










http://sklearn.apachecn.org/cn/0.19.0/modules/model_evaluation.html
除了使用estimator的score函数简单粗略地评估模型的质量之外,
在sklearn.model_selection模块中的交叉验证相关方法可以评估模型的泛化能力,能够有效避免过拟合。
6.1、metrics评估
sklearn.metrics中的评估模型指标有两类:
- 以_score结尾的分越高越好,_error ;
- 以 _loss结尾的分越小越好。
常用的分类评估:accuracy_score , f1_score , precision_score , recall_score
常用的回归评估:r2_score , explained_variance_score
常用的聚类评估:adjusted_rand_score , adjusted_mutual_info_score
分类模型评估
模型分类效果全部信息:
- confusion_matrix混淆矩阵,误差矩阵。
TP:True Positive 真正例
FP:False Positive 假正例
FN:False Negative 假反例
TN:True Negative 真反例 - 模型整体分类效果:
• accuracy正确率。通用分类评估指标。
模型对某种类别的分类效果:
• precision 精确率,也叫查准率。模型不把正样本标错的能力。"不冤枉一个好人”。
• recall 召回率,也叫查全率。模型识別出全部正样本的能力。"也绝不放过一个坏人”。
• f1_scoreF1得分,精确率和召回率的调和平均值。
利用不同方式将类别分类效果进行求和平均得到整体分类效果:
• macro_averaged :宏平均。每种类别预测的效果一样重要。
• micro_averaged :微平均,每一次分类预测的效果一样重要。
• weighted_averaged :加权平均。每种类别预测的效果跟按该类别样本出现的频率成正比。
• sampled_averaged:样本平均。仅适用于多标签分类问题。根据每个样本多个标签的预测值 和真实值计算评测指标。然后对样本求平均。
仅仅适用于概率模型,且问题为二分类问题的评估方法:
• ROC曲线
• auc score


一般来说,准确率和召回率反映了分类器性能的两个方面,单一依靠某个指标并不能较为全面地评价一个分类器的性能。 假如分类器只将苹果特征十分明显、是苹果的概率非常高的样本分为苹果,其余的样本分为非苹果,此时该分类器的准确 率就会非常的高,但是它因为将所有疑似苹果都错误分为非苹果,召回率变得非常低。
假如分类器将所有可能为苹果的样本全部划分为苹果,其余的样本为非苹果,此时该分类器的召回率会非常之高,但是它 因为将所有可能为苹果的样本分为苹果时引入了许多错误,准确率不可能高。
引入F1-Score作为综合指标,就是为了平衡准确率和召回率的影响,较为全面地评价一个分类器。
有时候考虑到不同的需求,可能会更看重准确率或者召回率。这时我们可以引入F2-Score和F0.5-Score。包括F1-Score, 这三个指标都来自以下定义,只是参数不同。
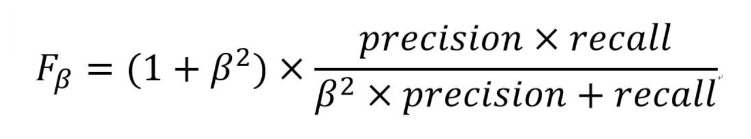
其中,F1-Score是指准确率和召回率一样重要;
F2-Score是指召回率比准确率重要一倍;
F0.5-Score是指准确率比召回率重要一倍。
from sklearn import metrics
y_pred=[0,0,0,1,1,1,1,1,0,1]
y_true=[0,0,1,1,1,1,1,0,0,0]
print('混淆矩阵:')
print(metrics.confusion_matrix(y_true,y_pred))
print('准确率:',metrics.accuracy_score(y_true,y_pred))
print('类别精度:',metrics.precision_score(y_true,y_pred,average=None)) # 不求平均值
print('宏平均精度:',metrics.precision_score(y_true,y_pred,average='macro'))
print('微平均召回率:',metrics.precision_score(y_true,y_pred,average='micro'))
print('加权平均F1等分:',metrics.f1_score(y_true,y_pred,average='weighted'))
回归模型的评估

from sklearn.metrics import explained_variance_score
from sklearn.metrics import r2_score
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print('r2_score:',r2_score(y_true,y_pred))
print('explained_variance_score:',explained_variance_score(y_true,y_pred))
# 均方误差
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(cars["mpg"], predictions)
print(mse)
使用虚拟估计器产生基准得分
对于监督学习(分类和回归),可以用一些基于经验的简单估计策略(虚拟估计)的得分作为参照基准值
DummyClassifier实现了几种简单的分类策略:
- stratified通过训练集分布方方面来生成随机预测;
- most_frequent 总是预测训练集中最常见的标签;
- prior 类似 most_frequent,但具有precit_proba方法;
- uniform随机产生预测;
- constant总是预测用户提供的常量标签。
DummyRegressor实现了四个简单的经验法则来进行回归:
- mean 总是预测训练目标的平均值;
- median 总是预测训练目标的中位数;
- quantile 总是预用户提供的训练目标的quantile(分位数);
- constant 总是预测由用户提供的常量值。
# 创建一个不平衡数据集(鸢尾花的0、2类改为-1类)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris=load_iris()
X,y=iris.data,iris.target
y[y!=1]=-1 # 将0,2合并成-1类
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0)
y
# 比较线性SVM分类器和虚拟估计器的得分
from sklearn.dummy import DummyClassifier
from sklearn.svm import SVC
svc=SVC(kernel='linear',C=1)
svc.fit(X_train,y_train)
print('linear SVC Classifier score:',svc.score(X_test,y_test))
dummy=DummyClassifier(strategy='most_frequent',random_state=0)
dummy.fit(X_train,y_train)
print('dummy Classifier score:',dummy.score(X_test,y_test))
# 结果
linear SVC Classifier score: 0.631578947368421
dummy Classifier score: 0.5789473684210527
# 由上可见线性分类器与虚拟估计器得分没差太多,改用核函数为rbf的svc
svcrbf=SVC(kernel='rbf',C=1)
svcrbf.fit(X_train,y_train)
print('rbf SVC Classifier score:',svcrbf.score(X_test,y_test))
结果
rbf SVC Classifier score: 0.9736842105263158
欠拟合、过拟合

交叉验证
https://www.cnblogs.com/jiaxin359/p/8552800.html


# K折交叉验证
from sklearn.model_selection import KFold
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2)
for train_index, test_index in kf.split(X):
print('train_index', train_index, 'test_index', test_index)
train_X, train_y = X[train_index], y[train_index]
test_X, test_y = X[test_index], y[test_index]
# 随机排列交叉验证
import numpy as np
from sklearn.model_selection import ShuffleSplit
X= np.arange(5)
ss=ShuffleSplit(n_splits=4,test_size=0.4,random_state=0)
# 输出的是数据的index
for train_index,test_index in ss.split(X):
print("%s %s"%(train_index,test_index))
# 分层K折交叉验证
from sklearn.model_selection import StratifiedKFold
X=np.ones(10)
y=[0,0,0,0,1,1,1,1,1,1]
skf=StratifiedKFold(n_splits=3,shuffle=False)
for train_index ,test_index in skf.split(X,y):
print("%s %s"%(train_index,test_index))
# 留p分组交叉验证
from sklearn.model_selection import LeavePGroupsOut
X=np.arange(6)
y=[1,1,1,2,2,2]
groups=[1,1,2,2,3,3]
lpgo=LeavePGroupsOut(n_groups=2)
for train_index ,test_index in lpgo.split(X,y,groups=groups):
print("%s %s"%(train_index,test_index))
# 时间序列分割
from sklearn.model_selection import TimeSeriesSplit
X=np.array([[1,2],[3,4],[1,2],[3,4],[1,2],[3,4],[2,2],[4,6]])
y=np.array([1,2,3,4,5,6,7,8])
tscv=TimeSeriesSplit(n_splits=3,max_train_size=3)
for train_index ,test_index in tscv.split(X,y):
print("%s %s"%(train_index,test_index))
交叉验证综合评分
调用cross_val_score函数可以计算模型在交叉验证数据集上的得分
可以指定metrics中的打分函数,也可以指定交叉验证迭代器
from sklearn.model_selection import cross_val_score
from sklearn import svm
from sklearn import datasets
iris=datasets.load_iris()
clf=svm.SVC(kernel='linear',C=1)
scores=cross_val_score(clf,iris.data,iris.target,cv=5)# 5折交叉验证
print(scores)
# 平均得分和在95%置信区间
print("Accuracy:%0.2f(+/-%0.2f)"%(scores.mean(),scores.std()*2))
# 默认情况下,每个CV迭代计算器的分数是估计器的score方法
# 可以通过使用scoring参数来改变计算方法
from sklearn import metrics
scores=cross_val_score(clf,iris.data,iris.target,cv=5,scoring='f1_macro')
scores
# 通过传入一个交叉迭代器来指定其他交叉验证测略
from sklearn.model_selection import ShuffleSplit
ss=ShuffleSplit(n_splits=3,test_size=0.3,random_state=0)
cross_val_score(clf,iris.data,iris.target,cv=ss)
cross_validate函数和cross_val_score函数类似,但功能更强大,它允许指定多个指标进行评估,并且除了返回指定指标外,还会返回一个fit_time和score_time即训练时间和评分时间
from sklearn.model_selection import cross_validate
from sklearn.metrics import recall_score
clf=svm.SVC(kernel='linear',C=1,random_state=0)
scores=cross_validate(clf,iris.data,iris.target,scoring=['f1_macro','f1_micro'],cv=10,return_train_score=False)
print(sorted(scores.keys()))
print('*'*70)
print(scores['fit_time'])
print('*'*70)
print(scores['score_time'])
print('*'*70)
print('f1_macro:',scores['test_f1_macro'].mean())
print('*'*70)
print('f1_micro:',scores['test_f1_micro'])
使用cross_val_predict可以返回每条样本作为CV中的测试集时,对应的模型对该样本的预测结果。
这就要求使用的CV策略能保证每一条样本都有机会作为测试数据,否则会报异常
from sklearn.model_selection import cross_val_predict
predicted=cross_val_predict(clf,iris.data,iris.target,cv=10)
print(predicted)
metrics.accuracy_score(iris.target,predicted)
召回率
ROC曲线
import matplotlib.pyplot as plt
from sklearn import metrics
probabilities = model.predict_proba(test[["gpa"]])
# 参数(测试数据的真实y,预测的概率
fpr, tpr, thresholds = metrics.roc_curve(test["actual_label"], probabilities[:,1])
print thresholds
plt.plot(fpr, tpr)
plt.show()
数据体现ROC的结果(ROC的曲线的面积)
from sklearn.metrics import roc_auc_score
probabilities = model.predict_proba(test[["gpa"]])
# Means we can just use roc_auc_curve() instead of metrics.roc_auc_curve()
auc_score = roc_auc_score(test["actual_label"], probabilities[:,1])
print(auc_score)
二分类、概率模型
混淆矩阵















 2227
2227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









