







使用RNN(循环神经网络)对电影评论进行情感分析,结果为positive或negative,分别代表积极和消极的评论。至于为什么使用RNN而不是普通的前馈神经网络,是因为RNN能够存储序列单词信息,得到的结果更为准确。
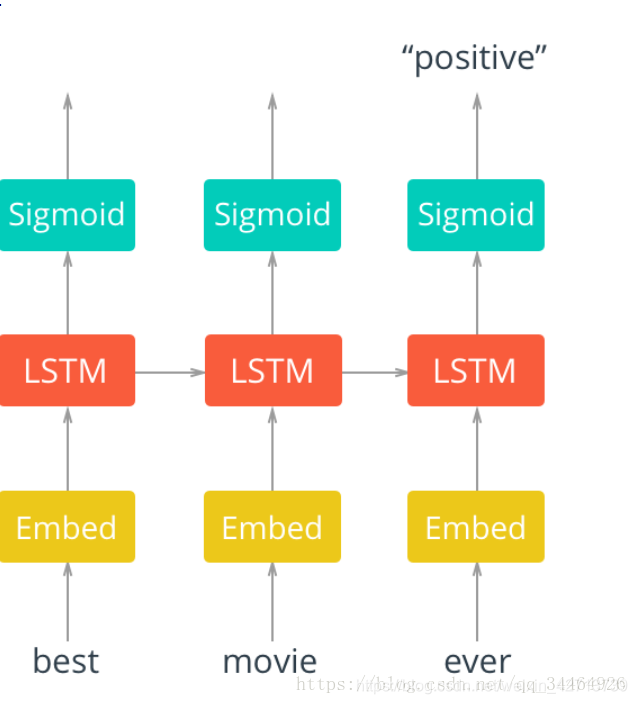
使用的RNN模型架构如下
上代码:
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
"""在这里我们将使用RNN(循环神经网络)对电影评论进行情感分析,结果为positive或negative,分别代表积极和消极的评论。
至于为什么使用RNN而不是普通的前馈神经网络,是因为RNN能够存储序列单词信息,得到的结果更为准确。这里我们将使用一个带有标签的影评数据集进行训练模型。"""
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
# fix random seed for reproducibility
np.random.seed(7)
#加载数据集,但仅保留前10000个字,其余为零
top_words = 10000
# 最长填充序列
max_review_length = 80
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data('F:/PycharmProjects/TensorFlow-2.0-Tutorials/09-RNN-Sentiment-Analysis/data/imdb.npz', num_words=top_words)
# X_train = tf.convert_to_tensor(X_train)
# y_train = tf.one_hot(y_train, depth=2)
#将序列填充到相同的长度:80。
x_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_length)
x_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_length)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
class RNN(keras.Model):
def __init__(self, units, num_classes, num_layers):
super(RNN, self).__init__()
# self.cells = [keras.layers.LSTMCell(units) for _ in range(num_layers)]
#
# self.rnn = keras.layers.RNN(self.cells, unroll=True)
self.rnn = keras.layers.LSTM(units, return_sequences=True)
self.rnn2 = keras.layers.LSTM(units)
# self.cells = (keras.layers.LSTMCell(units) for _ in range(num_layers))
# #
# self.rnn = keras.layers.RNN(self.cells, return_sequences=True, return_state=True)
# self.rnn = keras.layers.LSTM(units, unroll=True)
# self.rnn = keras.layers.StackedRNNCells(self.cells)
# have 1000 words totally, every word will be embedding into 100 length vector
# the max sentence lenght is 80 words
self.embedding = keras.layers.Embedding(top_words, 100, input_length=max_review_length)
self.fc = keras.layers.Dense(1)
def call(self, inputs, training=None, mask=None):
print('x', inputs.shape)
"""首先,将单词传入embedding层,之所以使用嵌入层,是因为单词数量太多,使用嵌入式方式词向量来表示单词更有效率"""
# [b, sentence len] => [b, sentence len, word embedding]
x = self.embedding(inputs)
"""其次,通过embedding层,新的单词表示传入LSTM cells。这将是一个递归链接网络,所以单词的序列信息会在网络之间传递"""
x = self.rnn(x)
x = self.rnn2(x)
# print('rnn', x.shape)
"""最后,LSTM cells连接一个sigmoid output layer。使用sigmoid可以预测该文本是积极的还是消极的情感"""
x = self.fc(x)
print(x.shape)
return x
def main():
units = 64
num_classes = 2
batch_size = 32
epochs = 5
model = RNN(units, num_classes, num_layers=2)
model.compile(optimizer=keras.optimizers.Adam(0.001),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
"""fit()用于使用给定输入训练模型."""
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,
validation_data=(x_test, y_test), verbose=1)
"""model.predict只返回y_pred"""
out = model.predict(x_train)
print("out:", out)
"""evaluate用于评估您训练的模型。它的输出是准确度或损失,而不是对输入数据的预测。"""
scores = model.evaluate(x_test, y_test, batch_size, verbose=1)
print("Final test loss and accuracy :", scores)
if __name__ == '__main__':
main()















 3839
3839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









