




新版项目已经完成:可视化微博数据采集
新版可视化完整项目如下:
csdn : https://blog.csdn.net/m0_72947390/article/details/145816422
github : https://github.com/zhouyi207/WeiBoCrawler
旧版详细数据获取流程如下
参加新闻比赛,需要获取大众对某一方面的态度信息,因此选择微博作为信息收集的一部分
一、旧版代码
每一步的分别实现在下面第二节和第三节的流程中,这里为了方便起见,将其合并成一个类,直接运行 main.py 实现一步爬取
爬取到的文件在 WBData 目录下的 demo.csv, demo_comments_one.csv, demo_comments_two.csv 文件中,文件夹里面的是缓存文件,方便中断时可以继续上次没爬取完毕的任务爬取
要运行必须在当前目录有五个文件,main.py,parse_html.py,get_main_body.py,get_comments_level_one.py,get_comments_level_two.py
创建文件 main.py 输入以下代码
# main.py
import os
import pandas as pd
from rich.progress import track
from get_main_body import get_all_main_body
from get_comments_level_one import get_all_level_one
from get_comments_level_two import get_all_level_two
import logging
logging.basicConfig(level=logging.INFO)
class WBParser:
def __init__(self, cookie):
self.cookie = cookie
os.makedirs("./WBData", exist_ok=True)
os.makedirs("./WBData/Comments_level_1", exist_ok=True)
os.makedirs("./WBData/Comments_level_2", exist_ok=True)
self.main_body_filepath = "./WBData/demo.csv"
self.comments_level_1_filename = "./WBData/demo_comments_one.csv"
self.comments_level_2_filename = "./WBData/demo_comments_two.csv"
self.comments_level_1_dirpath = "./WBData/Comments_level_1/"
self.comments_level_2_dirpath = "./WBData/Comments_level_2/"
def get_main_body(self, q, kind):
data = get_all_main_body(q, kind, self.cookie)
data = data.reset_index(drop=True).astype(str).drop_duplicates()
data.to_csv(self.main_body_filepath, encoding="utf_8_sig")
def get_comments_level_one(self):
data_list = []
main_body = pd.read_csv(self.main_body_filepath, index_col=0)
logging.info(f"主体内容一共有{main_body.shape[0]:5d}个,现在开始解析...")
for ix in track(range(main_body.shape[0]), description=f"解析中..."):
uid = main_body.iloc[ix]["uid"]
mid = main_body.iloc[ix]["mid"]
final_file_path = f"{self.comments_level_1_dirpath}{uid}_{mid}.csv"
if os.path.exists(final_file_path):
length = pd.read_csv(final_file_path).shape[0]
if length > 0:
continue
data = get_all_level_one(uid=uid, mid=mid, cookie=self.cookie)
data.drop_duplicates(inplace=True)
data.to_csv(final_file_path, encoding="utf_8_sig")
data_list.append(data)
logging.info(f"主体内容一共有{main_body.shape[0]:5d}个,已经解析完毕!")
data = pd.concat(data_list).reset_index(drop=True).astype(str).drop_duplicates()
data.to_csv(self.comments_level_1_filename)
def get_comments_level_two(self):
data_list = []
comments_level_1_data = pd.read_csv(self.comments_level_1_filename, index_col=0)
logging.info(
f"一级评论一共有{comments_level_1_data.shape[0]:5d}个,现在开始解析..."
)
for ix in track(
range(comments_level_1_data.shape[0]), description=f"解析中..."
):
main_body_uid = comments_level_1_data.iloc[ix]["main_body_uid"]
mid = comments_level_1_data.iloc[ix]["mid"]
final_file_path = (
f"{self.comments_level_2_dirpath}{main_body_uid}_{mid}.csv"
)
if os.path.exists(final_file_path):
length = pd.read_csv(final_file_path).shape[0]
if length > 0:
continue
data = get_all_level_two(uid=main_body_uid, mid=mid, cookie=self.cookie)
data.drop_duplicates(inplace=True)
data.to_csv(final_file_path, encoding="utf_8_sig")
data_list.append(data)
logging.info(
f"一级评论一共有{comments_level_1_data.shape[0]:5d}个,已经解析完毕!"
)
data = pd.concat(data_list).reset_index(drop=True).astype(str).drop_duplicates()
data.to_csv(self.comments_level_2_filename)
if __name__ == "__main__":
q = "#姜萍中考621分却上中专的原因#" # 话题
kind = "综合" # 综合,实时,热门,高级
cookie = "" # 设置你的cookie
wbparser = WBParser(cookie)
wbparser.get_main_body(q, kind) # 获取主体内容
wbparser.get_comments_level_one() # 获取一级评论
wbparser.get_comments_level_two() # 获取二级评论
创建文件 parse_html.py 输入以下代码
# parse_html.py
from parsel import Selector
import pandas as pd
import re
import time
def get_html_text(file_path):
with open(file_path, mode="r", encoding="utf-8") as f:
html_text = f.read()
return html_text
def parse_html(html_text):
lst = []
select = Selector(html_text)
select.xpath("//i").drop()
# 获取总页数
total_page = select.xpath(
'//ul[@node-type="feed_list_page_morelist"]/li/a/text()'
).getall()[-1]
total_page = int(re.findall(r"[\d]+", total_page)[0])
# 获取主体信息
div_list = select.xpath(
'//*[@id="pl_feedlist_index"]//div[@action-type="feed_list_item"]'
).getall()
for div_string in div_list:
select = Selector(div_string)
mid = select.xpath("//div[@mid]/@mid").get()
personal_name = select.xpath("//a[@nick-name]/@nick-name").get()
personal_href = select.xpath("//a[@nick-name]/@href").get()
publish_time = select.xpath('//div[@class="from"]/a[1]/text()').get()
content_from = select.xpath('//div[@class="from"]/a[2]/text()').get()
content_show = select.xpath('string(//p[@node-type="feed_list_content"])').get()
content_all = select.xpath(
'string(//p[@node-type="feed_list_content_full"])'
).get()
retweet_num = select.xpath('string(//div[@class="card-act"]/ul[1]/li[1])').get()
comment_num = select.xpath('string(//div[@class="card-act"]/ul[1]/li[2])').get()
star_num = select.xpath('string(//div[@class="card-act"]/ul[1]/li[3])').get()
item = [
mid,
personal_name,
personal_href,
publish_time,
content_from,
content_show,
content_all,
retweet_num,
comment_num,
star_num,
]
lst.append(item)
columns = [
"mid",
"个人昵称",
"个人主页",
"发布时间",
"内容来自",
"展示内容",
"全部内容",
"转发数量",
"评论数量",
"点赞数量",
]
data = pd.DataFrame(lst, columns=columns)
return data, total_page
def process_time(publish_time):
now = int(time.time())
publish_time = publish_time.strip()
if "人数" in publish_time:
publish_time = " ".join(publish_time.split()[:-1])
publish_time = publish_time.replace("今天 ", "今天")
if "分钟前" in publish_time:
minutes = re.findall(r"([\d].*)分钟前", publish_time)[0]
now = now - int(minutes) * 60
timeArray = time.localtime(now)
publish_time = time.strftime("%m月%d日 %H:%M", timeArray)
if "今天" in publish_time:
timeArray = time.localtime(now)
today = time.strftime("%m月%d日 ", timeArray)
publish_time = publish_time.replace("今天", today)
return publish_time
def process_dataframe(data):
data.insert(
1, "uid", data["个人主页"].map(lambda href: re.findall(r"com/(.*)\?", href)[0])
)
data["个人主页"] = "https:" + data["个人主页"]
data["个人主页"] = data["个人主页"].map(lambda x: re.findall(r"(.*)\?", x)[0])
data["发布时间"] = data["发布时间"].map(process_time)
data.iloc[:, 6:] = data.iloc[:, 6:].applymap(
lambda x: x.replace("\n", "").replace(" ", "") if x else None
) # 清楚掉 \n 和 空格
data["全部内容"] = data["全部内容"].map(
lambda x: x[:-2] if x else None
) # 清除掉收起
data.iloc[:, -3:] = data.iloc[:, -3:].applymap(
lambda x: 0 if x in ["转发", "评论", "赞"] else x
)
return data
def get_dataframe_from_html_text(html_text):
data, total_page = parse_html(html_text)
process_dataframe(data)
return data, total_page
if __name__ == "__main__":
html_text = get_html_text("./resp.html")
data, total_page = get_dataframe_from_html_text(html_text)
print(data, total_page)
创建文件 get_main_body.py 输入以下代码
# get_main_body.py
import requests
from urllib import parse
from parse_html import get_dataframe_from_html_text
import logging
from rich.progress import track
import pandas as pd
logging.basicConfig(level=logging.INFO)
def get_the_main_body_response(q, kind, p, cookie, timescope=None):
"""
q表示的是话题;
kind表示的是类别:综合,实时,热门,高级;
p表示的页码;
timescope表示高级的时间,不用高级无需带入 example:"2024-03-01-0:2024-03-27-16"
""" kind_params_url = {
"综合": [
{"q": q, "Refer": "weibo_weibo", "page": p},
"https://s.weibo.com/weibo",
],
"实时": [
{
"q": q,
"rd": "realtime",
"tw": "realtime",
"Refer": "realtime_realtime",
"page": p,
},
"https://s.weibo.com/realtime",
],
"热门": [
{
"q": q,
"xsort": "hot",
"suball": "1",
"tw": "hotweibo",
"Refer": "realtime_hot",
"page": p,
},
"https://s.weibo.com/hot",
],
# 高级中的xsort删除后就是普通的排序
"高级": [
{
"q": q,
"xsort": "hot",
"suball": "1",
"timescope": f"custom:{timescope}",
"Refer": "g",
"page": p,
},
"https://s.weibo.com/weibo",
],
}
params, url = kind_params_url[kind]
headers = {
"authority": "s.weibo.com",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"referer": url
+ "?"
+ parse.urlencode(params).replace(
f'&page={params["page"]}', f'&page={int(params["page"]) - 1}'
),
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"cookie": cookie,
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69",
}
response = requests.get(url, params=params, headers=headers)
return response
def get_all_main_body(q, kind, cookie, timescope=None):
# 初始化数据
data_list = []
resp = get_the_main_body_response(q, kind, 1, cookie, timescope)
html_text = resp.text
try:
data, total_page = get_dataframe_from_html_text(html_text)
data_list.append(data)
logging.info(
f"话题:{q},类型:{kind},解析成功,一共有{total_page:2d}页,准备开始解析..."
)
for current_page in track(range(2, total_page + 1), description=f"解析中..."):
html_text = get_the_main_body_response(
q, kind, current_page, cookie, timescope
).text
data, total_page = get_dataframe_from_html_text(html_text)
data_list.append(data)
data = pd.concat(data_list).reset_index(drop=True)
logging.info(f"话题:{q},类型:{kind},一共有{total_page:2d}页,已经解析完毕!")
return data
except Exception as e:
logging.warning("解析页面失败,请检查你的cookie是否正确!")
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
q = "#姜萍中考621分却上中专的原因#" # 话题
kind = "热门" # 综合,实时,热门,高级
cookie = "" # 设置你的cookie
data = get_all_main_body(q, kind, cookie)
data.to_csv("demo.csv", encoding="utf_8_sig")
创建文件 get_comments_level_one.py 输入以下代码
# get_comments_level_one.py
import requests
import pandas as pd
import json
from dateutil import parser
def get_buildComments_level_one_response(uid, mid, cookie, the_first=True, max_id=None):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
params = {
"is_reload": "1",
"id": f"{mid}",
"is_show_bulletin": "2",
"is_mix": "0",
"count": "20",
"uid": f"{uid}",
"fetch_level": "0",
"locale": "zh-CN",
}
if not the_first:
params["flow"] = 0
params["max_id"] = max_id
response = requests.get(
"https://weibo.com/ajax/statuses/buildComments", params=params, headers=headers
)
return response
def get_rum_level_one_response(buildComments_url, cookie):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
entry = {"name": buildComments_url}
files = {
"entry": (None, json.dumps(entry)),
"request_id": (None, ""),
}
# 这个resp返回值无实际意义,返回值一直是{ok: 1}
requests.post("https://weibo.com/ajax/log/rum", headers=headers, files=files)
def get_level_one_response(uid, mid, cookie, the_first=True, max_id=None):
buildComments_resp = get_buildComments_level_one_response(
uid, mid, cookie, the_first, max_id
)
buildComments_url = buildComments_resp.url
get_rum_level_one_response(buildComments_url, cookie)
data = pd.DataFrame(buildComments_resp.json()["data"])
max_id = buildComments_resp.json()["max_id"]
return max_id, data
def process_time(publish_time):
publish_time = parser.parse(publish_time)
publish_time = publish_time.strftime("%y年%m月%d日 %H:%M")
return publish_time
def process_data(data):
data_user = pd.json_normalize(data["user"])
data_user_col_map = {
"id": "uid",
"screen_name": "用户昵称",
"profile_url": "用户主页",
"description": "用户描述",
"location": "用户地理位置",
"gender": "用户性别",
"followers_count": "用户粉丝数量",
"friends_count": "用户关注数量",
"statuses_count": "用户全部微博",
"status_total_counter.comment_cnt": "用户累计评论",
"status_total_counter.repost_cnt": "用户累计转发",
"status_total_counter.like_cnt": "用户累计获赞",
"status_total_counter.total_cnt": "用户转评赞",
"verified_reason": "用户认证信息",
}
data_user_col = [col for col in data_user if col in data_user_col_map.keys()]
data_user = data_user[data_user_col]
data_user = data_user.rename(columns=data_user_col_map)
data_main_col_map = {
"created_at": "发布时间",
"text": "处理内容",
"source": "评论地点",
"mid": "mid",
"total_number": "回复数量",
"like_counts": "点赞数量",
"text_raw": "原生内容",
}
data_main_col = [col for col in data if col in data_main_col_map.keys()]
data_main = data[data_main_col]
data_main = data_main.rename(columns=data_main_col_map)
data = pd.concat([data_main, data_user], axis=1)
data["发布时间"] = data["发布时间"].map(process_time)
data["用户主页"] = "https://weibo.com" + data["用户主页"]
return data
def get_all_level_one(uid, mid, cookie, max_times=15):
# 初始化
max_id = ""
data_lst = []
max_times = max_times # 最多只有15页
try:
for current_times in range(1, max_times):
if current_times == 0:
max_id, data = get_level_one_response(uid=uid, mid=mid, cookie=cookie)
else:
max_id, data = get_level_one_response(
uid=uid, mid=mid, cookie=cookie, the_first=False, max_id=max_id
)
if data.shape[0] != 0:
data_lst.append(data)
if max_id == 0:
break
if data_lst:
data = pd.concat(data_lst).reset_index(drop=True)
data = process_data(data)
data.insert(0, "main_body_uid", uid)
data.insert(0, "main_body_mid", mid)
return data
else:
return pd.DataFrame()
except Exception as e:
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
# 这里的uid,mid是主体内容的uid和mid
uid = "1006550592"
mid = "5046560175424086"
cookie = "" # 设置你的cookie
data = get_all_level_one(uid, mid, cookie)
data.to_csv("demo_comments.csv", encoding="utf_8_sig")
创建文件 get_comments_level_two.py 输入以下代码
# get_comments_level_two.py
import requests
import pandas as pd
import json
from dateutil import parser
def get_buildComments_level_two_response(uid, mid, cookie, the_first=True, max_id=None):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
params = {
"is_reload": "1",
"id": f"{mid}",
"is_show_bulletin": "2",
"is_mix": "1",
"fetch_level": "1",
"max_id": "0",
"count": "20",
"uid": f"{uid}",
"locale": "zh-CN",
}
if not the_first:
params["flow"] = 0
params["max_id"] = max_id
response = requests.get(
"https://weibo.com/ajax/statuses/buildComments", params=params, headers=headers
)
return response
def get_rum_level_two_response(buildComments_url, cookie):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
entry = {"name": buildComments_url}
files = {
"entry": (None, json.dumps(entry)),
"request_id": (None, ""),
}
# 这个resp返回值无实际意义,返回值一直是{ok: 1}
requests.post("https://weibo.com/ajax/log/rum", headers=headers, files=files)
def get_level_two_response(uid, mid, cookie, the_first=True, max_id=None):
buildComments_resp = get_buildComments_level_two_response(
uid, mid, cookie, the_first, max_id
)
buildComments_url = buildComments_resp.url
get_rum_level_two_response(buildComments_url, cookie)
data = pd.DataFrame(buildComments_resp.json()["data"])
max_id = buildComments_resp.json()["max_id"]
return max_id, data
def process_time(publish_time):
publish_time = parser.parse(publish_time)
publish_time = publish_time.strftime("%y年%m月%d日 %H:%M")
return publish_time
def process_data(data):
data_user = pd.json_normalize(data["user"])
data_user_col_map = {
"id": "uid",
"screen_name": "用户昵称",
"profile_url": "用户主页",
"description": "用户描述",
"location": "用户地理位置",
"gender": "用户性别",
"followers_count": "用户粉丝数量",
"friends_count": "用户关注数量",
"statuses_count": "用户全部微博",
"status_total_counter.comment_cnt": "用户累计评论",
"status_total_counter.repost_cnt": "用户累计转发",
"status_total_counter.like_cnt": "用户累计获赞",
"status_total_counter.total_cnt": "用户转评赞",
"verified_reason": "用户认证信息",
}
data_user_col = [col for col in data_user if col in data_user_col_map.keys()]
data_user = data_user[data_user_col]
data_user = data_user.rename(columns=data_user_col_map)
data_main_col_map = {
"created_at": "发布时间",
"text": "处理内容",
"source": "评论地点",
"mid": "mid",
"total_number": "回复数量",
"like_counts": "点赞数量",
"text_raw": "原生内容",
}
data_main_col = [col for col in data if col in data_main_col_map.keys()]
data_main = data[data_main_col]
data_main = data_main.rename(columns=data_main_col_map)
data = pd.concat([data_main, data_user], axis=1)
data["发布时间"] = data["发布时间"].map(process_time)
data["用户主页"] = "https://weibo.com" + data["用户主页"]
return data
def get_all_level_two(uid, mid, cookie, max_times=15):
# 初始化
max_id = ""
data_lst = []
max_times = max_times # 最多只有15页
try:
for current_times in range(1, max_times):
if current_times == 0:
max_id, data = get_level_two_response(uid=uid, mid=mid, cookie=cookie)
else:
max_id, data = get_level_two_response(
uid=uid, mid=mid, cookie=cookie, the_first=False, max_id=max_id
)
if data.shape[0] != 0:
data_lst.append(data)
if max_id == 0:
break
if data_lst:
data = pd.concat(data_lst).reset_index(drop=True)
data = process_data(data)
data.insert(0, "main_body_uid", uid)
data.insert(0, "comments_level_1_mid", mid)
return data
else:
return pd.DataFrame()
except Exception as e:
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
# 这里 main_body_uid 是主体内容中的uid
# 这里 mid 是一级评论中的mid
main_body_uid = "2656274875"
mid = "5046022789400609"
cookie = "" # 设置你的cookie
data = get_all_level_two(main_body_uid, mid, cookie)
data.to_csv("demo_comments_two.csv", encoding="utf_8_sig")
二、微博主体内容获取流程
首先打开微博,随便进入一个话题,这里以话题 #姜萍中考621分却上中专的原因# 为例子
通过 F12 打开开发者模式,通过检查开发者模式中的 html 页面可以发现需要的信息基本都包含在下面的 div tag中
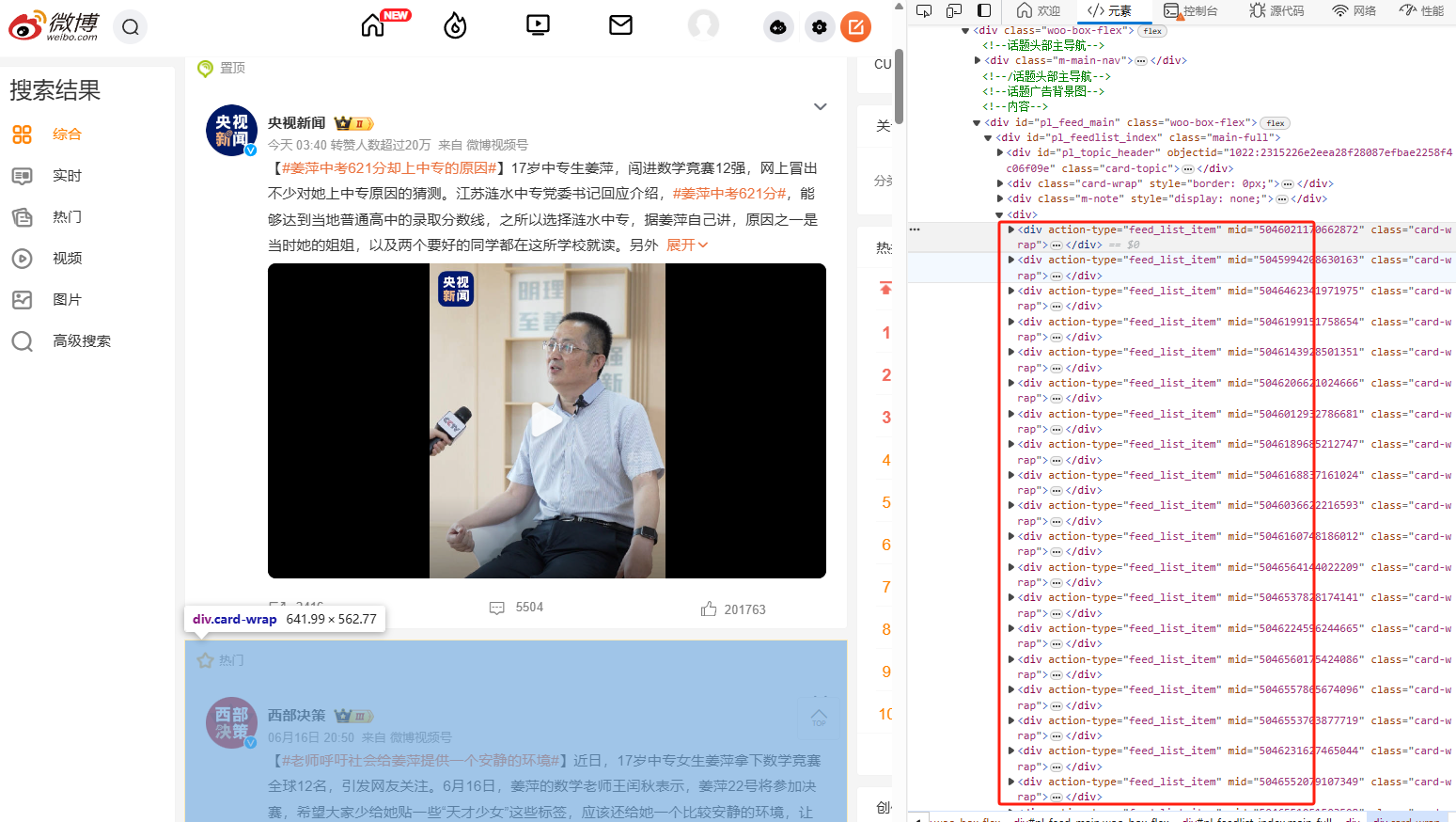
继续通过网络这一模块进行解析,发现信息基本都存储在 weibo?q 开头的请求之中
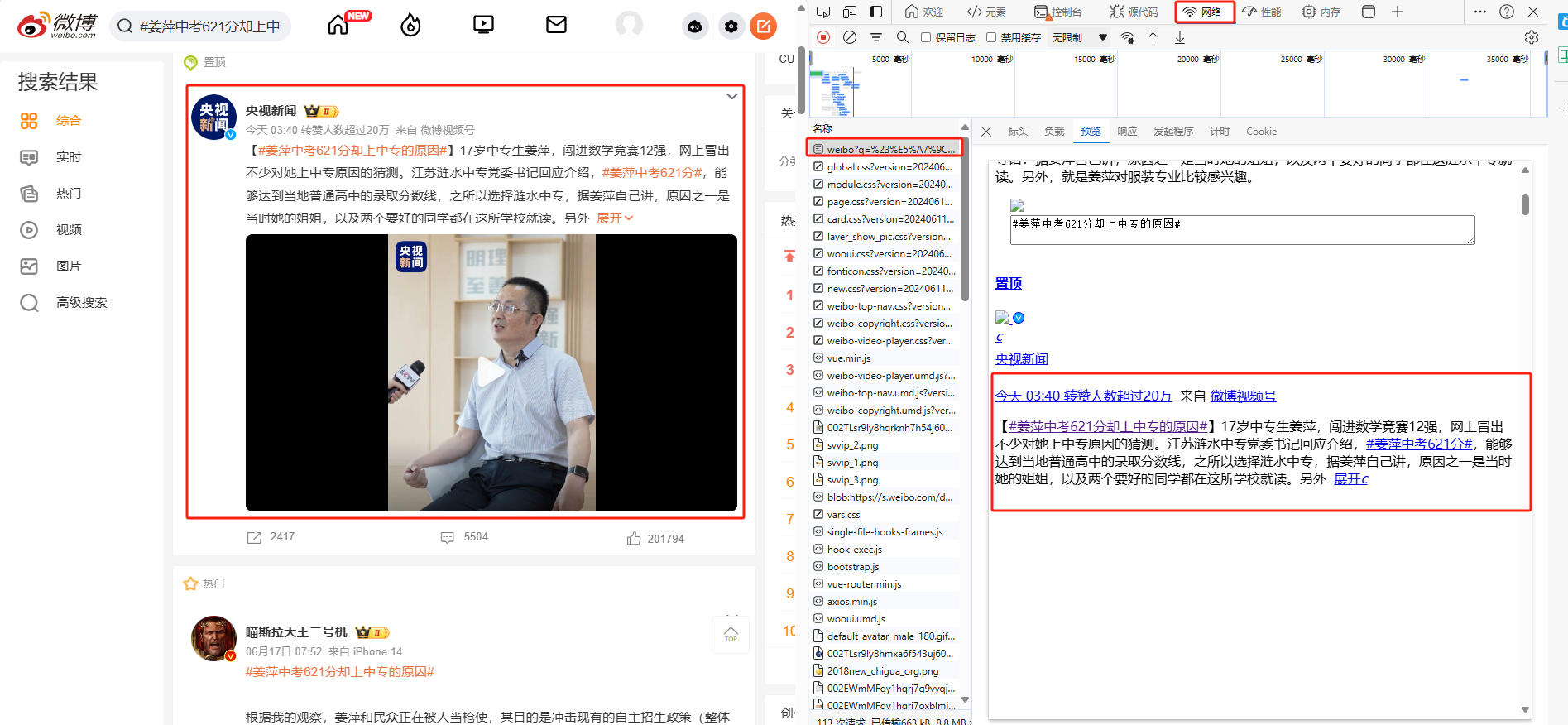
可以看出响应内容为 html 格式,同时注意这里内容有两部分,经过简单分析后可以发现:前者是展开前的内容,后者是展开后的内容;复制该请求的响应内容,然后进行解析。
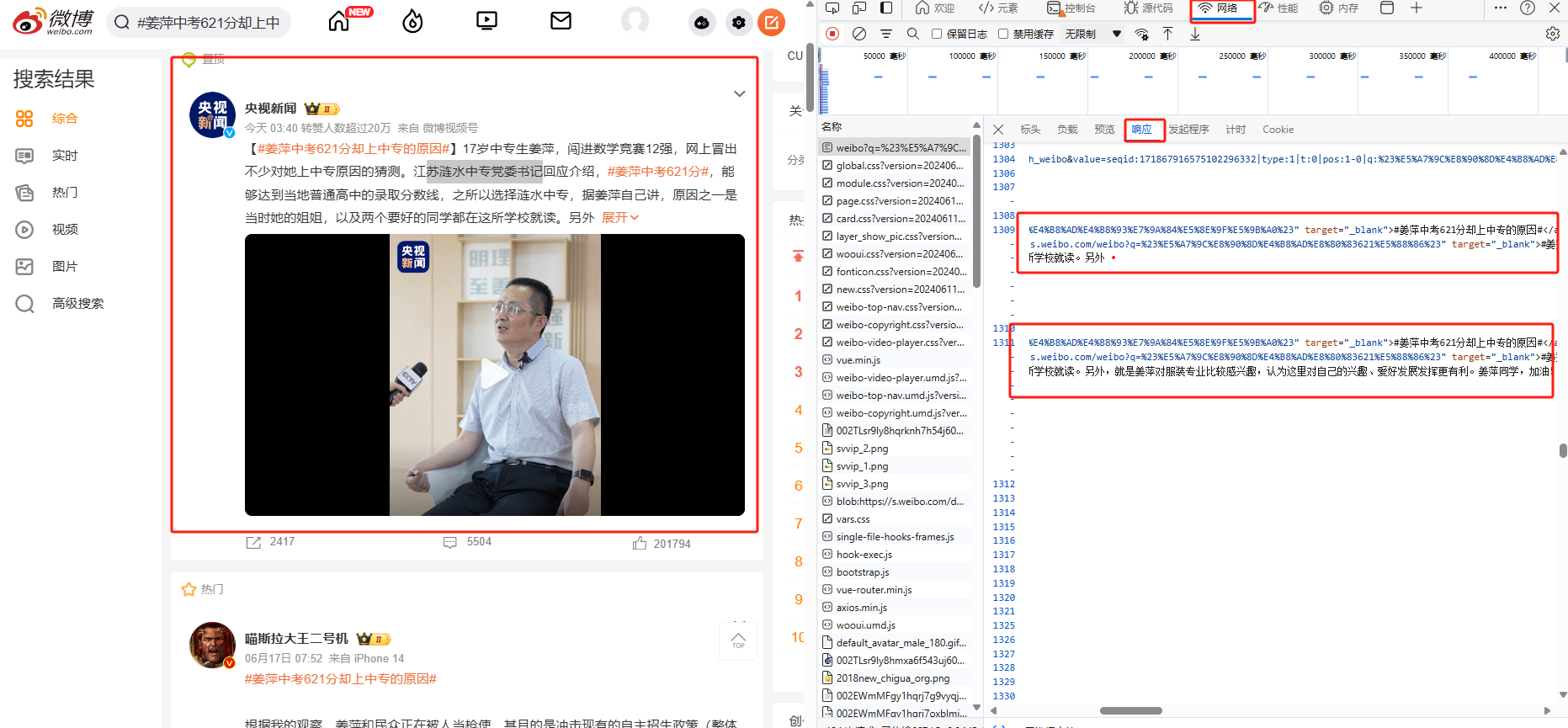
在保存响应内容为 resp.html 后,在这里我们用 scrapy 爬虫框架中的解析器 parsel 来进行解析
# parse_html.py
from parsel import Selector
import pandas as pd
import re
import time
def get_html_text(file_path):
with open(file_path, mode="r", encoding="utf-8") as f:
html_text = f.read()
return html_text
def parse_html(html_text):
lst = []
select = Selector(html_text)
select.xpath("//i").drop()
# 获取总页数
total_page = select.xpath(
'//ul[@node-type="feed_list_page_morelist"]/li/a/text()'
).getall()[-1]
total_page = int(re.findall(r"[\d]+", total_page)[0])
# 获取主体信息
div_list = select.xpath(
'//*[@id="pl_feedlist_index"]//div[@action-type="feed_list_item"]'
).getall()
for div_string in div_list:
select = Selector(div_string)
mid = select.xpath("//div[@mid]/@mid").get()
personal_name = select.xpath("//a[@nick-name]/@nick-name").get()
personal_href = select.xpath("//a[@nick-name]/@href").get()
publish_time = select.xpath('//div[@class="from"]/a[1]/text()').get()
content_from = select.xpath('//div[@class="from"]/a[2]/text()').get()
content_show = select.xpath('string(//p[@node-type="feed_list_content"])').get()
content_all = select.xpath(
'string(//p[@node-type="feed_list_content_full"])'
).get()
retweet_num = select.xpath('string(//div[@class="card-act"]/ul[1]/li[1])').get()
comment_num = select.xpath('string(//div[@class="card-act"]/ul[1]/li[2])').get()
star_num = select.xpath('string(//div[@class="card-act"]/ul[1]/li[3])').get()
item = [
mid,
personal_name,
personal_href,
publish_time,
content_from,
content_show,
content_all,
retweet_num,
comment_num,
star_num,
]
lst.append(item)
columns = [
"mid",
"个人昵称",
"个人主页",
"发布时间",
"内容来自",
"展示内容",
"全部内容",
"转发数量",
"评论数量",
"点赞数量",
]
data = pd.DataFrame(lst, columns=columns)
return data, total_page
def process_time(publish_time):
now = int(time.time())
publish_time = publish_time.strip()
if "人数" in publish_time:
publish_time = " ".join(publish_time.split()[:-1])
publish_time = publish_time.replace("今天 ", "今天")
if "分钟前" in publish_time:
minutes = re.findall(r"([\d].*)分钟前", publish_time)[0]
now = now - int(minutes) * 60
timeArray = time.localtime(now)
publish_time = time.strftime("%m月%d日 %H:%M", timeArray)
if "今天" in publish_time:
timeArray = time.localtime(now)
today = time.strftime("%m月%d日 ", timeArray)
publish_time = publish_time.replace("今天", today)
return publish_time
def process_dataframe(data):
data.insert(
1, "uid", data["个人主页"].map(lambda href: re.findall(r"com/(.*)\?", href)[0])
)
data["个人主页"] = "https:" + data["个人主页"]
data["个人主页"] = data["个人主页"].map(lambda x: re.findall(r"(.*)\?", x)[0])
data["发布时间"] = data["发布时间"].map(process_time)
data.iloc[:, 6:] = data.iloc[:, 6:].applymap(
lambda x: x.replace("\n", "").replace(" ", "") if x else None
) # 清楚掉 \n 和 空格
data["全部内容"] = data["全部内容"].map(
lambda x: x[:-2] if x else None
) # 清除掉收起
data.iloc[:, -3:] = data.iloc[:, -3:].applymap(
lambda x: 0 if x in ["转发", "评论", "赞"] else x
)
return data
def get_dataframe_from_html_text(html_text):
data, total_page = parse_html(html_text)
process_dataframe(data)
return data, total_page
if __name__ == "__main__":
html_text = get_html_text("./resp.html")
data, total_page = get_dataframe_from_html_text(html_text)
print(data, total_page)
这串代码同时还解析到了该话题总页码数,运行该代码可以获得 data 如下所示
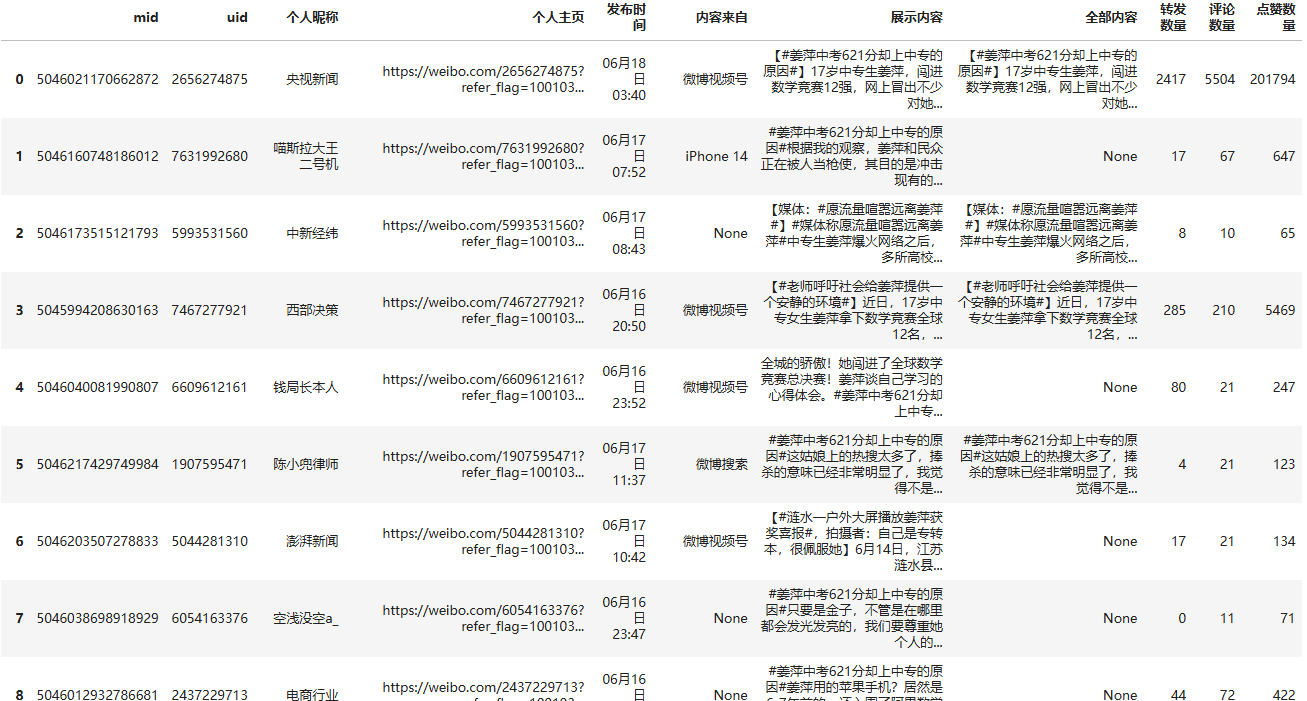
这里的 mid , uid 两个参数是为了下一节获取微博评论内容需要用到的参数,这里不多解释,如果不需要删除就好,接下来我们看一下请求内容。在开始之前,为了对请求解析方便,在这里我们点击一下 查看全部搜索结果
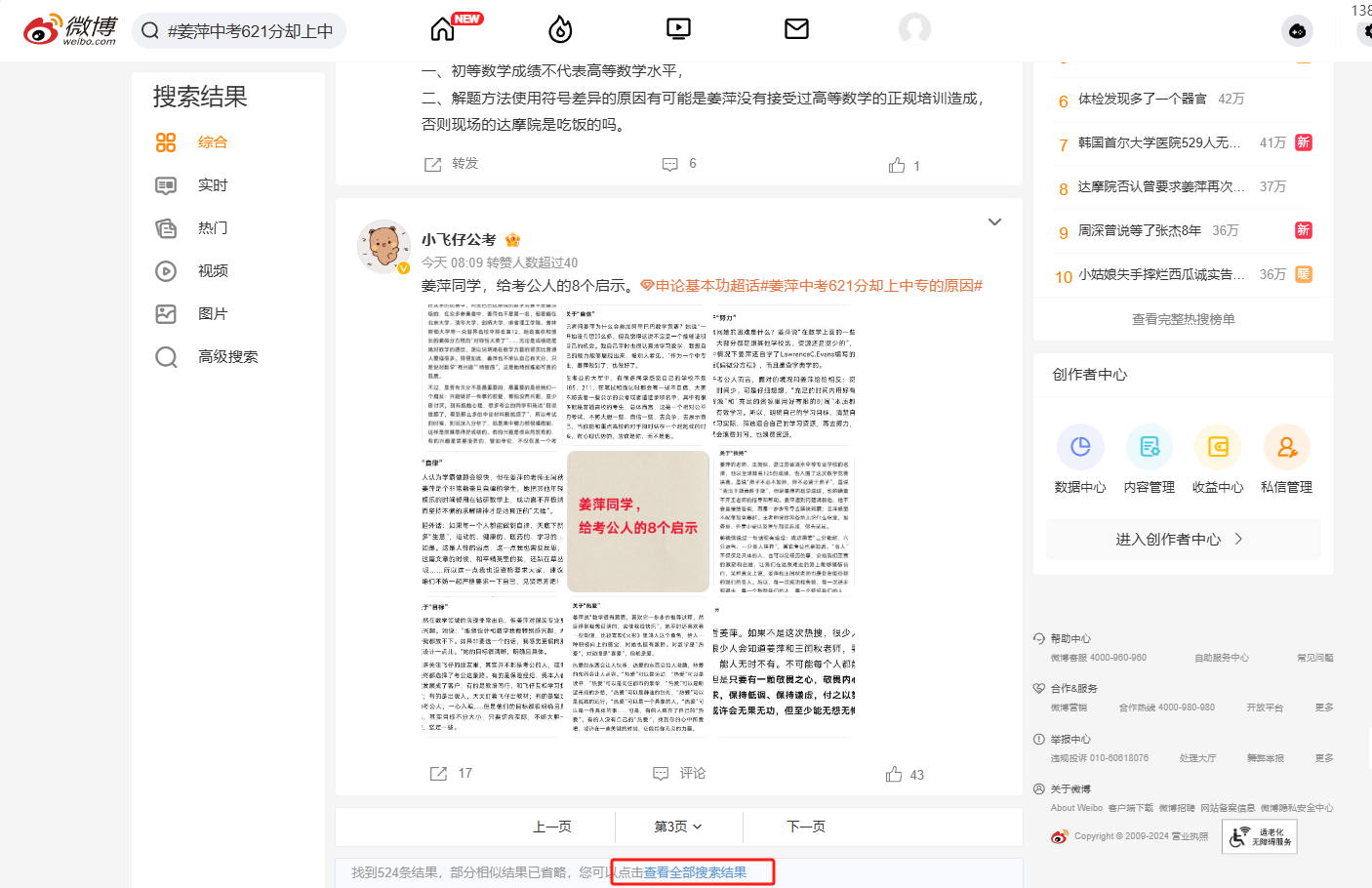
可以发现一个以 weibo 开头的新的请求,请求内容类似,但是带了参数 q 和nodup ,再翻页之后我们可以得到 page 这一个参数
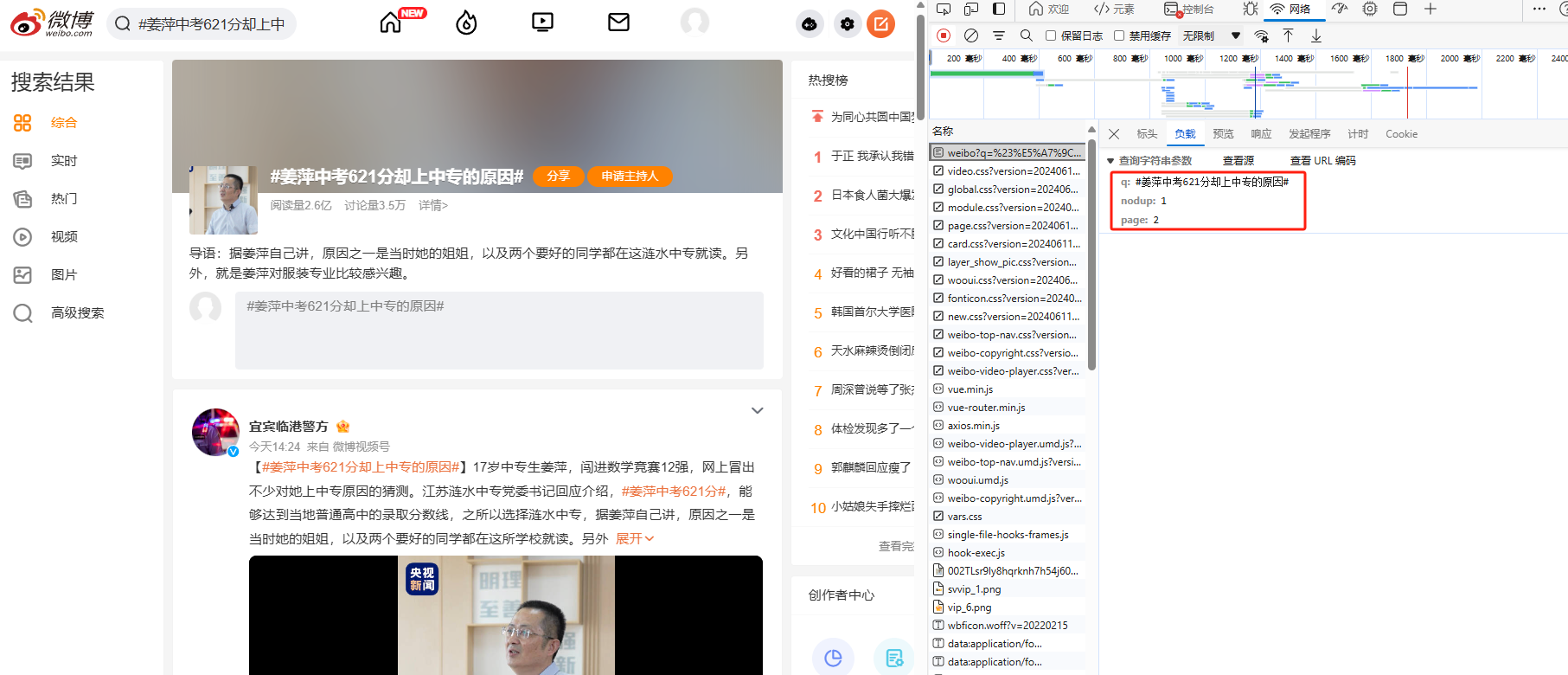
参数解析如下:
1. q:话题
2. nudup:是否展示完整内容
3. page:页码
然后可以对这个请求进行模拟,结合之前的解析,加入综合,实时,热门以及高级功能,得到完整代码如下:
# get_main_body.py
import requests
from urllib import parse
from parse_html import get_dataframe_from_html_text
import logging
from rich.progress import track
import pandas as pd
logging.basicConfig(level=logging.INFO)
def get_the_main_body_response(q, kind, p, cookie, timescope=None):
"""
q表示的是话题;
kind表示的是类别:综合,实时,热门,高级;
p表示的页码;
timescope表示高级的时间,不用高级无需带入 example:"2024-03-01-0:2024-03-27-16"
""" kind_params_url = {
"综合": [
{"q": q, "Refer": "weibo_weibo", "page": p},
"https://s.weibo.com/weibo",
],
"实时": [
{
"q": q,
"rd": "realtime",
"tw": "realtime",
"Refer": "realtime_realtime",
"page": p,
},
"https://s.weibo.com/realtime",
],
"热门": [
{
"q": q,
"xsort": "hot",
"suball": "1",
"tw": "hotweibo",
"Refer": "realtime_hot",
"page": p,
},
"https://s.weibo.com/hot",
],
# 高级中的xsort删除后就是普通的排序
"高级": [
{
"q": q,
"xsort": "hot",
"suball": "1",
"timescope": f"custom:{timescope}",
"Refer": "g",
"page": p,
},
"https://s.weibo.com/weibo",
],
}
params, url = kind_params_url[kind]
headers = {
"authority": "s.weibo.com",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"referer": url
+ "?"
+ parse.urlencode(params).replace(
f'&page={params["page"]}', f'&page={int(params["page"]) - 1}'
),
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"cookie": cookie,
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69",
}
response = requests.get(url, params=params, headers=headers)
return response
def get_all_main_body(q, kind, cookie, timescope=None):
# 初始化数据
data_list = []
resp = get_the_main_body_response(q, kind, 1, cookie, timescope)
html_text = resp.text
try:
data, total_page = get_dataframe_from_html_text(html_text)
data_list.append(data)
logging.info(
f"话题:{q},类型:{kind},解析成功,一共有{total_page:2d}页,准备开始解析..."
)
for current_page in track(range(2, total_page + 1), description=f"解析中..."):
html_text = get_the_main_body_response(
q, kind, current_page, cookie, timescope
).text
data, total_page = get_dataframe_from_html_text(html_text)
data_list.append(data)
data = pd.concat(data_list).reset_index(drop=True)
logging.info(f"话题:{q},类型:{kind},{total_page:2d}页,已经解析完毕!")
return data
except Exception as e:
logging.warning("解析页面失败,请检查你的cookie是否正确!")
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
q = "#姜萍中考621分却上中专的原因#" # 话题
kind = "热门" # 综合,实时,热门,高级
cookie = "" # 设置你的cookie
data = get_all_main_body(q, kind, cookie)
data.to_csv("demo.csv", encoding="utf_8_sig")
得到结果如下,要注意由于 有 rich 显示进度条,最好使用 python get_main_body.py 运行文件
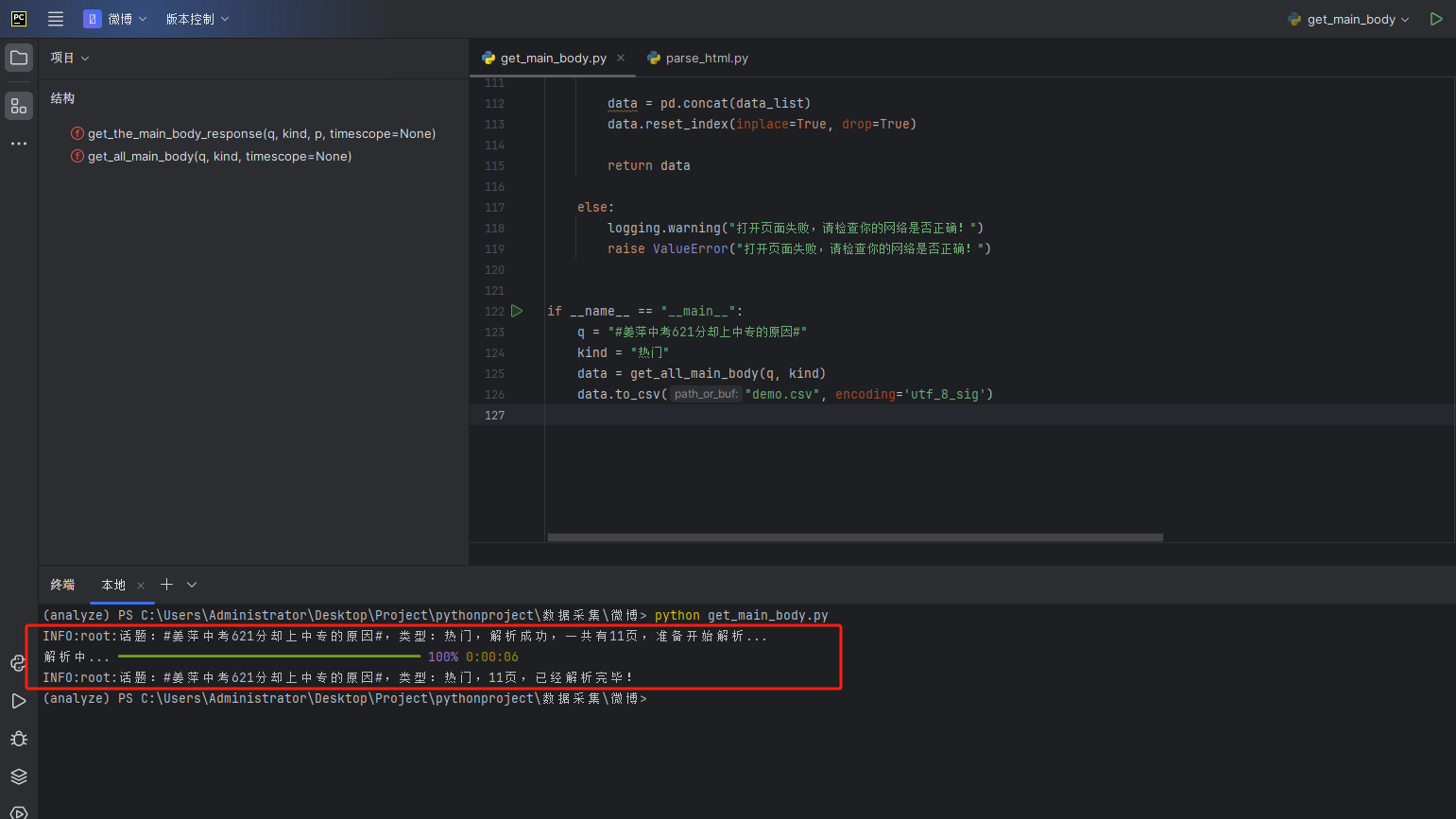
得到数据一共有 11页,107 个,中间有3个广告
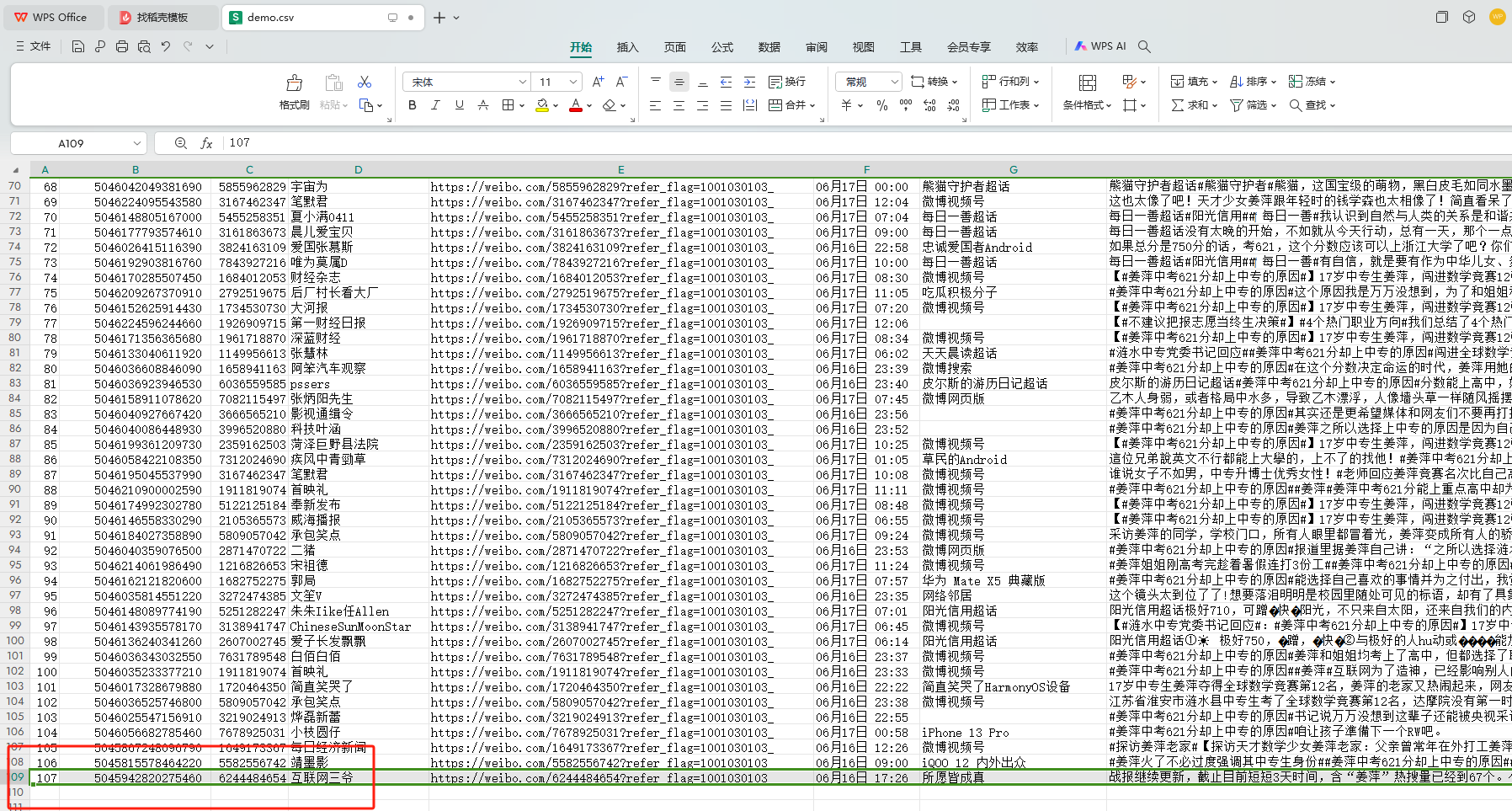
主体内容获取完毕!
三、微博评论内容获取流程
一级评论内容
上一大节内容中我们获取了微博主题内容,可以发现并没有什么难点,本来我以为都结束了,队长偏要评论内容,无奈我只好继续解析评论内容,接下来我们来获取微博评论内容,有一点点绕。
首先我们点开评论数较多的微博, 然后点击 后面还有5559条评论,点击查看
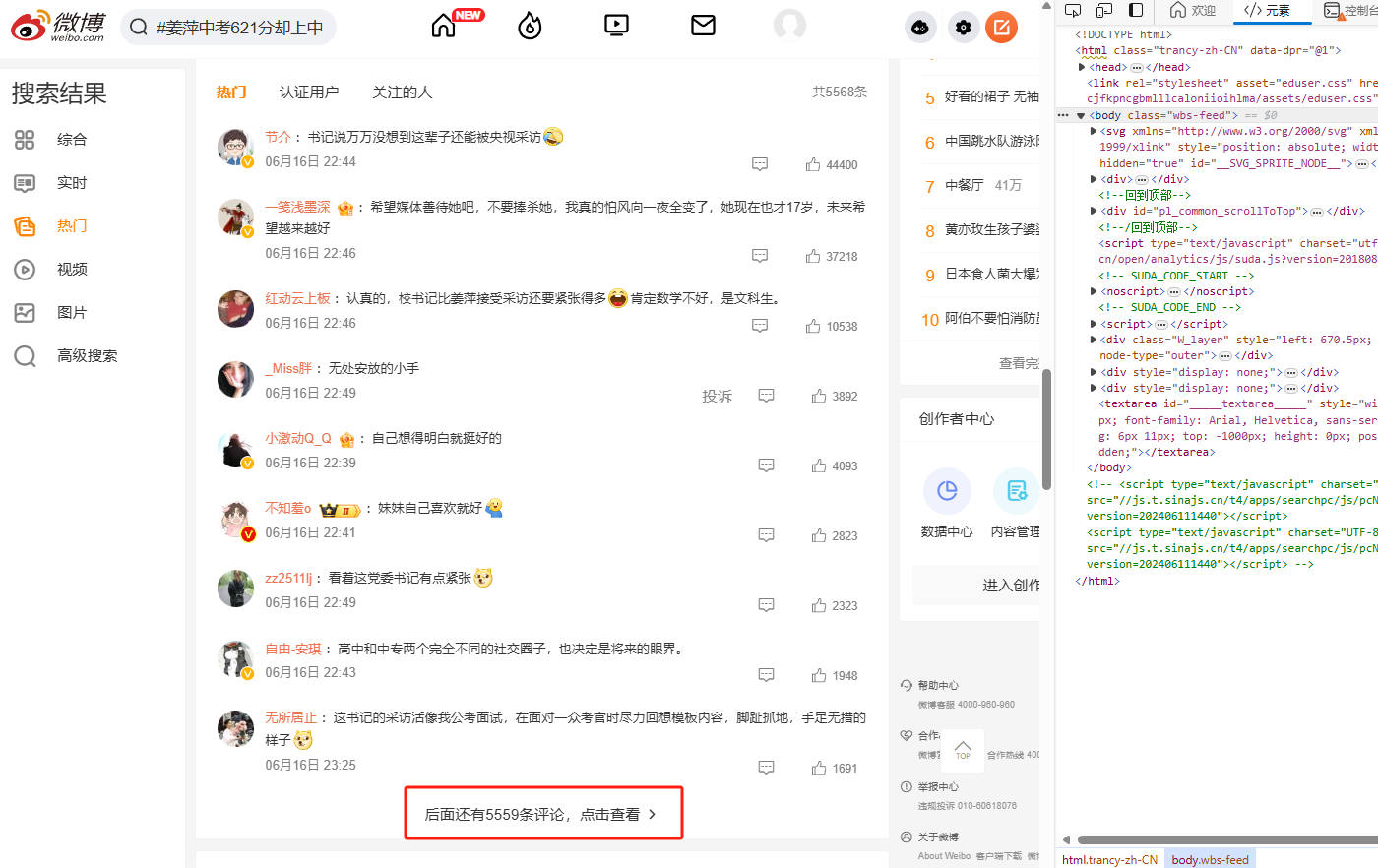
看到 < div class=“vue-recycle-scroller__item-wrapper” > 这个内容是我们想要的,仔细观察可以发现,元素中的内容数量随着鼠标的移动并没有发生变化,变化的只是内容,因此我们可以断定肯定不是解析 html
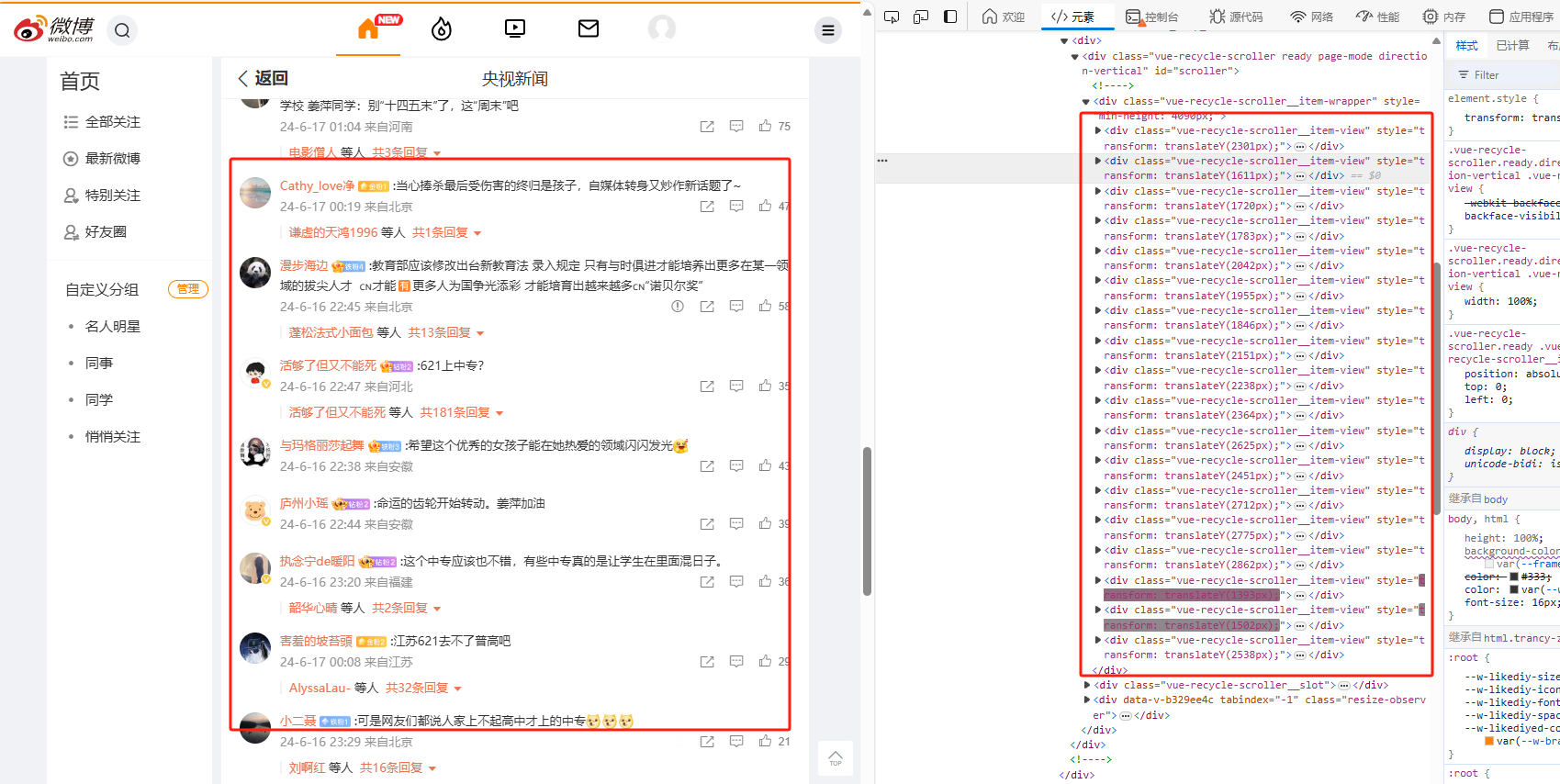
和上一节一样来查找请求, 发现 buildComments?is_reload=1&id= 这个请求包含了我们想要的信息,而且预览内容为 json 格式,省去了解析 html 的步骤,接下来只需要解析请求就ok了。
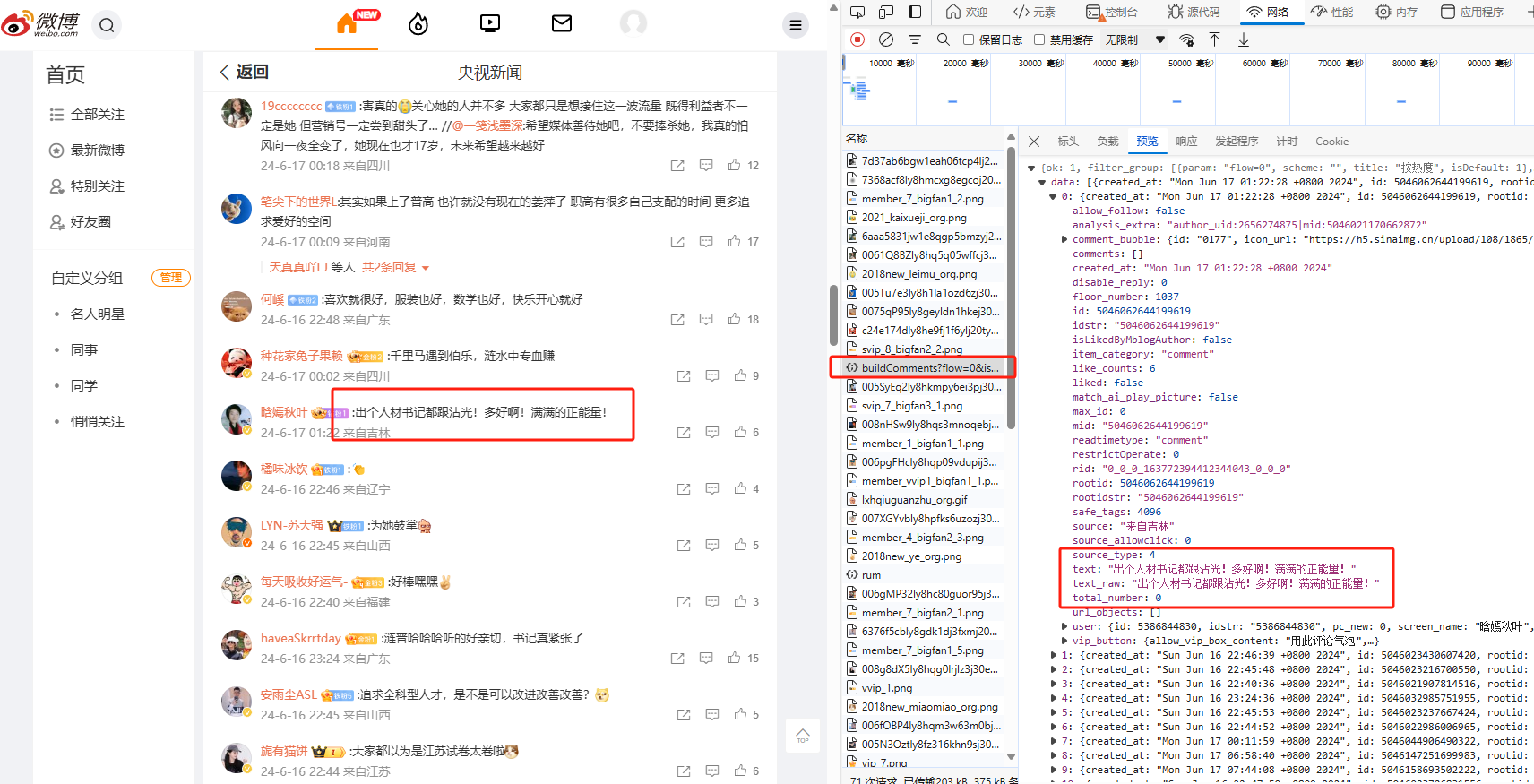
接下来我们查看参数页面,获得参数如下
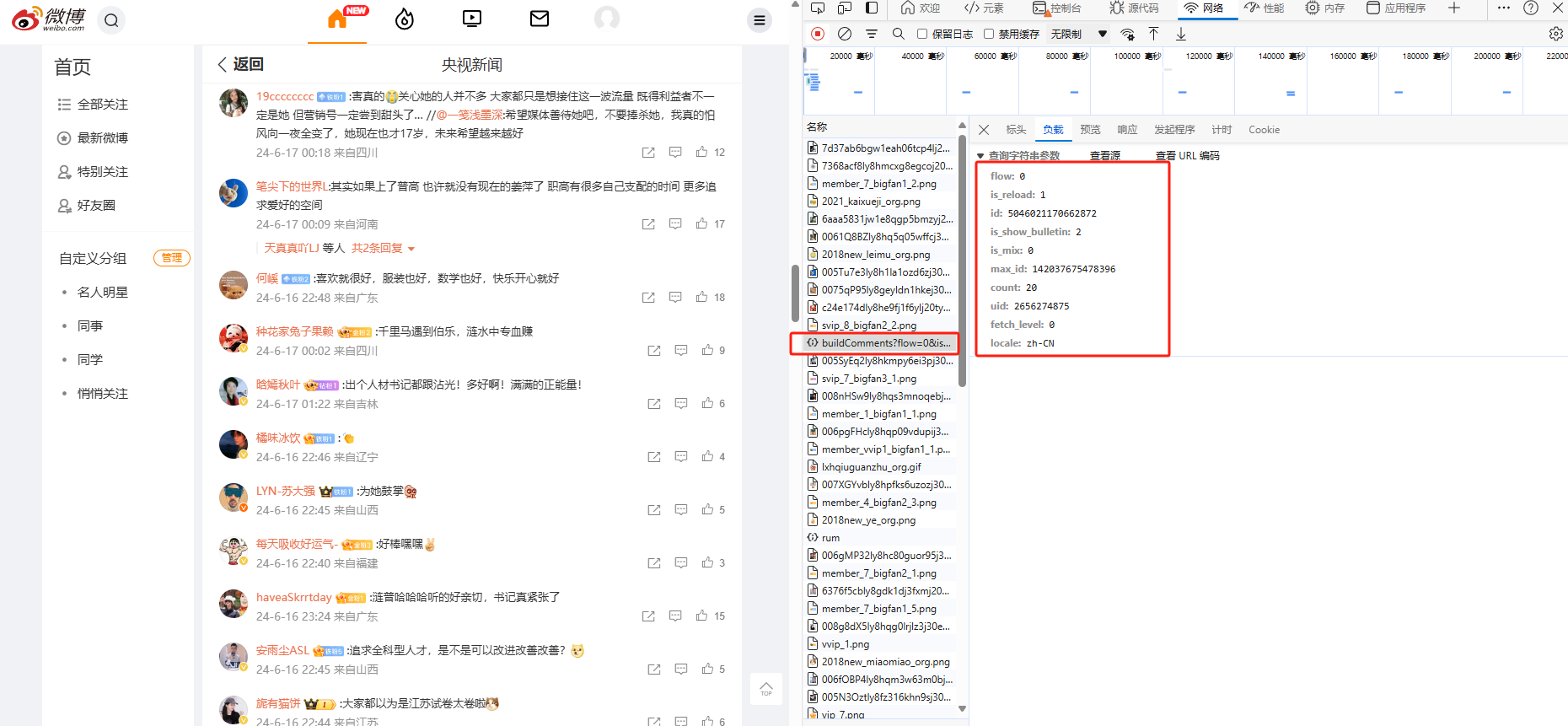
分析发现:每次往下滑动都会出现两个请求,一个是 buildComments?flow=0&is_reload=1&id=49451497063731… ,一个是 rum 。同时 buildComments?flow=0&is_reload=1&id=49451497063731… 请求的参数随着请求的次数不同发生了变化,第一次请求里面没有 flow 和 max_id 这两个参数,经过分析可以得到以下结果:
- flow:判断是否第一次请求,第一次请求不能加
- id:微博主体内容的id 上一节获取的mid
- count:评论数
- uid:微博主体内容的用户id 上一节获取的uid
- max_id:上一次请求后最后一个评论的mid,第一次请求不能加
- 其他参数保持不变
- rum在buildComments之后验证请求是否人为发出,反爬机制
- rum的参数围绕buildComments展开
- rum构造完全凑巧,部分参数对结果无效,能用就行!
同时,在手动刷新请求的时候,观察到最多可以获取到的请求只有15个
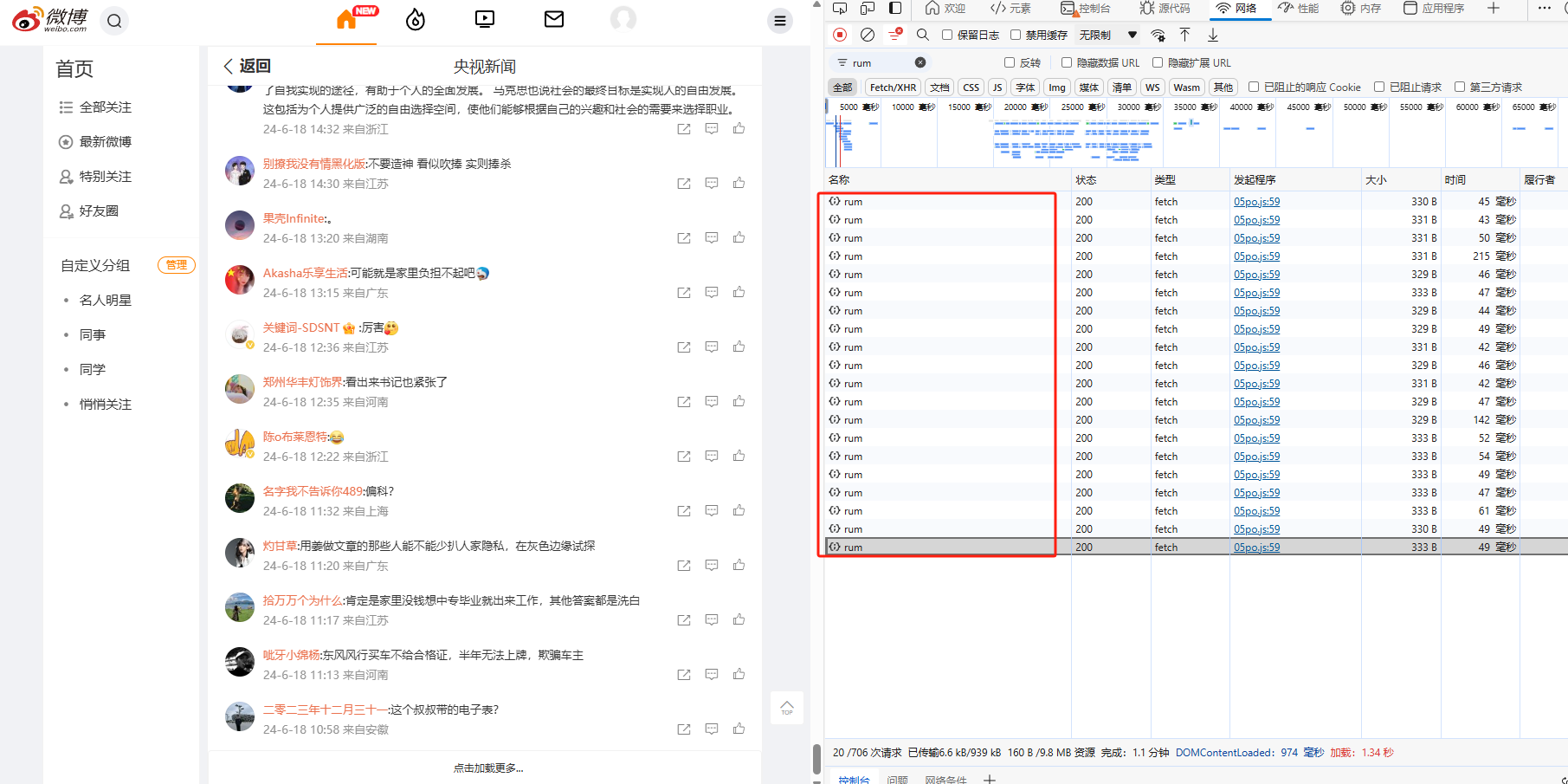
在这里 点击加载更多… 无效,所以一级评论我们最多只能获取到15页,同时后面几页还可能是空的
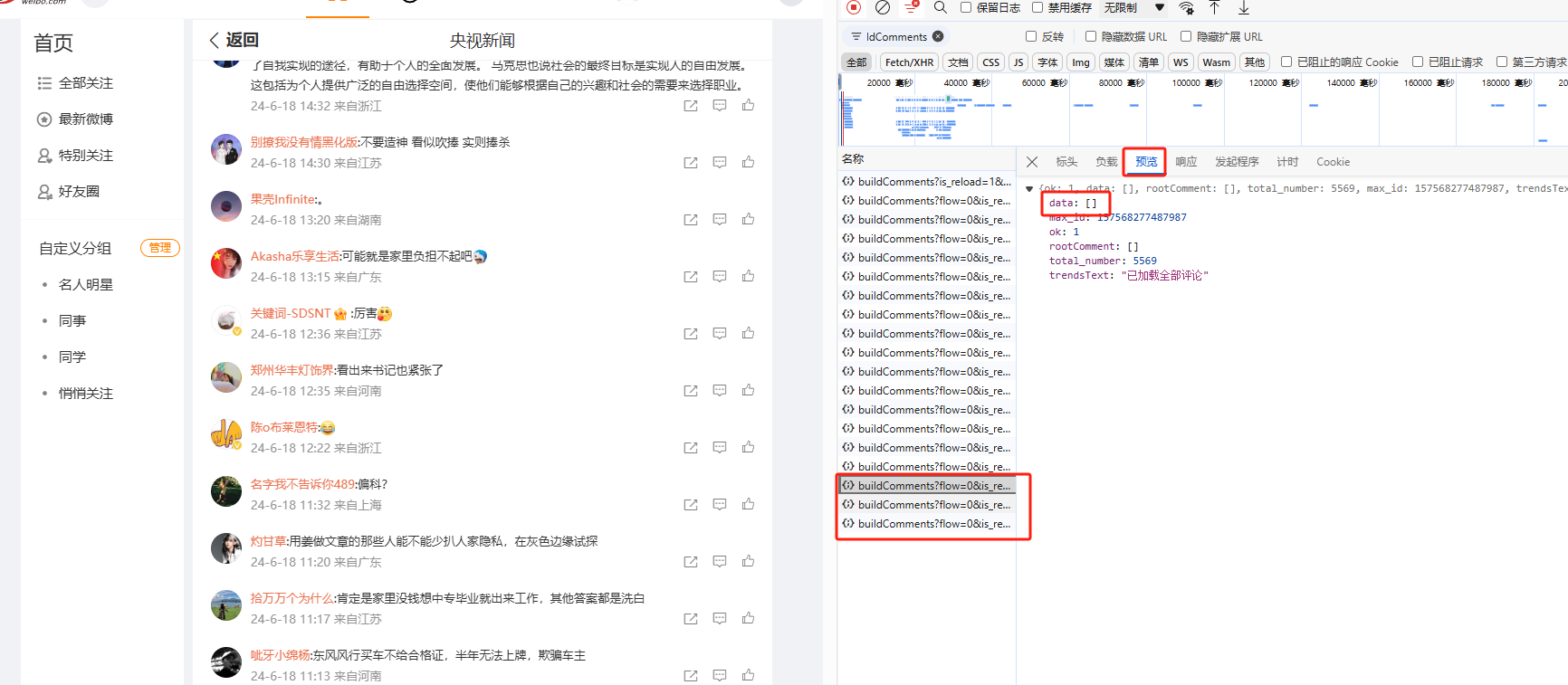
这里构造 buildComments 和 rum 请求获取一级评论内容的完整代码如下
# get_comments_level_one.py
import requests
import pandas as pd
import json
from rich.progress import track
from dateutil import parser
import logging
logging.basicConfig(level=logging.INFO)
def get_buildComments_level_one_response(uid, mid, cookie, the_first=True, max_id=None):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
params = {
"is_reload": "1",
"id": f"{mid}",
"is_show_bulletin": "2",
"is_mix": "0",
"count": "20",
"uid": f"{uid}",
"fetch_level": "0",
"locale": "zh-CN",
}
if not the_first:
params["flow"] = 0
params["max_id"] = max_id
response = requests.get(
"https://weibo.com/ajax/statuses/buildComments", params=params, headers=headers
)
return response
def get_rum_level_one_response(buildComments_url, cookie):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
entry = {"name": buildComments_url}
files = {
"entry": (None, json.dumps(entry)),
"request_id": (None, ""),
}
# 这个resp返回值无实际意义,返回值一直是{ok: 1}
requests.post("https://weibo.com/ajax/log/rum", headers=headers, files=files)
def get_level_one_response(uid, mid, cookie, the_first=True, max_id=None):
buildComments_resp = get_buildComments_level_one_response(
uid, mid, cookie, the_first, max_id
)
buildComments_url = buildComments_resp.url
get_rum_level_one_response(buildComments_url, cookie)
data = pd.DataFrame(buildComments_resp.json()["data"])
max_id = buildComments_resp.json()["max_id"]
return max_id, data
def process_time(publish_time):
publish_time = parser.parse(publish_time)
publish_time = publish_time.strftime("%y年%m月%d日 %H:%M")
return publish_time
def process_data(data):
data_user = pd.json_normalize(data["user"])
data_user_col_map = {
"id": "uid",
"screen_name": "用户昵称",
"profile_url": "用户主页",
"description": "用户描述",
"location": "用户地理位置",
"gender": "用户性别",
"followers_count": "用户粉丝数量",
"friends_count": "用户关注数量",
"statuses_count": "用户全部微博",
"status_total_counter.comment_cnt": "用户累计评论",
"status_total_counter.repost_cnt": "用户累计转发",
"status_total_counter.like_cnt": "用户累计获赞",
"status_total_counter.total_cnt": "用户转评赞",
"verified_reason": "用户认证信息",
}
data_user_col = [col for col in data_user if col in data_user_col_map.keys()]
data_user = data_user[data_user_col]
data_user = data_user.rename(columns=data_user_col_map)
data_main_col_map = {
"created_at": "发布时间",
"text": "处理内容",
"source": "评论地点",
"mid": "mid",
"total_number": "回复数量",
"like_counts": "点赞数量",
"text_raw": "原生内容",
}
data_main_col = [col for col in data if col in data_main_col_map.keys()]
data_main = data[data_main_col]
data_main = data_main.rename(columns=data_main_col_map)
data = pd.concat([data_main, data_user], axis=1)
data["发布时间"] = data["发布时间"].map(process_time)
data["用户主页"] = "https://weibo.com" + data["用户主页"]
return data
def get_all_level_one(uid, mid, cookie, max_times=15):
# 初始化
max_id = ""
data_lst = []
max_times = max_times # 最多只有15页
logging.info(f"uid:{uid},mid:{mid},页数最多有{max_times},现在开始解析...")
try:
for current_times in track(range(1, max_times), description=f"解析中..."):
if current_times == 0:
max_id, data = get_level_one_response(uid=uid, mid=mid, cookie=cookie)
else:
max_id, data = get_level_one_response(
uid=uid, mid=mid, cookie=cookie, the_first=False, max_id=max_id
)
if data.shape[0] != 0:
data_lst.append(data)
if max_id == 0:
break
logging.info(
f"uid:{uid},mid:{mid},页数一共有{len(data_lst)}页,已经解析完毕!"
)
if data_lst:
data = pd.concat(data_lst).reset_index(drop=True)
data = process_data(data)
data.insert(0, "main_body_uid", uid)
data.insert(0, "main_body_mid", mid)
return data
else:
return pd.DataFrame()
except Exception as e:
logging.warning("解析页面失败,请检查你的cookie是否正确!")
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
# 这里的uid,mid是主体内容的uid和mid
uid = "1006550592"
mid = "5046560175424086"
cookie = "" # 设置你的cookie
data = get_all_level_one(uid, mid, cookie)
data.to_csv("demo_comments.csv", encoding="utf_8_sig")
可以得到数据 demo_comments.csv 如下
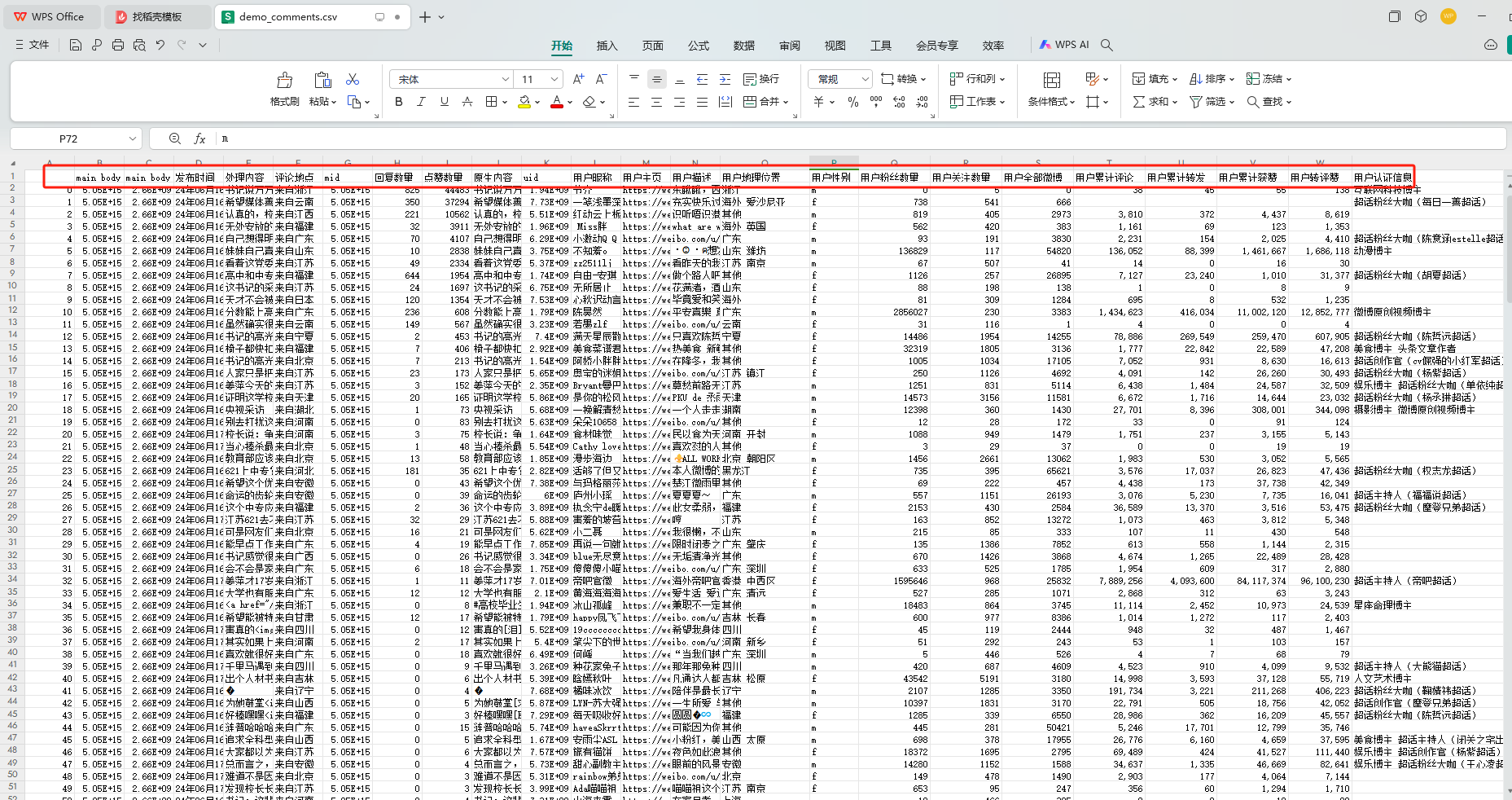
一级评论内容获取完毕!
二级评论内容
二级评论的流程和一级评论一致,每一次数据获取都是由两个请求 buildComments 和 rum 组成,区别是参数的不同,一级评论的参数和二级评论的参数对比如下
# 一级评论的参数
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '0',
'count': '20',
'uid': f'{uid}',
'fetch_level': '0',
'locale': 'zh-CN',
}
# 二级评论的参数
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '1',
'fetch_level': '1',
'max_id': '0',
'count': '20',
'uid': f'{uid}',
'locale': 'zh-CN',
}
二级评论参数的 uid 指的是微博主体内容的作者 uid ,而 mid 指的是评论者的 mid ,有了这个直接套用一级评论内容的代码,完整代码如下
# get_comments_level_two.py
import requests
import pandas as pd
import json
from rich.progress import track
from dateutil import parser
import logging
logging.basicConfig(level=logging.INFO)
def get_buildComments_level_two_response(uid, mid, cookie, the_first=True, max_id=None):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
params = {
"is_reload": "1",
"id": f"{mid}",
"is_show_bulletin": "2",
"is_mix": "1",
"fetch_level": "1",
"max_id": "0",
"count": "20",
"uid": f"{uid}",
"locale": "zh-CN",
}
if not the_first:
params["flow"] = 0
params["max_id"] = max_id
response = requests.get(
"https://weibo.com/ajax/statuses/buildComments", params=params, headers=headers
)
return response
def get_rum_level_two_response(buildComments_url, cookie):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
entry = {"name": buildComments_url}
files = {
"entry": (None, json.dumps(entry)),
"request_id": (None, ""),
}
# 这个resp返回值无实际意义,返回值一直是{ok: 1}
requests.post("https://weibo.com/ajax/log/rum", headers=headers, files=files)
def get_level_two_response(uid, mid, cookie, the_first=True, max_id=None):
buildComments_resp = get_buildComments_level_two_response(
uid, mid, cookie, the_first, max_id
)
buildComments_url = buildComments_resp.url
get_rum_level_two_response(buildComments_url, cookie)
data = pd.DataFrame(buildComments_resp.json()["data"])
max_id = buildComments_resp.json()["max_id"]
return max_id, data
def process_time(publish_time):
publish_time = parser.parse(publish_time)
publish_time = publish_time.strftime("%y年%m月%d日 %H:%M")
return publish_time
def process_data(data):
data_user = pd.json_normalize(data["user"])
data_user_col_map = {
"id": "uid",
"screen_name": "用户昵称",
"profile_url": "用户主页",
"description": "用户描述",
"location": "用户地理位置",
"gender": "用户性别",
"followers_count": "用户粉丝数量",
"friends_count": "用户关注数量",
"statuses_count": "用户全部微博",
"status_total_counter.comment_cnt": "用户累计评论",
"status_total_counter.repost_cnt": "用户累计转发",
"status_total_counter.like_cnt": "用户累计获赞",
"status_total_counter.total_cnt": "用户转评赞",
"verified_reason": "用户认证信息",
}
data_user_col = [col for col in data_user if col in data_user_col_map.keys()]
data_user = data_user[data_user_col]
data_user = data_user.rename(columns=data_user_col_map)
data_main_col_map = {
"created_at": "发布时间",
"text": "处理内容",
"source": "评论地点",
"mid": "mid",
"total_number": "回复数量",
"like_counts": "点赞数量",
"text_raw": "原生内容",
}
data_main_col = [col for col in data if col in data_main_col_map.keys()]
data_main = data[data_main_col]
data_main = data_main.rename(columns=data_main_col_map)
data = pd.concat([data_main, data_user], axis=1)
data["发布时间"] = data["发布时间"].map(process_time)
data["用户主页"] = "https://weibo.com" + data["用户主页"]
return data
def get_all_level_two(uid, mid, cookie, max_times=15):
# 初始化
max_id = ""
data_lst = []
max_times = max_times # 最多只有15页
logging.info(f"uid:{uid},mid:{mid},页数最多有{max_times},现在开始解析...")
try:
for current_times in track(range(1, max_times)):
if current_times == 0:
max_id, data = get_level_two_response(uid=uid, mid=mid, cookie=cookie)
else:
max_id, data = get_level_two_response(
uid=uid, mid=mid, cookie=cookie, the_first=False, max_id=max_id
)
if data.shape[0] != 0:
data_lst.append(data)
if max_id == 0:
break
logging.info(
f"uid:{uid},mid:{mid},页数一共有{len(data_lst)}页,已经解析完毕!"
)
if data_lst:
data = pd.concat(data_lst).reset_index(drop=True)
data = process_data(data)
data.insert(0, "main_body_uid", uid)
data.insert(0, "comments_level_1_mid", mid)
return data
else:
return pd.DataFrame()
except Exception as e:
logging.warning("解析页面失败,请检查你的cookie是否正确!")
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
# 这里 main_body_uid 是主体内容中的uid
# 这里 mid 是一级评论中的mid
main_body_uid = "2656274875"
mid = "5046022789400609"
cookie = "" # 设置你的cookie
data = get_all_level_two(main_body_uid, mid, cookie)
data.to_csv("demo_comments_two.csv", encoding="utf_8_sig")
可以得到数据 demo_comments_two.csv 如下
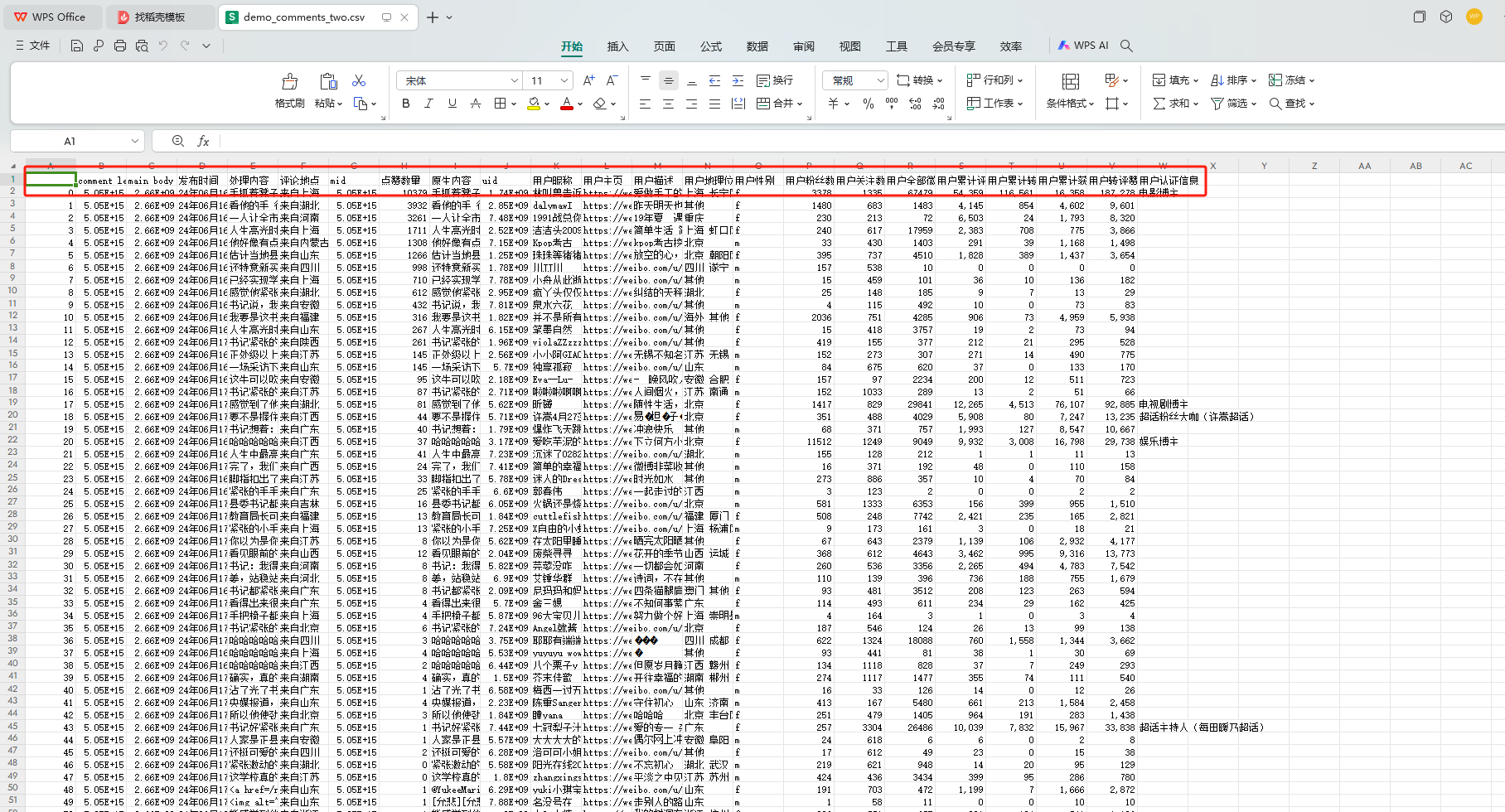
二级评论内容获取完毕!
四、问题汇总
1. csv文件乱码
把 df.to_csv(...) 改为 df.to_csv(..., encoding='utf_8_sig')
2. 获取 Cookie
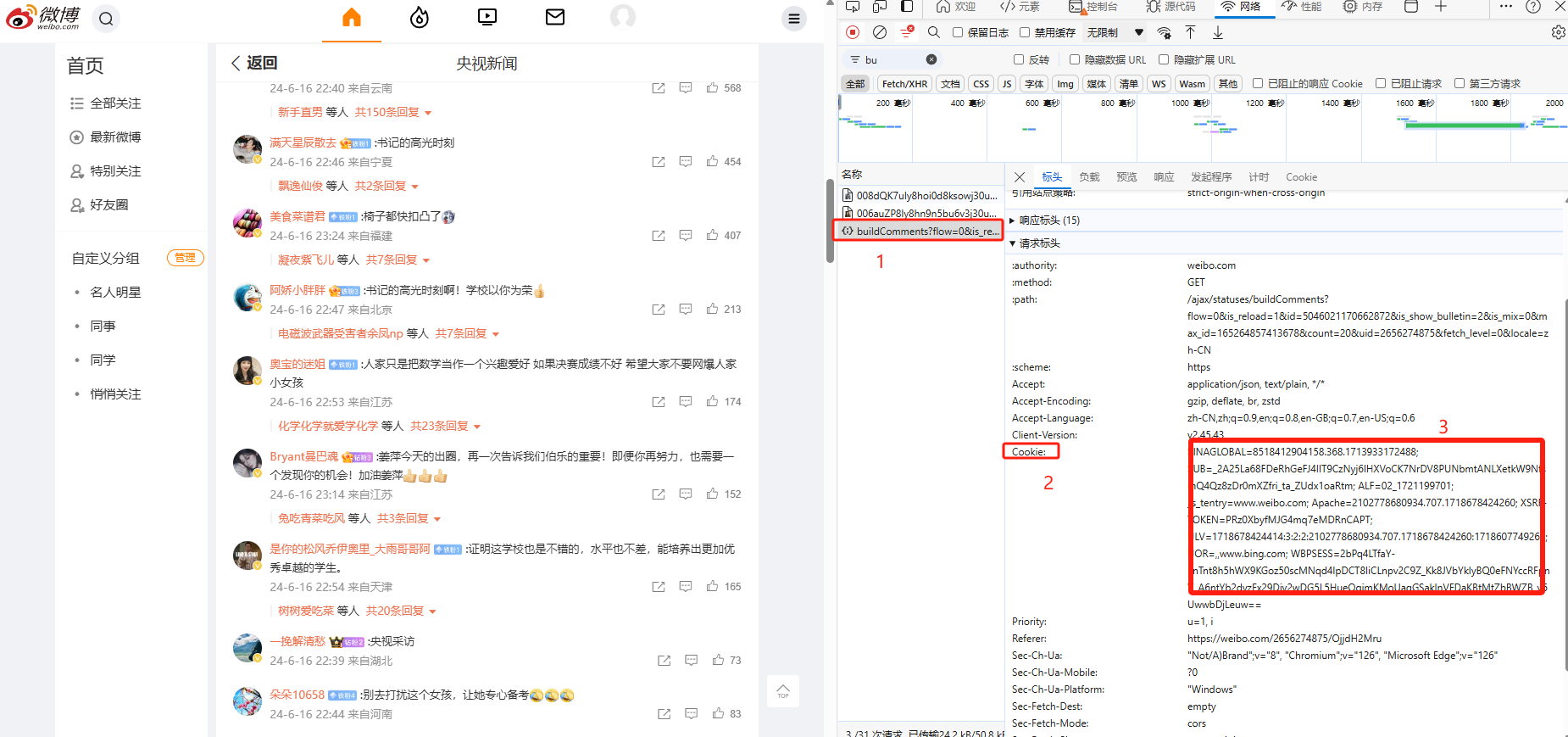
复制 buildComments 请求中的 cookie 就可以了

















 3964
3964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









