






一、正则表达式
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个 “规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。可以使用grep、sed、awk命令来测试正则表达式。
二、grep 文本过滤明令
1.gaep 概念
grep 命令是一种强大的文本搜索工具,根据用户指定的”模式“对目标文本进行匹配检查,打印匹配到的行。由正则表达式或者字符及基本文本字符所编写的过滤条件
2.基本命令
用法:grep 匹配条件 处理文件
基本命令:
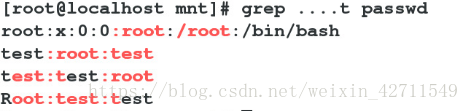
grep root passwd 过滤出passwd中root字符
grep ^root passwd 以root开头的

grep root$ passwd 结尾
grep -i root passwd 忽略大小写过滤

grep root passwd | grep -i -E "^root|root$" -v 过滤root 在中间的行

grep -E -i "^root|root$" passwd 过滤以root开头或结尾的行忽略大小写
grep -E -i -v "^root|root$" passwd 过滤以root开头或结尾以外的行忽略大小写
3.grep 中的正则表达式
^westos 以westos开头 westos$ 以westos结尾 'w....s' 以w开头s结尾 'w.....' 以w开头 '.....s' 以s结尾

4.参数的介绍
-E 扩展正则表达式 -i 忽略大小写 -v 反向过滤把不符合条件的屏蔽
* 字符出现 0-任意次
^
锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$
锚定行的结束 如:'grep$'匹配所有以grep结尾的行
\<
锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\>
锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\}
重复字符x,m次,如:'o\{5\}'匹配包含5个o的行。
x\{m,\}
重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\}
重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行
x\{ab\}\{m\}ab 关键字符出现 m 次
.* 关键字之间匹配任意字符
\+ 匹配一个或多个先前的字符。
\? 匹配零个或一个先前的字符。



三、sed 行编辑器
1.sed 概述
sed 用来操作纯 ASCLL 码的文本。处理时,把当前处理的行存储在临时缓冲区中,称为”模式空间“
可以指定仅仅处理哪些行。
sed 符合模式条件的处理,不符合条件的不予处理,处理完成后把缓冲区的内容送往屏幕。
2.sed 命令格式
调用sed 命令的两种形式:
sed [options] 'command' file
sed [options] -f scriptfile file
3.sed 对字符的处理
n读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
=打印当前行号码
p 显示 d 删除 a 添加 c 替换 w 写入 i 插入
1)p 显示模式操作
sed -n ' /\:/p' fastab 显示文件中带 :的行 其中 \ 表示转译
sed -n '/UUID$/p' fastab 显示文中以UUID 结尾的行
sed -n '/^UUID/p' fastab 显示文中以UUID 开头的行
sed -n '2,6p' fastab 显示文中2-6行

sed -n '2,6!p' fastab 不显示文中2-6行

sed -n '3p;5p;6p' fastab 显示文中的3行,5行,6行
sed -n -e '2p' -e '6p' fastab 显示第二行和第六行 (-e 表示多个条件)
sed -ne '2p;6p' fastab 显示第二行和第六行
sed -ne '2!p;6!p' | uniq -d fastab 显示除了第二行和第六行以外的行
2)d 删除模式
sed ' /^#/d' fastab 删除文件中以#开头的行

删除fstab中不以#开头的行

sed -e ' /^$/d' fastab 删除空格行
sed '/UUID$/d' fastab 删除文中以UUID 结尾的行
sed '/^UUID/d' fastab 删除文中以UUID 开头的行
删除fstab中5-7行

删除fstab中第5和第7行

3)a 添加模式 (在匹配行后添加)
sed '/^UUID/a\ hello' fstab 在以UUID开头行的后面添加hello (sed要求命令a后面有一个反斜杠。)
sed '/^UUID/a\ hello\ntest' fstab 在以UUID开头行的后面添加hello行和test 行 (\n 表示换行添加)
4)i 插入模式(在匹配行前插入)
sed '/^UUID/i\hello' fstab 在以UUID开头行的前面插入hello (sed要求命令i后面有一个反斜杠。)
5)替换:c命令
sed '/^UUID/c\hello' fstab 在以UUID开头行替换成hello (sed要求命令c后面有一个反斜杠。)
6)w 写入模式
sed -n '/test/w file' example 在example中所有包含test的行都被写入file里。
4.sed 其他用法
1)sed -n -f prctise fstab 对fstab执行prctise 策略
2)字符替换
sed 's/nologin/ /g' passwd 将passwd全文的nologin替换成空格

sed '1,5s/nologin/ /g' passwd 将前5行的nologin替换成空格

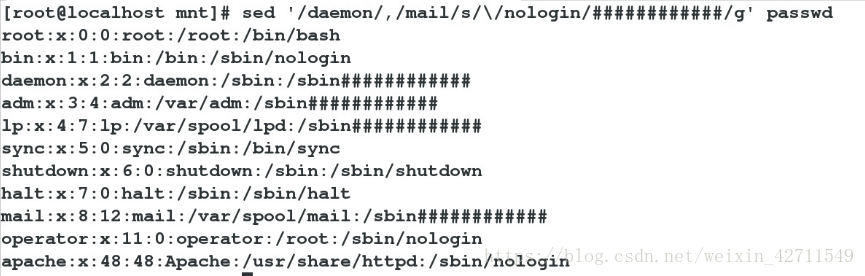
将/daemon/至/mail/中的/nologin替换成#
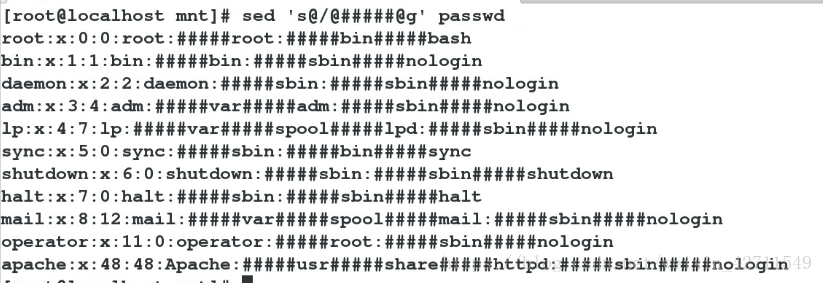
3)sed 's@/@#####@g' fstab @相当于/的意思
4)G 用法
sed 'G' fstab 将fstab每行后插入空行
sed '$!G' fstab 除了最后一行,每行后插入空行
5)=
sed '=' file 显示行号
sed -n '/^UUID/=' fstab 只显示行数
sed '/^UUID/=' fstab 显示行数和内容
sed '=' passwd | sed 'N;s/\n/ /g' 在文件的行前面加行号(N追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。)

四、awk 报告生成器
1.awk 概述
awk 是一种用于处理文本的编程语言工具。awk 会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行做一些总结性质的工作,在命令格式上分别体现如下:
BEGIN{ }:读入第一行文本之前执行,一般用来初始化操作
{ } :逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令块
END:处理完最后一行文本之后执行,一般用来输出处理结果
2.awk 基本用法 (linux 上默认使用gawk)
1)awk -F : 'BEGIN{print "name:"}{print $1}' passwd
在passwd文本中以:为分隔符,处理前打印name,打印第一列
2)awk -F : 'BEGIN{print "name:"}{print $1}'END{print NR}' passwd
在passwd文本中以:为分隔符,处理前打印name,打印第一列,处理完成后打印行数
(NR 行 NF 列)

3)awk -F : '/bash$/{print $1}' /etc/passwd 以bash结尾的用户
4)awk -F : '/bash$/||/sh$/{print $1}' /etc/passwd 以bash 或者以 sh 结尾的用户
5)awk -F : 'NR==3' passwd 以:为分隔符,打印第三列
6)awk 'BEGIN{N=0}{N++}END{print N}' passwd 从零开始统计行数

7)awk '/^a|nologin$/{print}' /etc/passwd 打印以a 开头或者以nologin 结尾的行

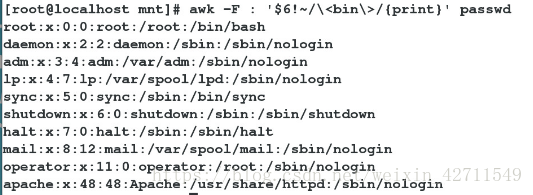
8)awk -F : '$6~/\<bin\>/{print}' passwd 打印第六个字段为 bin的行 (即用户家目录为bin的行)

9) awk -F : '$6!~/\<bin\>/{print}' passwd 打印第六个字段不为 bin的行
3.awk 测试
抓取eth0网卡的ip

统计在系统中可以登陆系统的用户















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









