就能保证这些动态参数的值会一直生效。
如何配置动态 Broker 参数
只有一个设置动态参数的工具行命令,Kafka 自带的 kafka-configs 脚本
以 unclean.leader.election.enable 参数为例, 在集群层面设置全局值, 即设置 cluster-wide 范围值 动态调整
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-default
--alter
--add-config unclean.leader.election.enable=true
输出:
Completed updating default config for brokers in the cluster 已完成更新群集中代理的默认配置
如果要设置 cluster-wide 范围的动态参数,需要显式指定 entity-default
查看一下刚才的配置是否成功
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-default
--describe
输出:
Default config for brokers in the cluster are:
unclean.leader.election.enable=true 成功地在全局层面上设置该参数值为 true
sensitive=false 表明要调整的参数不是敏感数据. eg密码数据就是敏感数据
synonyms={DYNAMIC_DEFAULT_BROKER_CONFIG:unclean.leader.election.enable=true}
以 unclean.leader.election.enable 参数为例, 设置 per-broker 范围参数
为 ID 为 1 的 Broker 设置一个不同的值
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-name 1
--alter
--add-config unclean.leader.election.enable=false
输出:
Completed updating config for broker: 1.
查看是否生效
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-name 1
--describe
输出:
Configs for broker 1 are:
unclean.leader.election.enable=false 在 Broker 1 生效
sensitive=false
synonyms={
DYNAMIC_BROKER_CONFIG:unclean.leader.election.enable=false,
DYNAMIC_DEFAULT_BROKER_CONFIG:unclean.leader.election.enable=true,
全局依然为true, 之前的cluster-wide 范围参数值依然有效
DEFAULT_CONFIG:unclean.leader.election.enable=false}
# 删除cluster-wide范围参数
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-default
--alter
--delete-config unclean.leader.election.enable 需要指定 delete-config
输出:
Completed updating default config for brokers in the cluster,
# 删除per-broker范围参数
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-name 1
--alter
--delete-config unclean.leader.election.enable 需要指定 delete-config
输出:
Completed updating config for broker: 1.
# 查看cluster-wide范围参数
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-default
--describe
输出:
Default config for brokers in the cluster are:
# 查看Broker 1上的动态参数配置
$ bin/kafka-configs.sh
--bootstrap-server kafka-host:port
--entity-type brokers
--entity-name 1
--describe
输出:
Configs for broker 1 are:
常用的动态参数配置
查看有哪些动态 Broker 参数
- 在 Kafka 官网中查看 Broker 端参数列表
- 运行无参数的 kafka-configs 脚本,其说明文档会有当前动态 Broker 参数都有哪些


log.retention.ms
修改日志留存时间num.io.threads 和 num.network.threads
前面提到的两组线程池, Broker 端请求处理能力经常要按需扩容- 与 SSL 相关的参数
主要是 4 个参数(ssl.keystore.type、ssl.keystore.location、ssl.keystore.password 和 ssl.key.password)
允许动态实时调整它们之后,就能创建那些过期时间很短的 SSL 证书
每当调整时,Kafka 底层会重新配置 Socket 连接通道并更新 Keystore
新的连接会使用新的 Keystore,阶段性地调整这组参数,有利于增加安全性 num.replica.fetchers
Follower 副本拉取速度慢,在线上 Kafka 环境中一直是一个老大难的问题
针对这个问题,常见的做法是增加该参数值,确保有充足的线程可以执行 Follower 副本向 Leader 副本的拉取
现在有了动态参数,不需要再重启 Broker,就能立即在 Follower 端生效
小结
动态参数的好处,无需重启 Broker,就可以令变更生效,因此能够极大地降低运维成本

重设消费者组位移
why?
重设位移主要是为了实现消息的重演。
Kafka 和传统的消息引擎在设计上是有很大区别的,
其中一个比较显著的区别就是,Kafka 的消费者读取消息是可以重演的(replayable)
像 RabbitMQ 或 ActiveMQ 这样的传统消息中间件,它们处理和响应消息的方式是破坏性的(destructive),
即一旦消息被成功处理,就会被从 Broker 上删除。
反观 Kafka,由于它是基于日志结构(log-based)的消息引擎,消费者在消费消息时,仅仅是从磁盘文件上读取数据而已,是只读的操作,因此消费者不会删除消息数据。
同时,由于位移数据是由消费者控制的,因此它能够很容易地修改位移的值,实现重复消费历史数据的功能。
选择使用传统的消息中间件,还是使用 Kafka 呢?
- 消息处理逻辑非常复杂,处理代价很高,同时又不关心消息之间的顺序,那么传统的消息中间件是比较合适的;
- 反之,如果场景需要较高的吞吐量,但每条消息的处理时间很短,同时又很在意消息的顺序,Kafka 就是首选。
重设位移策略
不论是哪种设置方式,重设位移大致可以从两个维度来进行。
- 位移维度。把消费者的位移值重设成给定的位移值
- 时间维度。可以给定
一个时间,让消费者把位移调整成大于该时间的最小位移;也可以给出一段时间间隔,比如 30 分钟前,然后让消费者直接将位移调回 30 分钟之前的位移值。
下面的这张表格罗列了 7 种重设策略。
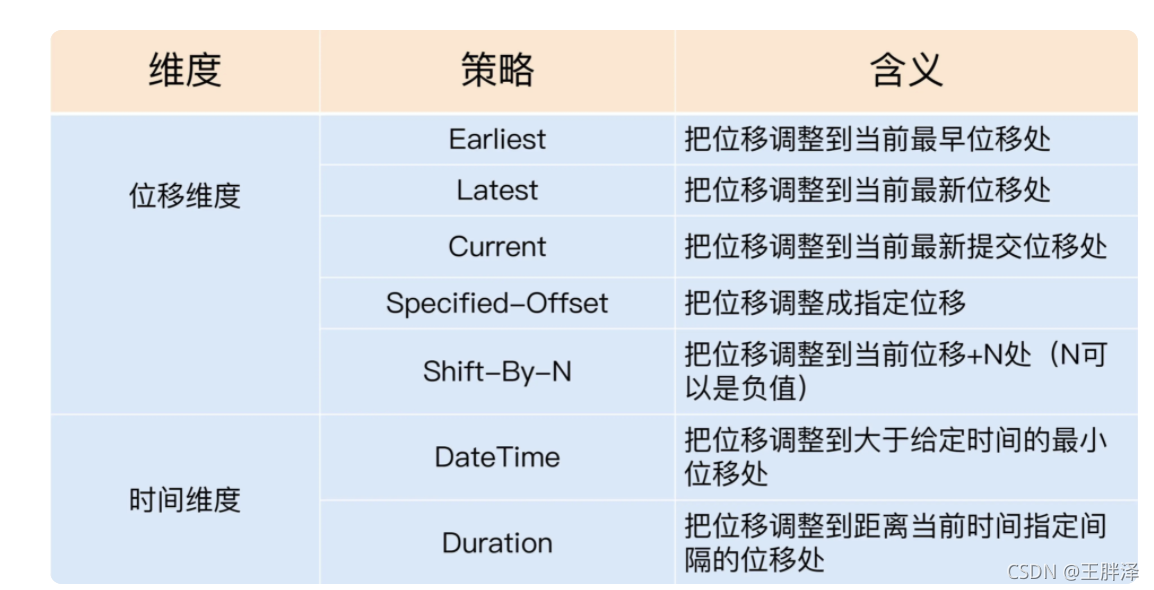
位移维度策略:
Earliest 策略表示将位移调整到主题当前最早位移处。
这个最早位移不一定就是 0,因为在生产环境中,很久远的消息会被 Kafka 自动删除,所以当前最早位移很可能是一个大于 0 的值。
如果想要重新消费主题的所有消息,那么可以使用 Earliest 策略。Latest 策略表示把位移重设成最新末端位移。
如果总共向某个主题发送了 15 条消息,那么最新末端位移就是 15。
如果想跳过所有历史消息,打算从最新的消息处开始消费的话,可以使用 Latest 策略。Current 策略表示将位移调整成消费者当前提交的最新位移。
场景:修改了消费者程序代码,并重启了消费者,结果发现代码有问题,需要回滚之前的代码变更,同时也要把位移重设到消费者重启时的位置,那么,Current 策略就可以实现这个功能。Specified-Offset 策略则是比较通用的策略,表示消费者把位移值调整到指定的位移处(位移的绝对值)
典型使用场景: 消费者程序在处理某条错误消息时,可以手动地“跳过”此消息的处理。
在实际使用过程中,可能会出现 corrupted 消息无法被消费的情形,此时消费者程序会抛出异常,无法继续工作。
一旦碰到这个问题,就可以尝试使用 Specified-Offset 策略来规避。Shift-By-N 策略指定的就是位移的相对数值,即给出要跳过的一段消息的距离即可。
这里的“跳”是双向的,既可以向前“跳”,也可以向后“跳”。
比如,把位移重设成当前位移的前 100 条位移处,需要指定 N 为 -100。
时间维度策略:
- DateTime 允许指定一个时间,然后将位移重置到该时间之后的最早位移处。
常见的使用场景是,如果想重新消费昨天的数据,那么可以使用该策略重设位移到昨天 0 点。 Duration 策略则是指给定相对的时间间隔,然后将位移调整到距离当前给定时间间隔的位移处,具体格式是 PnDTnHnMnS。
类似Java 8 引入的 Duration 类, 是一个符合 ISO-8601 规范的 Duration 格式
以字母 P 开头,后面由 4 部分组成,即 D、H、M 和 S,分别表示天、小时、分钟和秒。
eg: 将位移调回到 15 分钟前,指定 PD0H15M0S。
重设消费者组位移的方式
消费者 API 方式设置
KafkaConsumer
void seek(TopicPartition partition, long offset);
void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata);
方法的定义 -> 每次调用 seek 方法只能重设一个分区的位移
OffsetAndMetadata 类是一个封装了 Long 型的位移和自定义元数据的复合类,只是一般情况下,自定义元数据为空,
因此基本上可以认为这个类表征的主要是<消息的位移值>。
void seekToBeginning(Collection<TopicPartition> partitions);
void seekToEnd(Collection<TopicPartition> partitions);
seek 的变种方法 seekToBeginning 和 seekToEnd 则拥有一次重设多个分区的能力, 调用它们时可以一次性传入多个主题分区。
Earliest 策略的实现方式
Properties consumerProperties = new Properties();
consumerProperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
consumerProperties.put(ConsumerConfig.GROUP_ID_CONFIG, groupID);
consumerProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
consumerProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
String topic = "test"; // 要重设位移的Kafka主题
try (final KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProperties)) {
consumer.subscribe(Collections.singleton(topic));
consumer.poll(0);
consumer.seekToBeginning(
consumer.partitionsFor(topic).stream()
.map(partitionInfo -> new TopicPartition(topic, partitionInfo.partition()))
.collect(Collectors.toList()));
}
注意点:
1.创建的消费者程序,要禁止自动提交位移。
2.组 ID 要设置成要重设的消费者组的组 ID。
3.调用 seekToBeginning 方法时,需要一次性构造主题的所有分区对象。
4.最重要的是,一定要调用带长整型的 poll 方法,而不要调用 consumer.poll(Duration.ofSecond(0))。
虽然社区已经不推荐使用 poll(long) 了,但短期内应该不会移除它
Latest 策略和 Earliest 策略类似
consumer.seekToEnd(
consumer.partitionsFor(topic).stream()
.map(partitionInfo -> new TopicPartition(topic, partitionInfo.partition()))
.collect(Collectors.toList()));
实现 Current 策略的方法很简单,需要借助 KafkaConsumer 的 committed 方法来获取当前提交的最新位移,代码如下:
consumer.partitionsFor(topic).stream()
.map(info -> new TopicPartition(topic, info.partition()))
.forEach(tp -> {
long committedOffset = consumer.committed(tp).offset();
consumer.seek(tp, committedOffset);
});
1. 调用 partitionsFor 方法获取给定主题的所有分区
2. 依次获取对应分区上的已提交位移
3. 通过 seek 方法重设位移到已提交位移处
实现 Specified-Offset 策略,直接调用 seek 方法
long targetOffset = 1234L;
for (PartitionInfo info : consumer.partitionsFor(topic)) {
TopicPartition tp = new TopicPartition(topic, info.partition());
consumer.seek(tp, targetOffset);
}
实现 Shift-By-N 策略
for (PartitionInfo info : consumer.partitionsFor(topic)) {
TopicPartition tp = new TopicPartition(topic, info.partition()); // 假设向前跳123条消息
long targetOffset = consumer.committed(tp).offset() + 123L;
consumer.seek(tp, targetOffset);
}
实现 DateTime 策略,借助另一个方法:KafkaConsumer. offsetsForTimes 方法
假设要重设位移到 2019 年 6 月 20 日晚上 8 点
long ts = LocalDateTime.of(2019, 6, 20, 20, 0).toInstant(ZoneOffset.ofHours(8)).toEpochMilli();
Map<TopicPartition, Long> timeToSearch = consumer.partitionsFor(topic).stream()
.map(info -> new TopicPartition(topic, info.partition()))
.collect(Collectors.toMap(Function.identity(), tp -> ts));
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry :
consumer.offsetsForTimes(timeToSearch).entrySet()) {
consumer.seek(entry.getKey(), entry.getValue().offset());
}
构造了 LocalDateTime 实例,然后利用它去查找对应的位移值,最后调用 seek,实现了重设位移
Duration 策略
将位移调回 30 分钟前
Map<TopicPartition, Long> timeToSearch = consumer.partitionsFor(topic).stream()
.map(info -> new TopicPartition(topic, info.partition()))
.collect(Collectors.toMap(Function.identity(), tp -> System.currentTimeMillis() - 30 * 1000 * 60));
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry :
consumer.offsetsForTimes(timeToSearch).entrySet()) {
consumer.seek(entry.getKey(), entry.getValue().offset());
}
使用 Java API 的方式来实现重设策略的主要入口方法,就是 seek 方法
命令行方式设置
Kafka 0.11 版本中新引入的, 通过 kafka-consumer-groups 脚本重设位移
Earliest 策略, 指定 --to-earliest
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--all-topics
--to-earliest
–execute
Latest 策略, 指定 --to-latest
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--all-topics
--to-latest
--execute
Current 策略, 指定 --to-current
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--all-topics
--to-current
--execute
Specified-Offset 策略, 指定 --to-offset
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--all-topics
--to-offset <offset>
--execute
Shift-By-N 策略, 指定 --shift-by N
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--shift-by <offset_N>
--execute
DateTime 策略, 指定 --to-datetime
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--to-datetime 2019-06-20T20:00:00.000
--execute
Duration 策略,指定 --by-duration
bin/kafka-consumer-groups.sh
--bootstrap-server kafka-host:port
--group test-group
--reset-offsets
--by-duration PT0H30M0S
--execute
小结
重设位移主要是为了实现消息的重演。
目前 Kafka 支持 7 种重设策略和 2 种重设方法。
在实际使用过程中,推荐使用命令行的方式来重设位移。
但是需要注意的是,0.11 及 0.11 版本之后的 Kafka 才提供了用命令行调整位移的方法
常见工具脚本大汇总
命令行脚本概览
2.2 版本提供的所有命令行脚本
2.2 版本总共提供了 30 个 SHELL 脚本。
图中的 windows 实际上是个子目录,里面保存了 Windows 平台下的 BAT 批处理文件。
其他的.sh 文件则是 Linux 平台下的标准 SHELL 脚本。

默认情况下,不加任何参数或携带 --help 运行 SHELL 文件,会得到该脚本的使用方法说明。
eg: kafka-log-dirs 脚本的调用方法。
















 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









