







1、map转换算子调优(mappartition)
原理:map是对RDD中,每一行Row数据进行自定义转换处理,当数据量有一定程度时,自定义函数会执行多次,增加开销,这时候可以通过mapPartition来处理,他会一个分区的数据同时提交执行自定义函数转换RDD
图解:
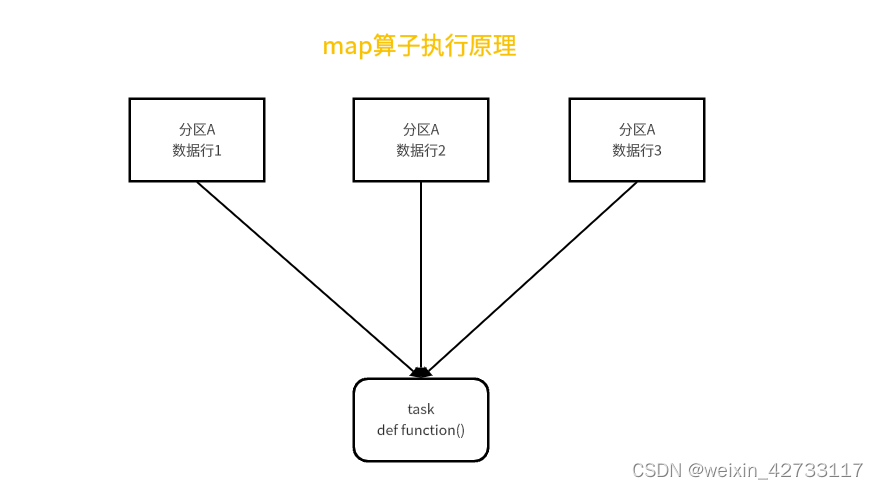
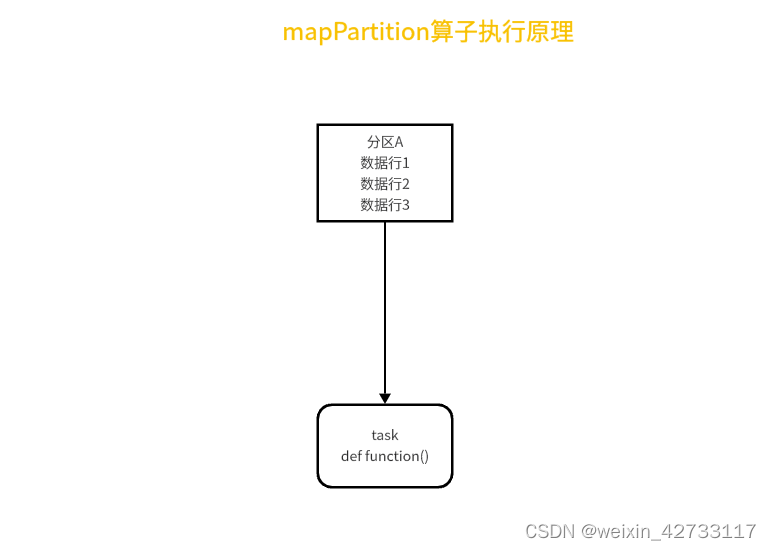
实践:使用之前先评估RDD里面每个分区的数据量是多大,然后每个Excutor分到的内存是多大,避免同时处理大量数据造成OOM,在用户画像项目里面,我们拿到每行的数据转换成Tuple<sessionid,Row>的格式等很多转换格式的map都有做类似的优化
2、foreachpartition优化foreach写入关系型数据库链接数
定义:跟mappartition差不多意思,注意需要定义一个批处理的JDBCHelper,传入一个SQL语句和多个参数的Iterator
3、coalesce减少分区数
原理:可以用于多种分区数过多的情况,比如读取数据时,分区数过多,可以通过该算子减少分区数提升性能,常用于filter算子以后,可以提升一点性能,同时预防数据倾斜的作用
rdd.coalesce
4、repartition增加分区数
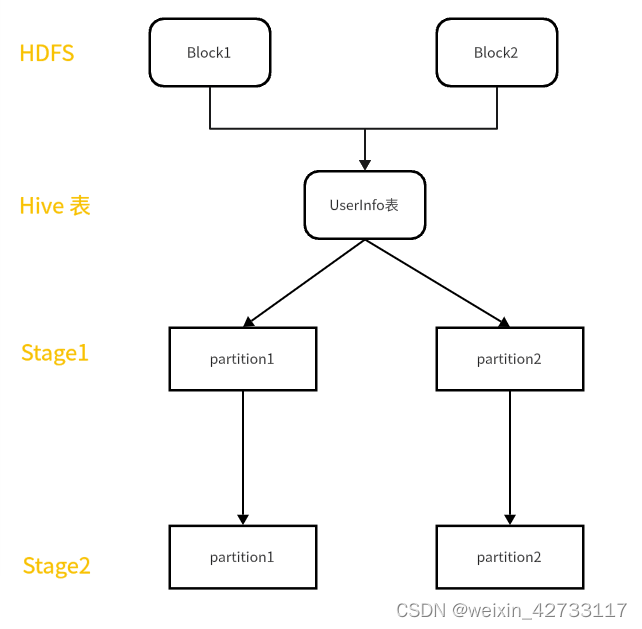
情景:我们提交任务时设置的并行度参数:sparkConf.set(“spark.default.parallelism”,“3”),是不对SparkSQL读取的数据生效的,SparkSQL默认是依据读取的数据比如Hive的HDFS文件中的Block数,来决定并行Task数的
因此不做repartition算子操作的时候是如下这样:
做repartition算子操作优化的时候是如下这样:
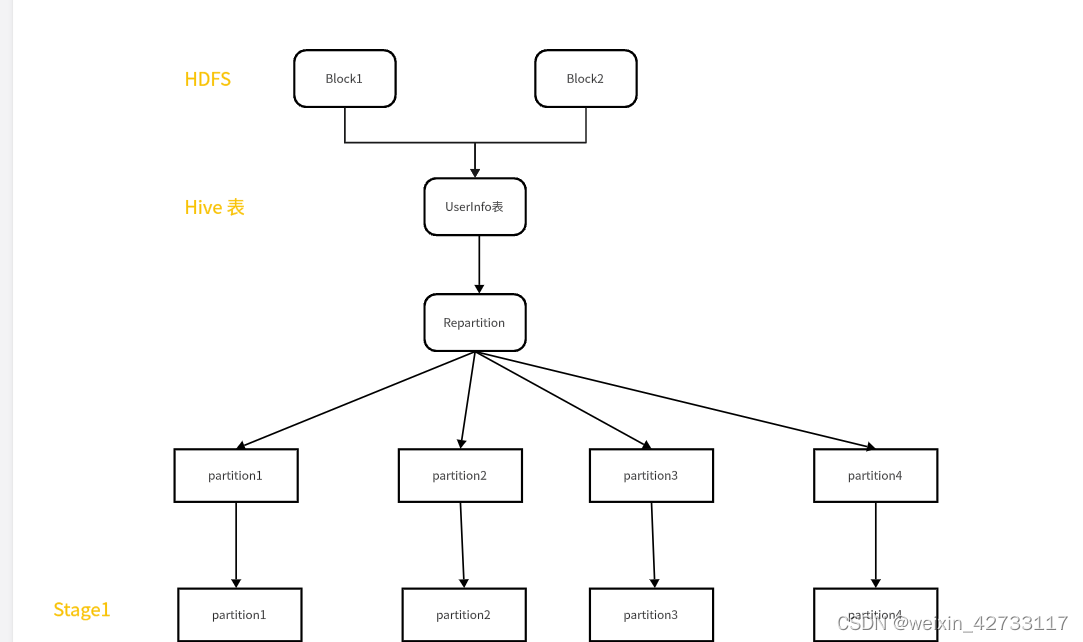
为了避免Sparksql处理复杂逻辑的时候,并行度低的情况,进行优化
5、reduceByKey预聚合
定义:记住reduceByKey在本地阶段就会执行一次Combine操作,就是执行自定义聚合函数的操作,再落盘到文件中给下一个stage的task进行拉取















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









