







前言
在当今大数据时代,了解一个人的方式已经发生了变化。我们通常会通过浏览他们的微博、朋友圈以及听取朋友的看法来获取信息。尤其是对于我们喜欢的明星,我们会经常浏览他们的微博,以了解他们的最新动态。随着数据成为不可或缺的一部分,Python已经成为获取数据的首选工具。在这个博客中,我将分享如何通过Python优化数据收集的过程,使我们能够更深入地了解我们关注的人。本文带大家使用python加入代理池爬取微博爱豆信息存入excel。
环境准备
装好我们需要的模块,xlrd、xlutils都是用于excel操作
pip install xlrd
pip install xlutils
程序
使用代理解决反反爬虫问题,免费代理ip自行百度
# -*- coding: utf-8 -*-
import urllib.request
import json
import xlrd
from xlutils.copy import copy
# 设置IP代理池子
proxy_addr = ["110.52.235.100:9999", "117.95.200.86:9999", "113.128.10.121:9999", "49.86.181.235:9999",
"121.225.52.143:9999", "111.177.186.27:9999", "175.155.77.189:9999", "110.52.235.120:9999",
"113.128.24.189:9999", "163.204.242.51:9999"]
def read_url(num):
data = xlrd.open_workbook('readtest.xls') # 打开Excel文件读取数据
table = data.sheet_by_name(u'5000条抖音用户数据') # 通过名称获取工作表
url = str(table.cell(num, 1).value)
if url != '':
id = url[-10:]
return id # 获取单元格
else:
return 0
# 定义页面打开函数
def use_proxy(url, proxy_addr):
req = urllib.request.Request(url)
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") # 浏览器标识符
proxy = urllib.request.ProxyHandler({'http': proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req).read().decode('utf-8', 'ignore')
return data
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id, i):
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + id
data = use_proxy(url, proxy_addr[i])
print(proxy_addr[i])
content = json.loads(data).get('data')
try: # 试错有没有不存在的url
profile_image_url = content.get('userInfo').get('profile_image_url') # 主页地址
description = content.get('userInfo').get('description') # 微博说明
profile_url = content.get('userInfo').get('profile_url') # 头像地址
verified = content.get('userInfo').get('verified') # 认证状态
guanzhu = content.get('userInfo').get('follow_count') # 关注
name = content.get('userInfo').get('screen_name') # 名字
fensi = content.get('userInfo').get('followers_count') # 粉丝
gender = content.get('userInfo').get('gender') # 性别
urank = content.get('userInfo').get('urank') # 微博等级
alldata = name + '+' + profile_url + '+' + profile_image_url + '+' + str(
verified) + '+' + description + '+' + str(guanzhu) + '+' + str(fensi) + '+' + gender + '+' + str(urank)
list = alldata.split('+')
print(list)
book = xlrd.open_workbook("savetest.xls") # 打开文件
nr = book.sheet_by_index(0).nrows # 打开工作表的行数
book_copy = copy(book) # 复制原来的文件
sheet = book_copy.get_sheet(0) # 打开复制的工作表
u = list
for i in range(u.__len__()):
sheet.write(nr, i, u[i]) # 在nr行往后写i个数据,数据在u[i]中
book_copy.save("savetest.xls")
except AttributeError:
book = xlrd.open_workbook("savetest.xls") # 打开文件
nr = book.sheet_by_index(0).nrows # 打开工作表的行数
book_copy = copy(book) # 复制原来的文件
sheet = book_copy.get_sheet(0) # 打开复制的工作表
u = [' ']
for i in range(u.__len__()):
sheet.write(nr, i, u[i]) # 在nr行往后写i个数据,数据在u[i]中
book_copy.save("savetest.xls")
if __name__ == "__main__":
for i in range(0, 50000):
print(i)
url = read_url(i)
i = i // 100 # 输出100个换个ip
if url != 0:
get_userInfo(url, i)
else:
book = xlrd.open_workbook("savetest.xls") # 打开文件
nr = book.sheet_by_index(0).nrows # 打开工作表的行数
book_copy = copy(book) # 复制原来的文件
sheet = book_copy.get_sheet(0) # 打开复制的工作表
u = [' ']
for i in range(u.__len__()):
sheet.write(nr, i, u[i]) # 在nr行往后写i个数据,数据在u[i]中
book_copy.save("savetest.xls")
readtest.xls文件内容
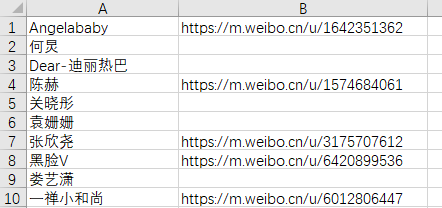
结果
爬取保存的结果savetest.xls

有任何疑问和想法,欢迎在评论区与我交流。















 4106
4106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









