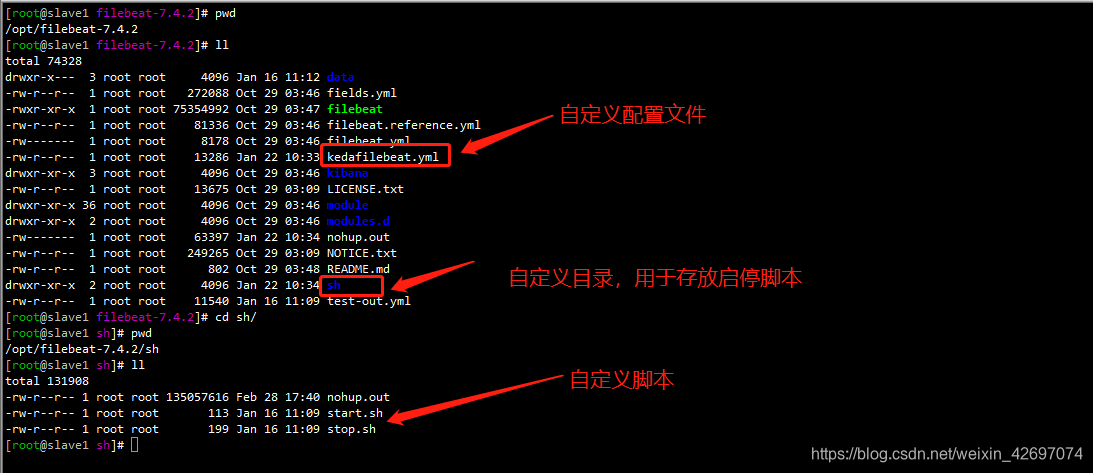
[root@slave1 filebeat-7.4.2]# cat kedafilebeat.yml
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
# 采集的数据,是日志类型,所以 type为 log
- type: log
# true: 表示启动
enabled: true
#采集日志的 路径
paths:
- /data/springCloud/eureka/keda-eureka/*/logs/error/*.json
#编码格式
encoding: utf-8
#采集当期时间,往前推12个小时内,所有文件
ignore_older: 12h
# 默认情况下,解码后的JSON放置在输出文档中的“ json”键下。
# 如果启用此设置,则将密钥复制到输出文档的顶层。默认值为false
fields_under_root: false
# fields 可以添加自定义的 属性和属性值,这里设置的是,标记输出到那条kafka队列
fields:
log_topic: eureka_topic
- type: log
enabled: true
paths:
- /data/springCloud/gateway/keda-gateway/*/logs/error/*.json
- /data/springCloud/gateway/keda-gateway/*/logs/info/*.json
- /data/springCloud/gateway/keda-gateway/*/logs/ware/*.json
- /data/springCloud/gateway/keda-gateway/*/logs/trace/*.json
encoding: utf-8
ignore_older: 12h
fields_under_root: false
fields:
log_topic: gateway_topic
- type: log
enabled: true
paths:
- /data/springCloud/gateway/keda-gateway/*/logs/debug/*.json
include_lines: [".*org.apache.ibatis.logging.jdbc.BaseJdbcLogger.*"]
encoding: utf-8
ignore_older: 12h
fields_under_root: false
fields:
log_topic: gateway_topic
# /data/springCloud/project/keda6-information-main/keda-information-main/172.19.174.184-9820/logs/info
- type: log
enabled: true
paths:
#info-20200115
- /data/springCloud/project/keda6-information-main/*/*/logs/*/*.json
# - /data








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3472
3472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









