







机器学习中的Normalization研究笔记
这是一篇笔记,原文见:https://zhuanlan.zhihu.com/p/43200897
1.Mini-Batch SGD
1)一种模型优化算法 —— 随机梯度下降。
2)描述:将训练集合(N)按Batch Size(b)分为N/b份,每份称为一个Mini-Batch,跑完一个Mini-Batch为一个Step,跑完所有Mini-Batch即为一个Epoch。完成一个Epoch后,将训练数据打乱顺序,开始下一个Epoch。在每个Mini-Batch中更新参数,更新过程如下图:
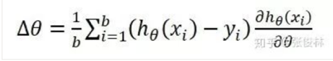
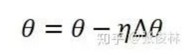

∆ø前面是学习率。
3)Batch Size小,模型泛化能力强。
4)为什么要聊SGD?
BN是基于SGD引出的方法,旨在优化SGD的性能。
2.Normalization
1)目的:规范化——希望转换后的数满足某种条件。
2)基础算法:
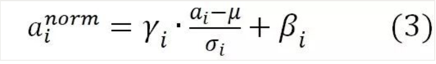
ai是某个神经元的激活值。
均值和方差来源于一个激活值的集合S。
这个集合的选取方法有讲究。
先不看S,这种算法主要分两步:
1-将ai规范到0-1之内。
2-而后再通过两个参数,来补偿ai的非线性能力。
3)位置
如图:(后者效果好,前者最早使用)

4)前向神经网络和CNN中的BN的S划分方法
S的划分都是同一个神经元,在不同Batch下得到的输出构成的。
BP:
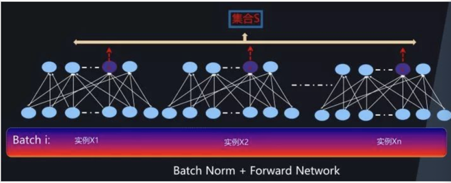
CNN:

3.BN的改进
所谓改进,就是上面说的S集合的划分方法上有所改进。
那为什么要改进:
1)如果Batch Size太小,BN的效果会下降。
因为Batch Size小,所以S比较小,所以数据特异性造成的噪音大,
就比如把你和马云放到一个Batch里面算平均薪资,肯定会有问题。
2)从统计上计算会弱化单体特征。
3)RNN上效果不好。
因为其输入大小不统一。
4)测试时,因为没有batch,所以没有统计量。
一般用训练时记录下来的均值方差。
这就没有什么意义。
这些问题都来源于:在BN时,统计值依赖一个Batch,会造成相互影响。
改进算法: 修改S
1)Layer Normalization
同层所有输出激活值构成S。
RNN中有效的一种方法。
2)Instance Normalization
只有CNN可用(唯一输出二维平面),将一个二维输出作为S。
3)Group Normalization
CNN用。
将同层输出的平面按通道分组,每组得到一个S。
4.BN的作用原理
随着神经网络的加深,会出现梯度消失和爆炸。
而如果神经网络参数具有Re-scaling 不变性,就能有效缓解这种情况。
因为BN/LN/IN/GN都多多少少有Re-scaling 不变性。
还有一层原因:
SGD寻优是在网络的损失曲面上游走而找到全局最小值。
因为网络深度的增加,使得曲面很复杂,有很多坑坑洼洼。
很容易陷入局部最小值。
所以BN的另一个作用是平滑损失曲面。















 3058
3058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









