






模型类序列化器:serializer 的升级。
注意,此时表模型自身的校验规则也将映射过来。
只需要在serializers中写一个模型类序列化器即可。
serializer.py
# 模型类序列化器
# 此序列化类和表模型有对应关系,映射
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
# 序列化指定字段名
fields = ['id','name']
# 全部序列化
# filter = '__all__'
# 显示出id以外的
exclude = ['id']view.py
# 模型类序列化器
class PublishAPIView(APIView):
# 查询所有的接口
def get(self, request, *args, **kwargs):
# 从数据库中把所有的数据取出,取出Books所有的queryset对象
publish_list = Publish.objects.all()
"""
类实例化得到对象(ser),并转为字典,此处为序列化过程,把queryset转成字典
BookSerializers(
需要序列化的queryset对象,
data=None可以不传,
如果序列化多条数据需要加many=True)
"""
ser = PublishModelSerializer(instance=publish_list, many=True)
# ser.data 序列化转成字典
return Response(ser.data)
# 新增
def post(self, request, *args, **kwargs):
# <rest_framework.request.Request: POST '/books/'>
# print(request)
# {'name': '新增8', 'price': 10, 'publish': '测试出版社'}
# print(request.data)
ser = PublishSerializers(data=request.data)
# 校验通过保存数据
if ser.is_valid():
ser.save()
return Response(ser.data)
# 校验未通过
else:
# {'name': [ErrorDetail(string='不能以sb开头', code='invalid')]}
# print(ser.errors)
# [ErrorDetail(string='不能以sb开头', code='invalid')]
print(ser.errors.get('name'))
return Response({'msg': '出错'})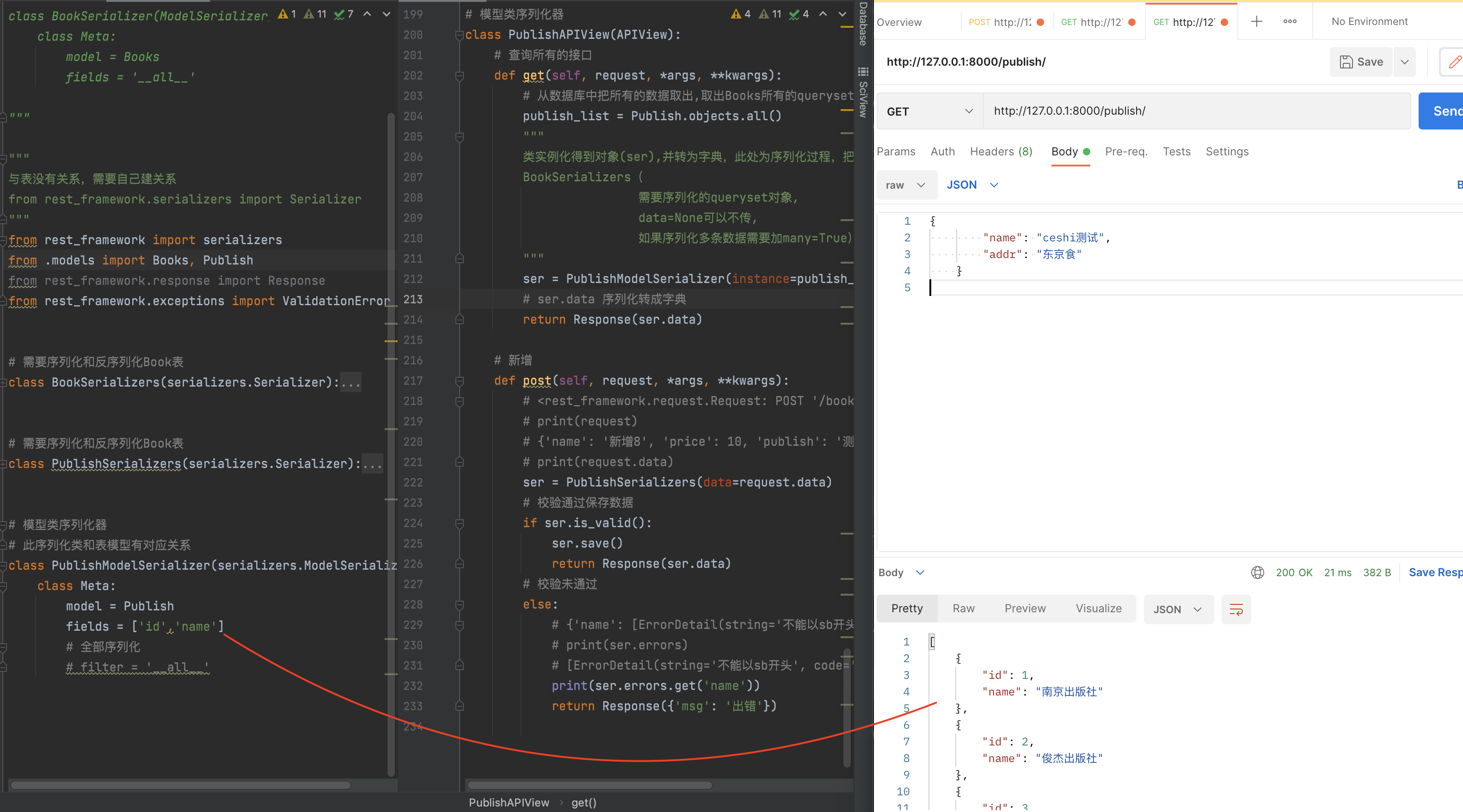
还可以写模型类的方法:
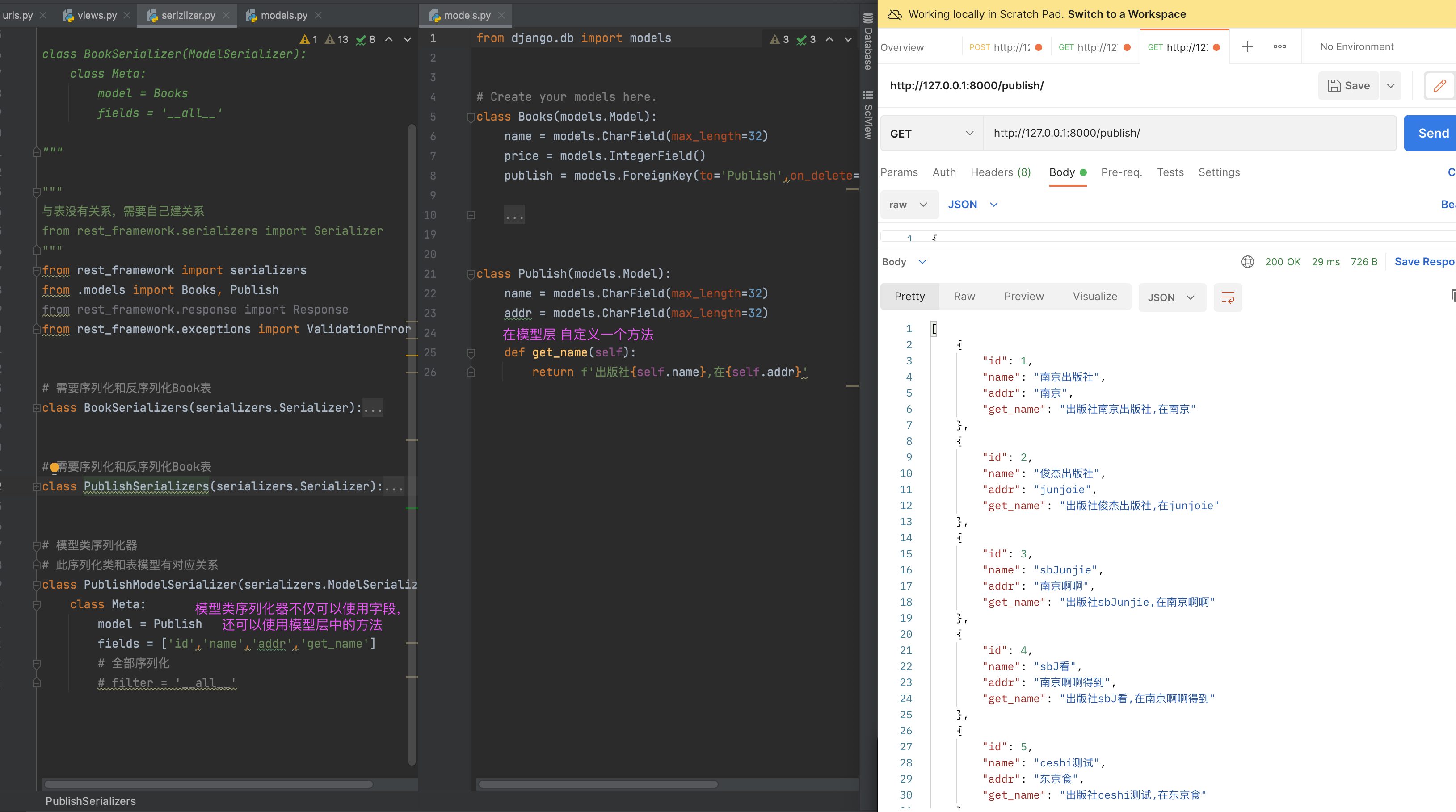
depth深度查询
没有使用depth深度查询。
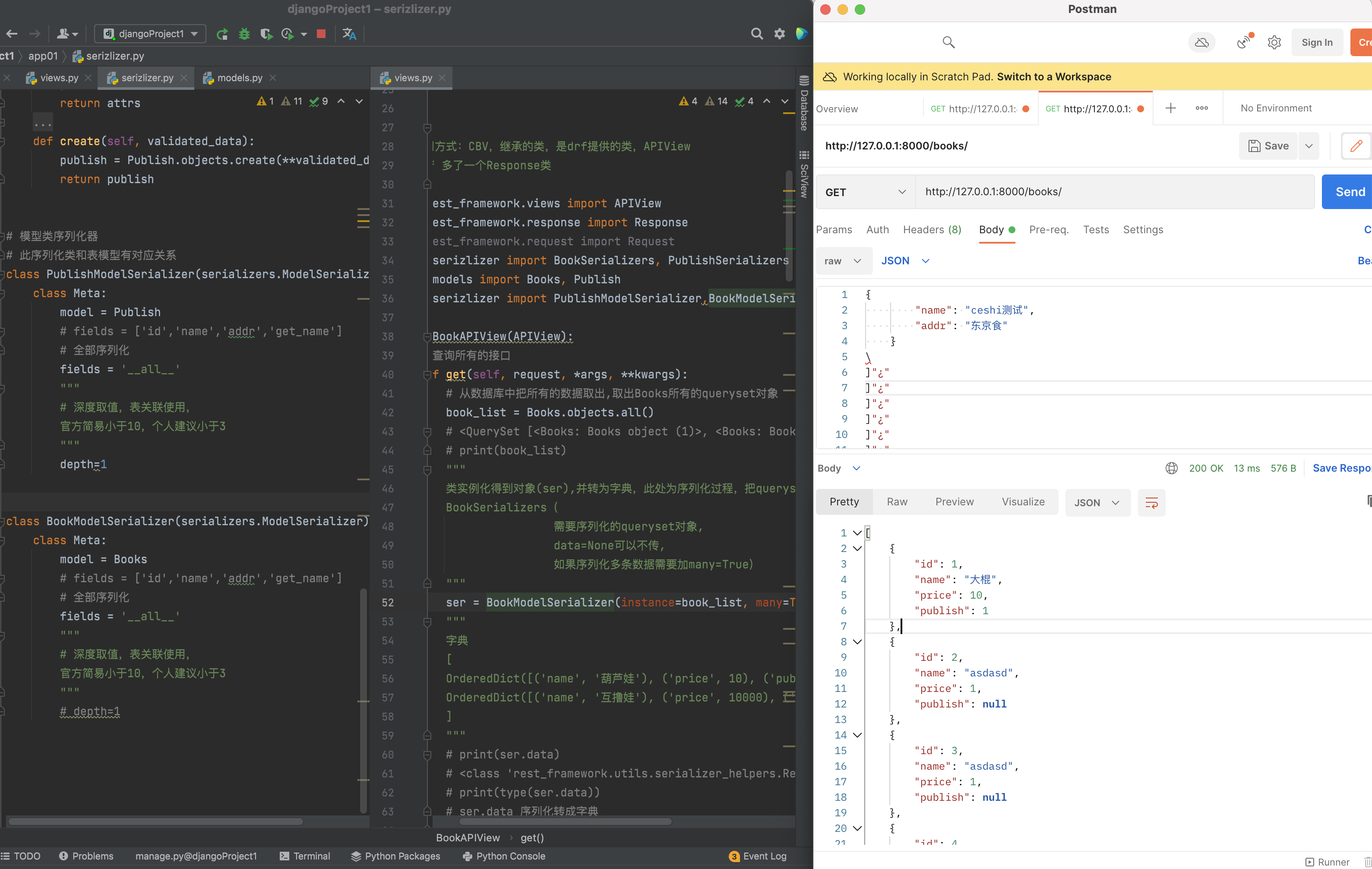
使用depth深度查询
但是无法限制获取到深度查询字段。
模型类序列化器之重写字段

注:使用serializers.ModelSerializer,内部重写了create和updata方法。不用再手动重写这两个方法。
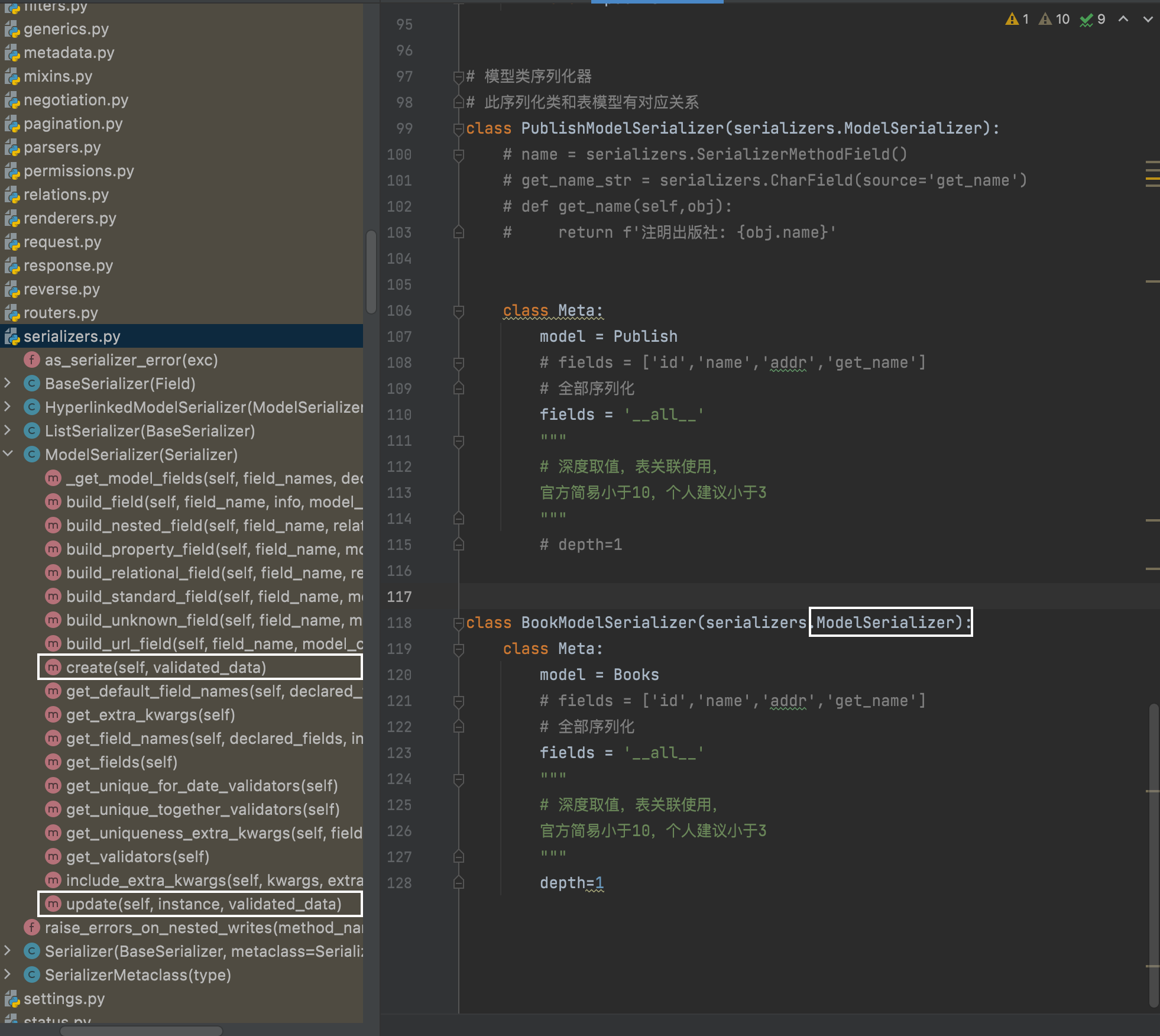
局部钩子和全局钩子与数据的验证一致。
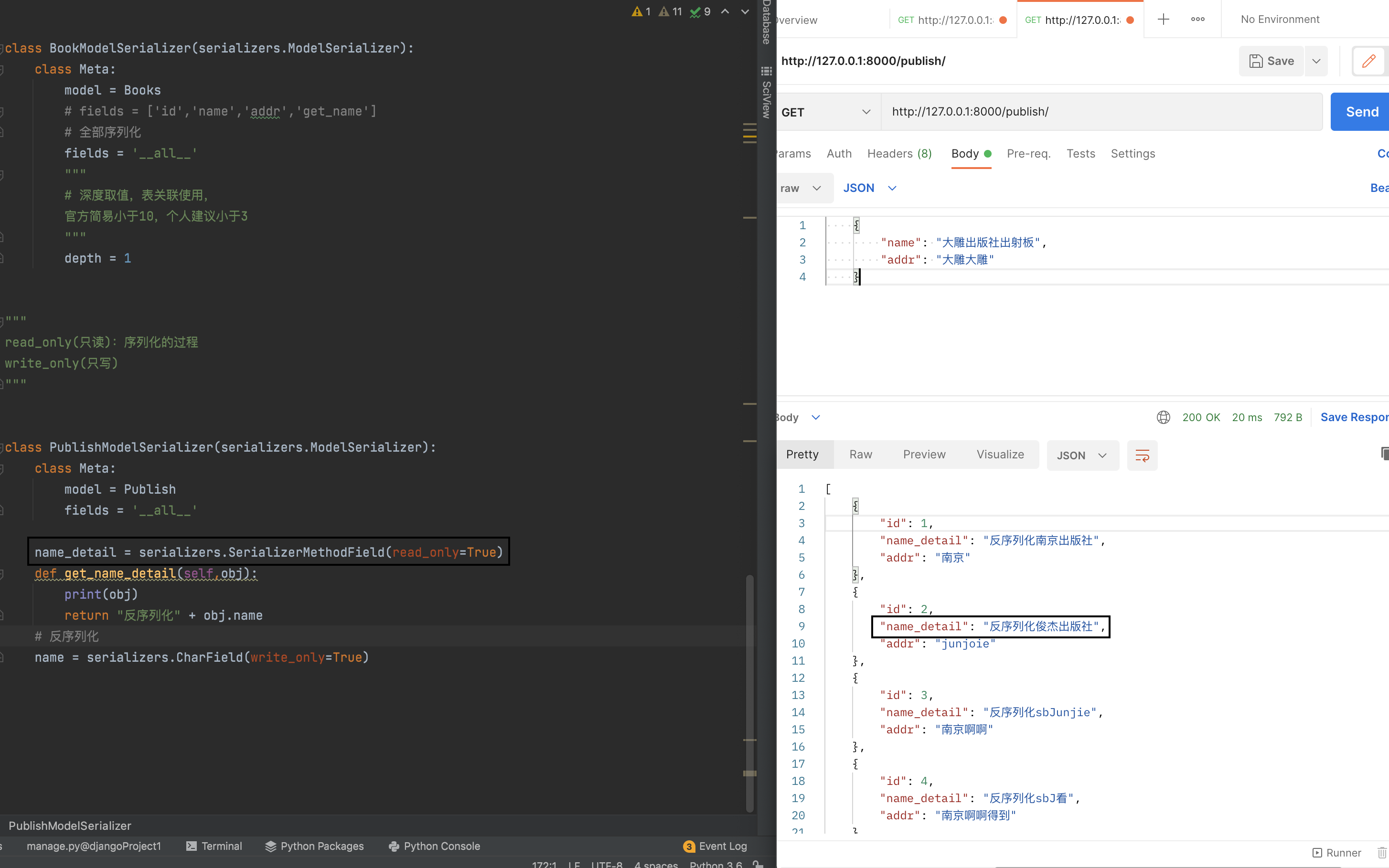
read_only 和 write_only
反序列化 write_only
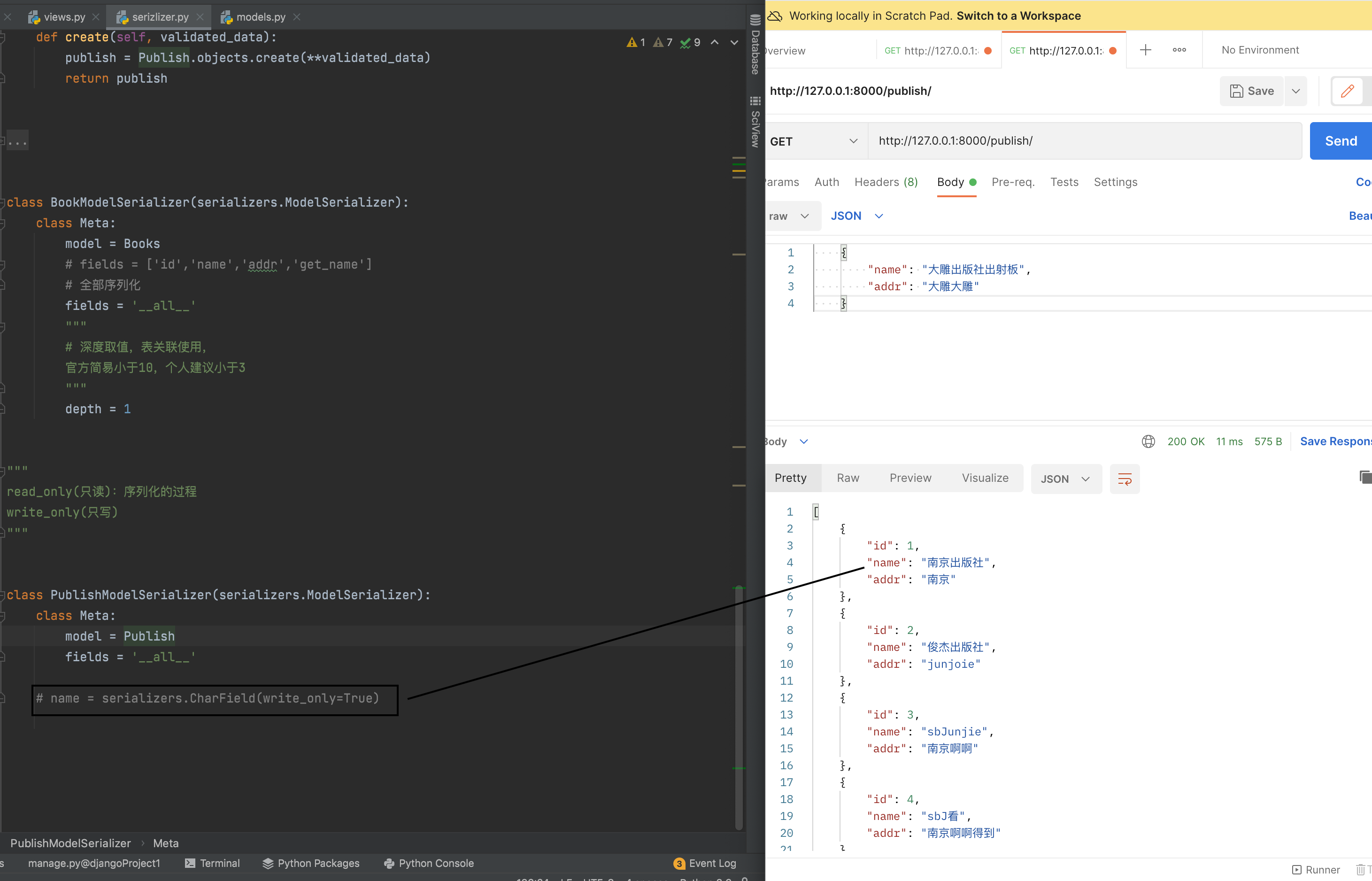
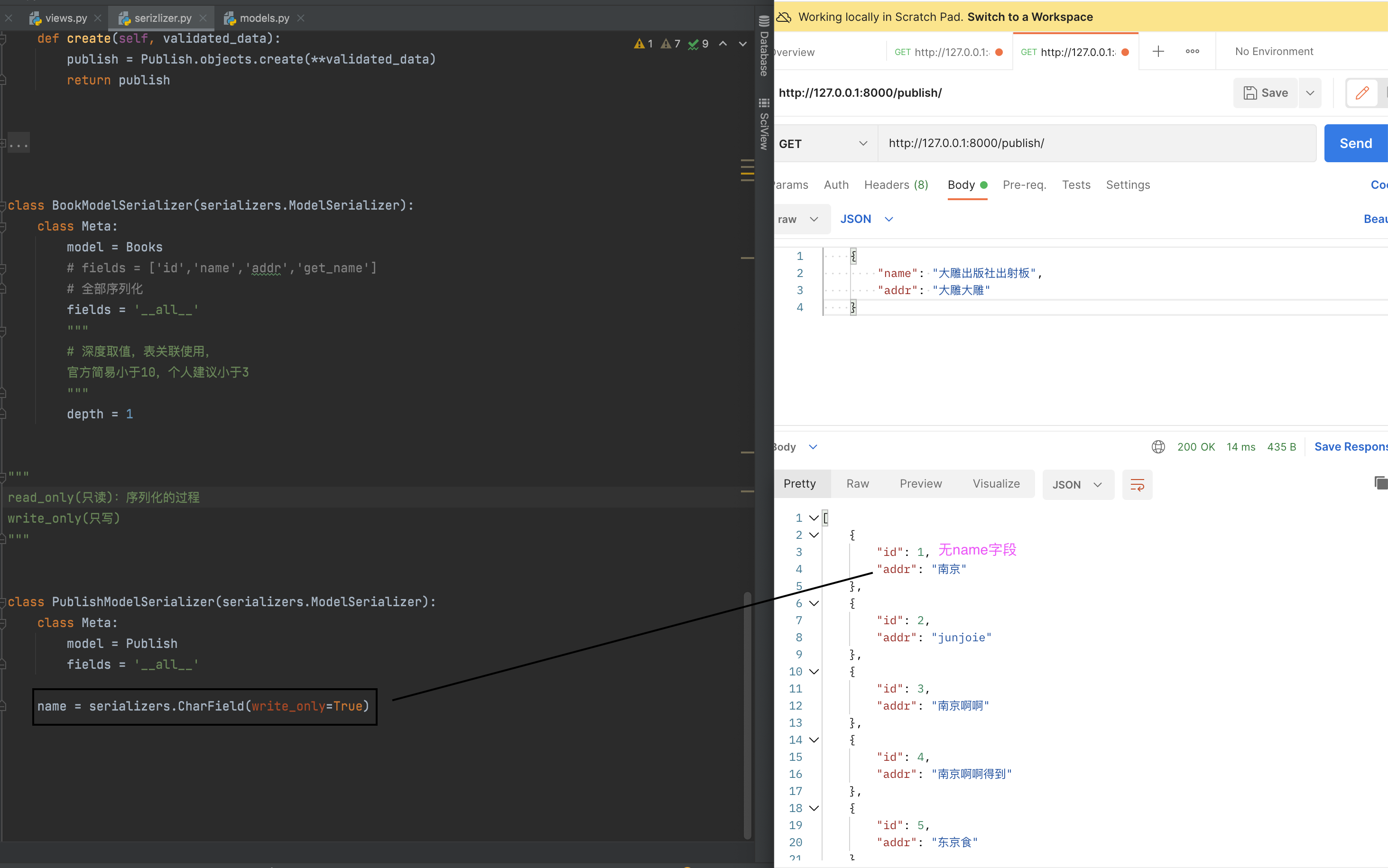
序列化 read_only
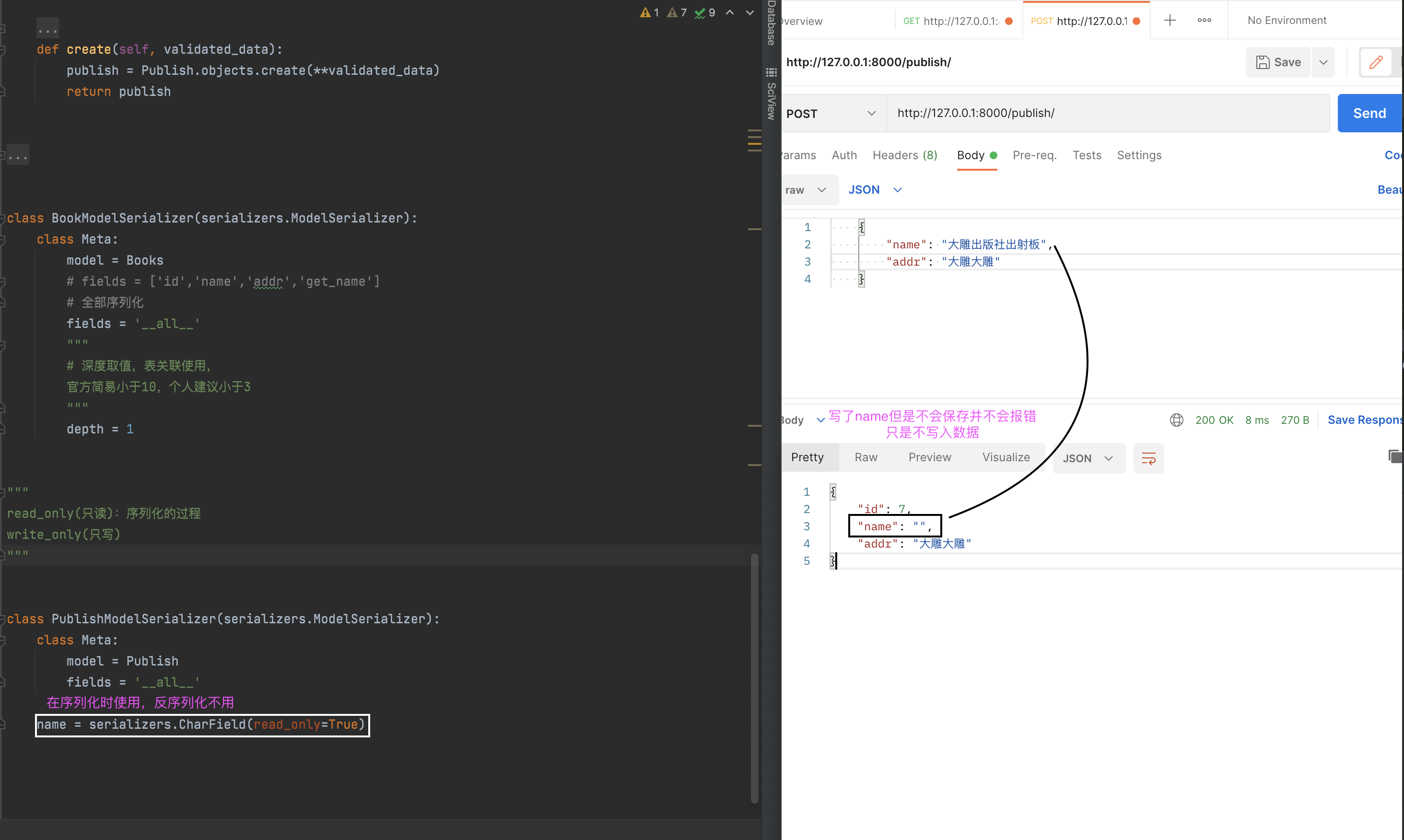
进阶用法
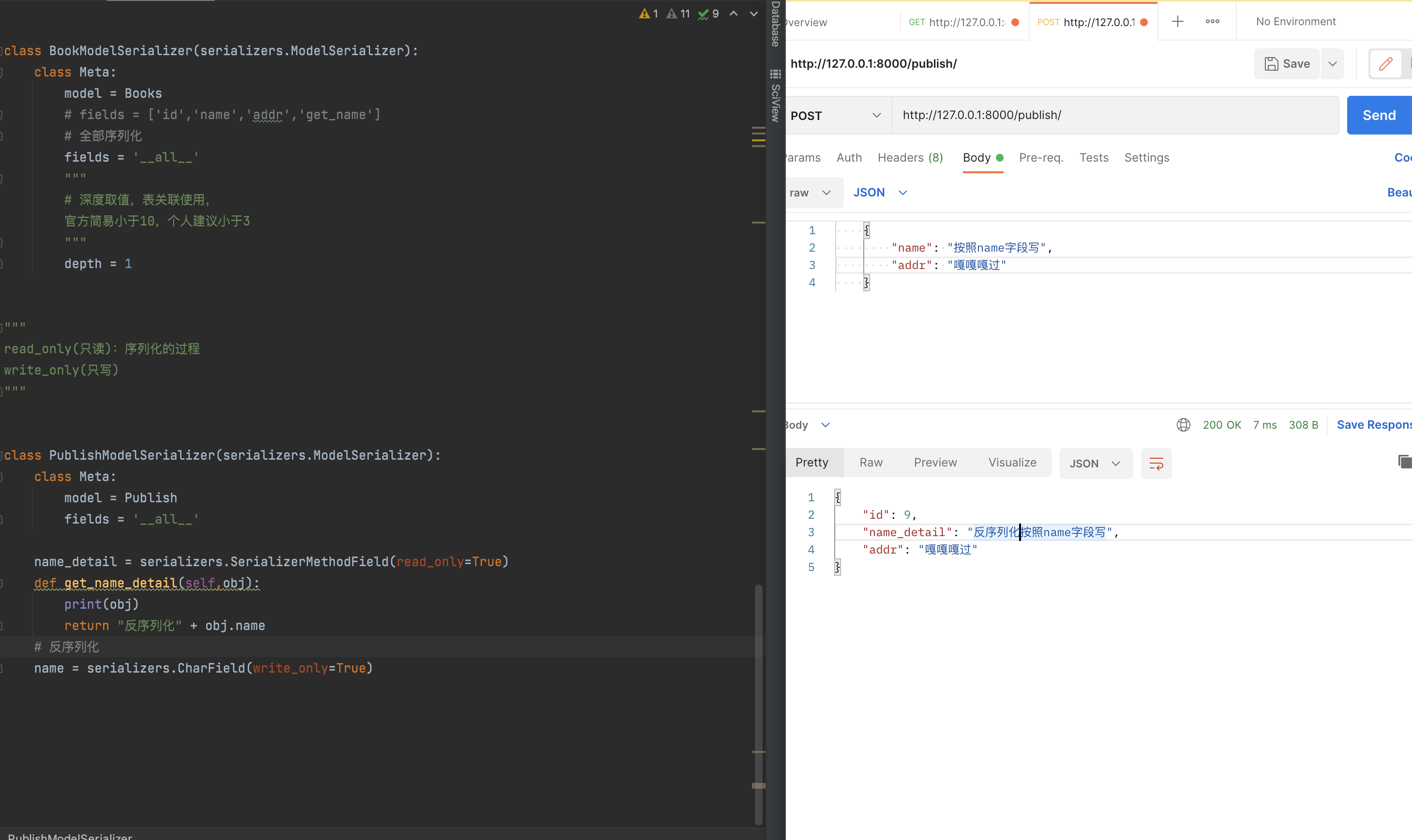
最终用法:extra_kwargs,额外给字段传递参数。
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = Publish
fields = '__all__'
# 反序列化
# name = serializers.CharField(write_only=True)
extra_kwargs = {'name':{'write_only':True,'max_length':8}}
name_detail = serializers.SerializerMethodField(read_only=True)
def get_name_detail(self,obj):
print(obj)
return "反序列化" + obj.name
# # 反序列化
# name = serializers.CharField(write_only=True)上述总结:
1.继承ModelSerializer
2.字段是通过表模型映射过来。
class Meta:
model=Publish # 表模型
fields='__all__' # 序列化字段
# exclude=['id'] 排除指定字段
# depth 深度,一般不用
3.可以重写字段,不重写字段则使用表型字段以及关系
name = serializers.SerializerMethodField()
get_name_str = serializers.CharField(source='get_name')
def get_name(self,obj):
return f'注明出版社: {obj.name}'
4.可以扩写字段(表模型中没有字段)
5.反序列化是,字段自己的校验规则,映射了表模型的
6.局部钩子和全局钩子完全一样。
7.read_only 和 write_only
# 反序列化使用
# name = serializers.CharField(write_only=True)
# 序列化使用
# name = serializers.CharField(read_only=True)
8.extra_kwargs
# 额外给字段传递参数
# name = serializers.CharField(write_only=True)
extra_kwargs = {'name':{'write_only':True,'max_length':8}}














 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









