







前言
近期业务需求,需对某网站的新闻列表页的标题、链接以及跳转子链对新闻内容进行提取与下载。因此,采用Python 的Beautiful Soup完成业务需求,本文为学习beautifulsoup包的学习笔记。
在此之前声明本文以下用词的定义:
- 主链:新闻列表页的链接
- 子链:新闻列表页中每条新闻的链接,即新闻详情页的链接
- requests模块:一个支持HTTP服务的模块,主要用于HTTP请求
- re模块:正则表达式,不过多解释,等过两天单独整理一版python正则表达式的博文
BeautifulSoup安装
当前最新版本为Beautiful Soup 4.4.0(中文官网链接),首先进行beautiful soup的安装,最新的包是兼容python2和python3的,安装方法:
$ pip install beautifulsoup4
在第一次安装失败,提示我pip版本低,需要更新版本:
输入更新指令,完成pip更新(注:需先cd进对应python根目录):
$ python.exe -m pip install --upgrade pip
第二次beautifulsoup安装成功:
这里出现的报错(WARNING)是连接超时的原因,不过最后还是成功的安装下来,此条报错先忽略。
然后是安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml,官方文档推荐使用lxml。所以我们先来安装lxml解析器:
$ pip install lxml
此外,因为涉及跨页面提前新闻内容,所以也需要安装requests包:
$ pip install requests
此外,页面链接的参数部分若有固定位置变量规律,可补充安装正则包:
$ pip install re
代码实现
获取目标html
这里有两个不同的方法实现,分为本地html读取与request直接请求url
本地html读取(更稳定)
首先将网页保存在本地指定文件夹中
代码:
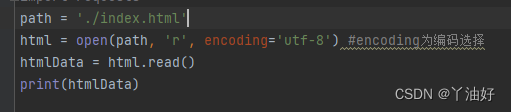
print出数据,调试器显示运行成功:

request直接请求url(更方便)

将标题、日期、子链提取出来
代码:
这里拓展一下,关于soup.find_all()方法:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5698
5698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









