







图解:
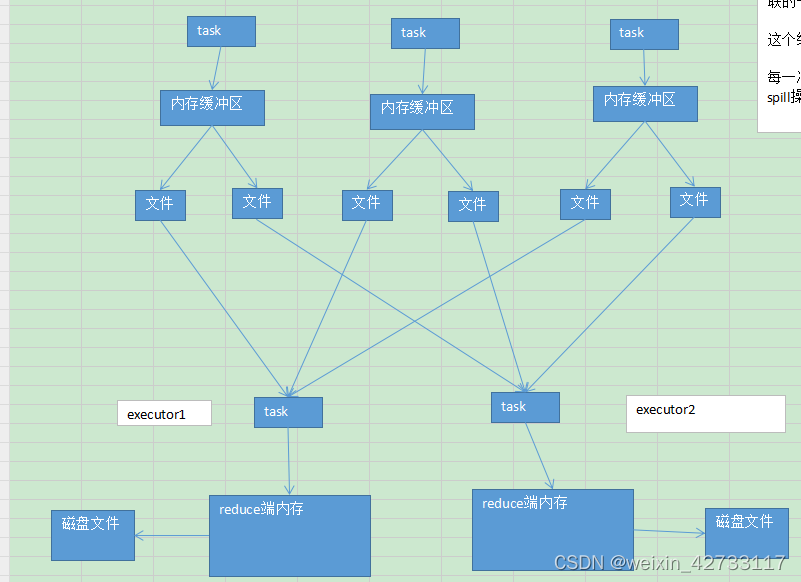
在map端,task写文件之前,都有一个内存缓冲区,如果每个task数据量不大,那么就可以不溢写文件,直接利用内存计算
在reduce端,进行聚合计算的时候,同样也有0.2(default)的内存比例是用来计算的,匿名函数规则计算,如果内存足够,则直接在内存中计算,否则需要spill到磁盘中,进行交互计算
实践:
conf.set(“spark.shuffle.file.buffer”,“64”),默认32k
conf.set(“spark.shuffle.memoryFraction”,“0.3”),默认0.2















 2083
2083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









