






一、Python基础
1. 基础知识
数组
List列表数据类型
转义符
以下两者等价。第1行代码通过在字符串的前面增加一个字符r来取消转义字符\n的换行功能;第2行代码则是将路径中的“\”改为“\”,“\”也是一个转义字符,它代表一个反斜杠字符“\”。
print(r’d:\number.xlsx’)
print(‘d:\number.xlsx’)
2. 基础函数
(1) print函数
自定义的字符串和变量混合输出
print(f'自定义字符串 {变量}')
多个print换行/不换行输出
# python的print()函数中参数end=’ ‘默认为\n,所以会自动换行,以下两种方式等价
print("abc")
print("abc",end='\n')
# 通过以下方式不换行
print("abc",end="")
print("def")
(2) numpy函数1
数组基础知识
NumPy模块的主要特点就是引入了数组的概念。因为一维数组和列表有相似之处,所以这里借助列表来讲解数组的基本概念。演示代码如下:
import numpy as np
a = [1, 2, 3, 4]
b = np.array([1, 2, 3, 4])
# 创建数组的一种方式,array就是数组的意思
print(a)
#输出变量a的值
print(b)
#输出变量b的值
print(type(a))
#输出变量a的数据类型
print(type(b))
#输出变量b的数据类型
第3行代码中的array()是NumPy模块中的函数,用于创建数组。运行结果如下:
[1, 2, 3, 4]
# 列表的展现形式
[1 2 3 4]
# 数组的展现形式
<class 'list'>
# 变量a的数据类型为列表
<class 'numpy.ndarray'>
# 变量b的数据类型为数组
列表和数组有着相似的元素索引机制,唯一的区别就是数组中的元素用空格分隔,而列表中的元素用逗号分隔。那么NumPy模块为什么不直接使用列表来组织数据,而要引入数组这一新的数据结构呢?原因有很多,这里主要讲两点。
第一,数组能很好地支持一些数学运算,而用列表来完成这些数学运算则较为麻烦。演示代码如下:
import numpy as np
a = [1, 2, 3, 4]
b = np.array([1, 2, 3, 4])
c = a * 2
d = b * 2
print(c)
print(d)
运行结果如下:
[1, 2, 3, 4, 1, 2, 3, 4]
[2 4 6 8]
可以看到,同样是做乘法运算,列表是把元素复制了一遍,而数组则是对每个元素都进行了乘法运算。
第二,数组可以存储多维数据,而列表通常只能存储一维数据。演示代码如下:
import numpy as np
e = [[1, 2], [3, 4], [5, 6]] # 大列表里嵌套小列表
f = np.array([[1, 2], [3, 4], [5, 6]]) # 创建二维数组的一种方式
print(e)
print(f)
运行结果如下:
[[1, 2], [3, 4], [5, 6]]
# 列表e的打印输出结果
[[1 2]
[3 4]
[5 6]]
# 列表f的打印输出结果
可以看到,列表e虽然包含了3个小列表,但其结构是一维的。而数组f则是3行2列的二维结构,这也是之后要学习的pandas模块的核心概念之一,因为数据处理中经常用到二维数组,即二维的表格结构。
数组的创建
一维数组
np.array()
1 import numpy as np
2 # 创建一维数组
3 a = np.array([1, 2, 3, 4])
4 # 创建二维数组
5 b = np.array([[1, 2], [3, 4], [5, 6]])
np.arange()
创建一维数组,该函数的括号里可以输入1~3个参数,会得到不同的效果。演示代码如下:
1 import numpy as np
2 # 1个参数:起点取默认值0,参数值为终点,步长取默认值1,左闭右开
3 x = np.arange(5)
4 # 2个参数:第1个参数为起点,第2个参数为终点,步长取默认值1,左闭右开
5 y = np.arange(5, 10)
6 # 3个参数:第1个参数为起点,第2个参数为终点,第3个参数为步长,左闭右开
7 z = np.arange(5, 10, 2)
8 print(x)
9 print(y)
10 print(z)
运行结果如下:
[0 1 2 3 4]
[5 6 7 8 9]
[5 7 9]
np.random()
创建随机一维数组。
例如,用np.random.randn(3)创建一个一维数组,其中包含服从正态分布(均值为0、标准差为1的分布)的3个随机数。演示代码如下:
1 import numpy as np
2 c = np.random.randn(3)
3 print(c)
运行结果如下:
1 [-0.59243327 0.53587119 0.15330862]
二维数组
np.arange()+reshape()
例如,将包含0~11这12个整数的一维数组转换成3行4列的二维数组,演示代码如下:
1 import numpy as np
2 d = np.arange(12).reshape(3, 4)
3 print(d)
运行结果如下:
1 [[ 0 1 2 3]
2 [ 4 5 6 7]
3 [ 8 9 10 11]]
np.random.randint()
1 import numpy as np
2 e = np.random.randint(0, 10, (4, 4))
3 print(e)
括号里第1个参数0为起始数,第2个参数10为终止数,第3个参数(4,4)则表示创建一个4行4列的二维数组。运行结果如下:
1 [[4 1 6 3]
2 [3 0 4 8]
3 [7 8 1 8]
4 [4 6 3 6]]
二、数学计算
开根号、平方等
math→sqrt函数
import math
x= math.sqrt(9)
pow函数
x= pow(9,0.5)
#这个函数不需要math,逗号后是上标
**表示幂运算
x= 2**3
x=pow(2,3)
#x=2*2*2
计算点积2
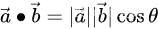
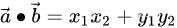
import numpy as np
""" 构建向量"""
a=np.array([-2,2])
b=np.array([2,2])
# numpy.array(object, dtype=None)
#object:创建的数组的对象,可以为单个值,列表,元胞等。
#dtype:创建数组中的数据类型。
""" 计算点积"""
ab_1=np.inner(a,b) # =a1*b1+a2*b2
# np.inner()计算两个数组的内积
""" 根据夹角余弦计算点积 """
ab_2=np.linalg.norm(a)*np.linalg.norm(b)*np.cos(np.pi/2)
# np.lingalg.norm 用法见https://blog.csdn.net/silent1cat/article/details/120811844
#np.cos()必须用弧度形式
#np.pi表示圆周率π
三、Excel数据读取基础操作
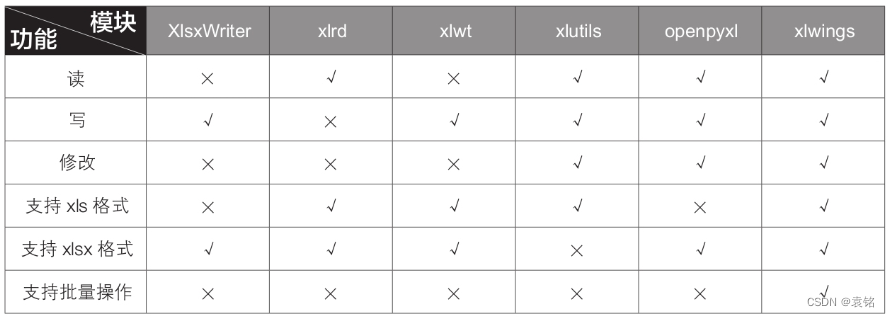
1. xlwings1
(1) 创建工作簿
import xlwings as xw
# 导入xlwings模块并简写为xw
app = xw.App(visible = True, add_book = False)
# 启动Excel程序窗口,但不新建工作簿
# App()是xlwings模块中的函数,该函数有两个常用参数:参数visible用于设置Excel程序窗口的可见性,如果为True,表示显示Excel程序窗口,如果为False,表示隐藏Excel程序窗口;参数add_book用于设置启动Excel程序窗口后是否新建工作簿,如果为True,表示新建一个工作簿,如果为False,表示不新建工作簿。
workbook = app.books.add()
# 新建一个工作簿。其中的add()为books对象的函数,用于新建工作簿
(2) 保存工作簿
workbook.save('d:\\example.xlsx')
workbook.close()
# 关闭工作簿
app.quit()
# 退出Excel程序
(3) 打开工作簿
import xlwings as xw
app = xw.App(visible = True, add_book = False)
workbook = app.books.open(r'd:\example.xlsx')
# 打开D盘根文件夹下名为“example.xlsx”的工作簿
# 需要注意的是,指定的工作簿必须真实存在,并且不能处于已打开的状态
(4) 操控工作表和单元格
xlwings模块还能操控工作表和单元格。
import xlwings as xw
app = xw.App(visible = False)
workbook = app.books.add()
worksheet = workbook.sheets.add('产品统计表')
# 新增一个名为“产品统计表”的工作表
worksheet = workbook.sheets['产品统计表]
# 选中工作表“产品统计表”
worksheet.range('A1').value = '编号'
# 在单元格A1中输入内容
workbook.save(r'd:\北京.xlsx')
workbook.close()
app.quit()
运行后会看到在D盘的根文件夹下新建了一个名为“北京.xlsx”的工作簿,该工作簿中有一个名为“产品统计表”的工作表,该工作表的单元格A1中输入了内容“编号”。
2. xlrd
(1)引入Excel库的xlrd
xlrd是Python处理Excel表格数据的一个模块,他可以对Excel数据进行读取,包括:
1、读取Excel的行数、列数、行的值、列的值、
2、读取单元格的值、数据类型
3、增加、删除、修改表格数据
4、导出导入工作表等
xlrd的安装比较简单,只要打开cmd命令框,然后输入:pip install xlrd即可,或者打开编译器jupyter book,然后在代码栏里输入:pip install xlrd也可以安装,然后在代码栏里输入如下代码查看是否安装成功(能看到版本号即表示安装成功)
import xlrd
(2)打开excel表格[xlrd.open_workbook() ]
myworkbook = xlrd.open_workbook(r'C:\Users\win7\Desktop\test.xlsx')
# myworkbook代表打开的文件,可以任意命名
# xlrd.open_workbook() 括号内填写文件路径
# 如果路径或者文件名有中文给前面加一个r表示原生字符'
print(f"workbook is {myworkbook}")
# 结果:<xlrd.book.Book object at .....>
显示结果为
workbook is <xlrd.book.Book object at 0x0000000007D33FD0>
(3)获取sheet信息
个数[.nsheets]
print(f"一共有{myworkbook.nsheets}个sheets")
# nsheets:获取工作簿中sheet的数量
显示的结果为
一共有3个sheets
名称[.sheet_names() ]
sheet_names = myworkbook.sheet_names()
# 定义的sheet = myworkbook.sheet_names()
print(f"sheet包含{sheet_names}")
# 结果:['表1', '表2'...]
显示的结果为
sheet包含['00', '01', '02']
[<xlrd.sheet.Sheet object at 0x0000000007D33160>, <xlrd.sheet.Sheet object at 0x0000000007D34EF0>, <xlrd.sheet.Sheet object at 0x0000000007D34F98>]
对象[.sheets()]
sheets_object = myworkbook.sheets()
# 获取所有的sheet对象,以列表形式显示
# 定义的sheet对象=文件名.sheets()
print(f"所有的sheet对象为{sheets_object}")
# 结果:[<xlrd.sheet.Sheet object at ……>,……]
显示结果为
所有的sheet对象为[<xlrd.sheet.Sheet object at 0x0000000007D33160>, <xlrd.sheet.Sheet object at 0x0000000007D34EF0>, <xlrd.sheet.Sheet object at 0x0000000007D34F98>]
获取某个sheet对象
通过索引获取[.sheet()[] ]
sheets_object = myworkbook.sheets()[0]
#sheet对象自定义命名=文件名.sheet()[第几个sheet(0是第一个)]
#没有中括号就是输出所有对象
#索引从0开始,对应sheet1、sheet2、sheet3……
print(f"第一个sheet对象为{sheets_object}")
显示结果为
第一个sheet对象为<xlrd.sheet.Sheet object at 0x0000000007D33160>
通过索引获取[.sheet_by_index() ]
sheet1_object = myworkbook.sheet_by_index(1)
#sheet对象=文件名.sheet_by_index(第几个sheet,0是第一个)]
#没有中括号就是输出所有对象
print(f"通过index获取第2个sheet对象是{sheet1_object}")
显示结果为
通过index获取第2个sheet对象是<xlrd.sheet.Sheet object at 0x0000000007D34EF0>
通过name获取[.sheet_by_name(sheet_name=" ")]
sheet1_object = myworkbook.sheet_by_name(sheet_name="00")
#sheet对象=文件名.sheet_by_name(sheetname="sheet名")]
print(f"通过name获取第一个sheet对象是{sheet1_object}")
显示结果为
通过name获取第一个sheet对象是<xlrd.sheet.Sheet object at 0x0000000007D33160>
判断是否导入成功
通过index判断[.sheet_loaded((sheet_name_or_index= )]
sheet1_is_load = myworkbook.sheet_loaded(sheet_name_or_index=0)
#文件名.sheet_loaded(sheet_name_or_index=... )
print(sheet1_is_load)
#返回值为布尔类型,True 表示已导入,False 表示未导入
通过名称判断[.sheet.loaded((sheet_name_or_index= )]
sheet1_is_load = myworkbook.sheet_loaded(sheet_name_or_index="00")
print(sheet1_is_load) # 结果:True
(4) 对sheet对象中的行、列执行操作
| A | B | |
|---|---|---|
| 1 | 1 | 5 |
| 2 | 2 | 4 |
| 3 | 3 | 3 |
| 4 | 4 | 2 |
| 5 | 5 | 1 |
获取有效行\列数[.nrows、.ncols]
nrows = sheet1_object.nrows
ncols = sheet1_object.ncols
print(f"sheet1中的有效行数为{nrows}")
print(f"sheet1中的有效列数为{ncols}")
print(f"sheet1中的数据范围为{nrows}*{ncols}")
显示结果为
sheet1中的有效行数为5
sheet1中的有效列数为2
sheet1中的数据范围为5*2
获取某一行/列数据
获取某一行[类型:数值,类型:数值],[ .row() ]
print(sheet1_object.row(0))
显示结果为
[number:1.0, number:5.0]
获取某一列[类型:数值,类型:数值],[ .col() ]
print(sheet1_object.col(0))
显示结果为
[number:1.0, number:2.0, number:3.0, number:4.0, number:5.0]
获取第1行[类型:‘数值’,类型:‘数值’],[ row_slice() ]
print(sheet1_object.row_slice(0))
获取第3行数据,[ .row_values(rowx= ) ]
all_row_values = sheet1_object.row_values(rowx=2)
print(f"sheet1中第3行的数据为{all_row_values}")
显示结果为
sheet1中第3行的数据为[3.0, 3.0]
获取第2列数据,[.col_values(colx= )]
all_col_values = sheet1_object.col_values(colx=1)
print( all_col_values)
显示结果为
[5.0, 4.0, 3.0, 2.0, 1.0]
获取第2行、第2列至第4列数据,[.row_values(rowx= , start_colx= , end_colx= )]
row_values = sheet1_object.row_values(rowx=2, start_colx=1, end_colx=3)
print(row_values)
显示结果为
[3.0]
获取第3行单元对象
row_object = sheet1_object.row(rowx=2)
print(f"sheet1中第3行的单元对象为{row_object}")
row_slice = sheet1_object.row_slice(rowx=2)
print(f"sheet1中第3行的单元为{row_slice}")
获取第3行单元类型[.row_types(rowx= )]
row_types = sheet1_object.row_types(rowx=2)
print(f"sheet1中第3行的单元类型为{row_types}")
获取第3行的长度[.row_len(rowx= )]
row_len = sheet1_object.row_len(rowx=2)
print(f"sheet1中第3行的长度为{row_len}")
获取第2列的单元
col_slice = sheet1_object.col_slice(colx=1)
print(f"sheet1中第2列的单元为{col_slice}")
获取单元格信息
获取第2列单元类型[.col_types(colx=1)]
col_types = sheet1_object.col_types(colx=1)
print(f"sheet1中第2列的单元类型为{col_types}") # 结果:[1, 1, 1, 1, 1]
#单元类型:empty为0,string为1,number为2,date为3,boolean为4,error为5
获取第1行第2列单元对象[.cell(rowx=,colx= )]
cell_info = sheet1_object.cell(rowx=1, colx=1)
print(cell_info) # 结果: text:'m'
print(type(cell_info)) # 结果:<class 'xlrd.sheet.Cell'>
获取第1行第1列单元值[.cell_value(rowx=,colx=)]
cell_value = sheet1_object.cell_value(rowx=0, colx=0)
print(f"sheet1中第rowx=1行,第colx=1列的单元值为{cell_value}") # 结果: m
获取第1行第1列单元类型值[.cell_type(rowx= ,colx= )]
cell_type = sheet1_object.cell_type(rowx=0, colx=0)
print(f"sheet1中第rowx=1行,第colx=1列的单元类型值为{cell_type}。单元类型:empty为0,string为1,number为2,date为3,boolean为4,error为5")
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









