







一、去重复:distinct
A表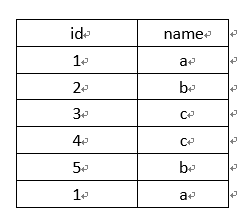
1、查询单列时
select name from A表,结果是
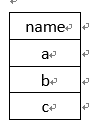
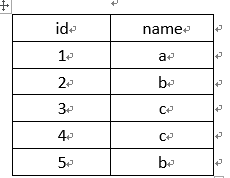
2、查询多列时,需要所有列的都相同才去重复
select id,name from A,结果是(需要id和name都相同时才去重)
二、查询语句中使用运算符
select ename as 员工,sal*12 as 年薪,sal as 月薪 from emp;
员工 年薪 月薪
------------- ---------- ----------
李小明 9600 800
李大明 7200 600
李小小 2400 200
李春春 9600 800
三、字符串连接concat(string,string)
select concat(s_name,s_sex) from 表A
s_id s_name s_sex
01 张三 男
02 李四 男
03 王五 男
04 赵六 null
查询结果
CONCAT(s_name,s_sex)
张三男
李四男
王五男
赵六
四、sql执行顺序
from>join>on>where>group by(开始使用select中的别名,后面的语句中都可以使用)>聚合(avg,sum…)>having>select>distinct>order by
select 考生姓名, max(总成绩) as max总成绩
from tb_Grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
在上面的示例中 SQL 语句的执行顺序如下:
(1). 首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据
(2). 执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据 。
(3). 执行 GROUP BY 子句, 把 tb_Grade 表按 “学生姓名” 列进行分组(注:这一步开始才可以使用select中的别名,他返回的是一个游标,而不是一个表,所以在where中不可以使用select中的别名,而having却可以使用)
(4). 计算 max() 聚集函数, 按 “总成绩” 求出总成绩中最大的一些数值
(5). 执行 HAVING 子句, 筛选课程的总成绩大于 600 分的.
(7). 执行 ORDER BY 子句, 把最后的结果按 “Max 成绩” 进行排序.
参考:猪哥66
五、mysql默认情况下不区分大小写
可以修改mysql配置文件的修改内容如下:
[mysqld]
…
lower_case_table_names = 1
六、where 多条件过滤,把过滤多的条件放在前面可以提高性能。
SELECT子句中避免使用‘*’
七、in,not in
in用法:select * from b where 列名2 in (select 列名1 from a where 条件) ;
解释:假如select 列名1 from a where 条件 语句的查询结果是(1,2,3)
select * from b where 列名2 in(1,2,3)就是把列名2等于1或2或3的记录找出来。(反之not in就是找出列名2不等于1或2或3的记录)
八、LIKE,not LIKE
语法如下:
WHERE column LIKE pattern
WHERE column NOT LIKE pattern
例子:
SELECT * FROM user WHERE username LIKE ‘小%’;
小%查找username以"小"开头的记录,%小则表示以”小”结尾,%小%则表示包含“小”字符。(NOT LIKE则意思相反)
九、order by
order by默认升序(asc),order by desc则为降序
十、limit
limit 0,3(当前页-1)*每页数
例子:
SELECT * FROM table LIMIT 5,10;检索6~15行的记录
select * from table limit 5;检索前5行的记录相当于limit 0,5
通常order by 与limit使用可以查找出记录的最高或最低值
十一、where
where在返回查询结果之前过滤,不能使用聚合函数,where执行在聚合函数前。
十二、having
having在返回结果后进行过滤,可使用聚合函数(聚合函数括号中可以使用where能使用的字段),对查出来的结果过滤或者可以使用group by后面的字段
十三、where与having区别
1、where与having查询结果一样:
SELECT regagent,amount FROM `cy_pay_ok` having amount>1000;
SELECT regagent,amount FROM `cy_pay_ok` WHERE amount>1000;
能用having是因为我前面的查询select语句中已经查询出amount字段,如果select 语句中没有amount是会报错的。
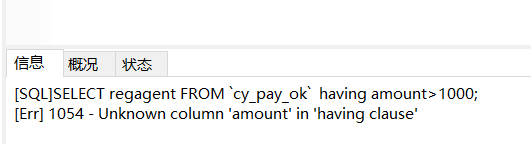
这样查询,having语句是会报错的:
SELECT regagent FROM `cy_pay_ok` having amount>1000;
SELECT regagent,amount FROM `cy_pay_ok` WHERE amount>1000;
2、having能用,where不能用
查询每种goods_category_id商品的价格平均值,获取平均价格大于1000元的商品信息
select goods_category_id , avg(goods_price) as ag from sw_goods group by goods_category having ag > 1000
select goods_category_id , avg(goods_price) as ag from sw_goods group by goods_category where ag > 1000
where后面应取的是数据库的字段,having是前面的结果集中查询出来什么字段就后面就可以用什么字段
十四、group by
出现在select列表中的字段,如果不是出现在组函数中,那么必须出现在group by 子句中。
数据表:
B_id(部门) y_id(员工) city_id(城市) money(销售金额)
"1" "1" "1" "200"
"1" "1" "1" "300"
"1" "2" "1" "400"
"2" "3" "1" "100"
"2" "3" "1" "500"
"2" "4" "1" "10000"
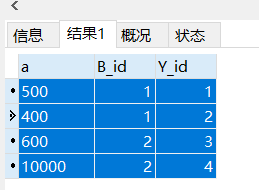
如根据部门ID和员工ID对销售记录表进行分组,因为一个员工可能有多条销售记录,查询每个员工在每个部门的总销售金额
SELECT SUM(money)as a,B_id,Y_id from money_list GROUP BY Y_id,B_id
查询结果:
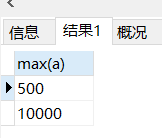
再查询每个部门的最大销售金额
SELECT max(a) from (SELECT SUM(money)as a,B_id,Y_id from money_list GROUP BY Y_id,B_id)c GROUP BY c.B_id
查询结果:
最后查询每个部门销售冠军
SELECT b.B_id,b.Y_id,amonut from (SELECT sum(money)as amonut,B_id,Y_id from money_list GROUP BY B_id,Y_id)b where b.amonut in(SELECT max(a) from (SELECT SUM(money)as a,B_id,Y_id from money_list GROUP BY Y_id,B_id)c GROUP BY c.B_id)
十五、聚合函数
聚合函数sum、avg、count、max、min,作用于一组数,返回一个结果。
1、sum统计函数
如统计某个员工销售金额
SELECT SUM(money)as a,B_id,Y_id from money_list GROUP BY Y_id,B_id
2、avg平均函数
如查询学生的平均成绩
SELECT avg(score),Sid from sc GROUP BY sid
3、count()求个数/记录数
如查询每个学生所学的课程
SELECT COUNT(*),Sid from sc GROUP BY sid
4、max、min查询最大/小值
如查询每门课程的最大分数,最小分数
SELECT max(score),min(score),cid from sc GROUP BY Cid
十六、多表查询
select * from 表1,表2(没有连接条件结果会返回笛卡尔积(笛卡尔积就是表1的行数乘上表2的行数得到的结果集,结果集的列就是两表的列相加),消除笛卡尔积就要加上两表的连接条件,n张表连接查询,至少有n-1个连接条件。
如两表连接产生笛卡尔积:
teacher表(5条数)
course表(4条数)

两表相连
SELECT * from course,teacher
查询结果(20行,5列)

加上两表连接条件,查询两表中tid相等的记录
SELECT * from course,teacher WHERE course.tid=teacher.Tid
查询结果

十七、子查询
子查询就是嵌套在主查询中的查询,它可以出现在主查询中所有位置,包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY
如查询学生表的学生姓名和成绩表的学生的成绩
SELECT (SELECT sname from student where student.Sid=sc.Sid)as 学生姓名,score as 成绩 from sc
如找到数学课程的最大成绩
方法一:SELECT MAX(score) from (SELECT sc.cid,score from sc,course where sc.Cid=course.Cid and course.Cname='数学')c
方法二:SELECT max(score) from sc where cid=(SELECT cid from course where Cname='数学')
十八、自连接
自连接就是这个表有一列的数据恰恰和这张表的另一列有关联!比如公司员工表里存着所有员工的信息,员工和员工之间存在上下级的关系,员工表里有一个字段专门存放员工上级的员工编号(也就是该表某一个员工的姓名),如果我想查看这么一种关系,那么使用自连接就可以了,这个表存在上级姓名的列对应这个表员工姓名的列。
如存在表:员工编号、员工名称、员工上级编号

SELECT b.Tname as 员工,a.Tname as 上级 from productdir a,productdir b where a.id=b.Nid
查询结果:

十九、delete from和truncate table
1、delete from语句可以使用where对要删除的记录进行选择。而使用truncate table将删除表中的所有记录。因此,delete语句更灵活。
二十、日期
1、查询出来的日期加10天:SELECT DATE_ADD(HIREDATE,INTERVAL 10 dAY) FROM EMP;(可正可负,正表示加,负为减)hour、week、year、day;(date_sub也可以date_sub(2019.11.11 11.11.11,INTERVAL 2 HOUR))
2、从日期中提取年:SELECT * from emp where YEAR(HIREDATE)=‘1981’;(SELECT * from emp WHERE HIREDATE BETWEEN ‘1981-01-01’ and ‘1982-01-01’)
3、Now()当前系统时间
4、日期current_date(),当前时间current_time();
5、查询时间差:datediff(时间一,时间二);
6、Format(x,d)如:format(123456.789,2)返回123,456.79
7、Date_format(%Y-%M-%D %h:%s:%i)日期格式
8、UNIX_TIMESTAMP(date)将参数值以秒形式返回。From_unixtime返回yyyy-MM-DD HH:MM:SS或指定format日期
二十一、ifull
iffull(expr1,expr2)如果expr1不是空值则返回expr1,否则返回expr2.(SELECT IFNULL(COMM,0) from emp;)
二十一、连接
一、内连接;inner join两表相同部分
二、左连接:left join左外连接是A表的所有行匹配上B表得出的结果集
三、右连接:right join右外连接是B表的所有行匹配上A表得出的结果集
四、全连接:outer join全连接是A表的所有行并上B表的所有行得出的结果集
具体说明可参考:一只大头















 1194
1194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









