







处理器 插到系统插槽或者处理器板上的物理芯片,以核或着硬件线程的方式包含了一块或者多块CPU
核 一颗多核处理器上的一个独立CPU实例。核的使用是处理器扩展的一种方式,又称为芯片级多处理(chip-level multiprocessing ,CMP)
硬件线程 一种支持在一个核上同时执行多个线程(包括intel的超线程技术)的CPU架构,每个线程是一个独立的CPU实例。
CPU指令 单个CPU操作,来源于它的指令集。指令用于算数操作、内存I/O、逻辑控制
逻辑CPU 虚拟处理器,一个操作系统CPU的实例(一个可调度的CPU实体);处理器可以通过硬件线程(这种情况下又称为虚拟核)、一个核,或者一个单核的处理器实现
调度器 把CPU分配给线程运行的内核子系统
运行队列 一个等待CPU服务的可运行线程队列
CPU架构

上图,单个处理器内有四个核和八个硬件线程,左侧为物理架构,右侧则为操作系统视角看到的CPU景象。每个硬件线程都可以按逻辑CPU寻址,因此这个处理器看上去有八块CPU。对于这种拓扑结构,操作系统可能有一些额外信息,如哪些CPU在同一个核上,这样可以提高调度的质量。
CPU运行队列

正在运行和就绪运行的软件线程数量表示了饱和度。
花在等待CPU运行上的时间称为运行队列延时或者分发器队列延时或者调度器延时,使用调度器延时这个术语适用于所有的分发器类型,包括不使用队列的情况。
对于多处理器系统,内核通常为每个CPU提供一个运行队列,并尽量使得线程每次都被放到同一队列之中。这意味着线程更有可能在同一个CPU上运行,因为CPU缓存里保存了它们的数据(这些缓存被称为热度缓存,这种选择运行CPU的方法被称为CPU关联)。这同样也避免了队列操作的线程同步开销(mutex锁),如果运行队列时全局的并被所有CPU共享,这种开销会影响扩展性。在NUMA系统中,这会提高内存本地性,从而提高系统性能
概念
时钟频率
时钟是一个驱动所有处理器逻辑的数字信号,每个CPU指令都可能会花费一个或者多个时钟周期(CPU周期)来执行。
更快的时钟频率不一定会提高性能,它取决于快速CPU周期里到底在做些什么,如果它们大部分时间是停滞等待内存访问,那更快的执行实际上并不能提高CPU指令的执行效能或者负载吞吐量
指令
CPU执行指令集中的指令,一个指令包括以下步骤,每个都有CPU的一个叫做功能单元的组建处理:
- 指令预取
- 指令解码
- 执行
- 内存访问
- 寄存器写回
4、5是可选,这里每一步都至少需要一个时钟周期来执行。内存访问经常是最慢的,因为它通常需要几十个时钟周期读或写主存,在此期间指令陷入停滞(停滞期间的这些周期称为停滞周期)。
指令流水线
一条指令中的多个步骤分别由不同功能单元执行,在避免一些冲突性的步骤时(如I/O操作等),同时执行多条指令的某一个步骤,从而提高了指令执行吞吐量。
指令宽度
同一种类型的功能单元可以有多个,这样每个时钟周期里就可以处理更多指令。这种CPU架构被称为超标量,通常和指令流水心一起使用以达到高指令吞吐量。
指令宽度描述了同时处理的目标指令数量。现代处理器一般为宽度3或者4,意味着它们可以在每个周期里最多完成3~4个指令。
使用率
测量一段时间内CPU实例忙于执行工作时间比例;也可以通过测量CPU未运行内核空闲线程的时间得出,这段时间内CPu可能忙于一些用户态应用程序线程,或者其他内核线程,或者在处理中断。
高CPU使用率不一定代表着问题,仅仅表示系统正在工作。高度利用的系统被认为有着较好的ROI,而空闲的系统则是浪费,和其他类型的资源(磁盘)不同,在高使用率的情况下,性能并不会出现显著下降,因为内核支持了优先级、抢占和分时共享。这些概念加起来让内核决定了什么线程优先级更高,并保证它优先运行。
CPU使用率的测量包括了所有符合条件活动的时钟周期,包括内存停滞周期,因此CPU会经常停滞等待I/O而导致高使用率,而不仅仅是在执行指令。
用户时间/内核时间
内核时间包括系统调用、内核线程和中断的时间。在整个系统范围内进行测量是,用户时间和内核时间之比揭示了运行的负载类型。
计算密集的应用程序几乎会把大量的时间用在用户态代码上,用户/内核时间之比接近99/1,比如图像处理、基因组学和数据分析
I/O密集的应用程序的系统调用频率较高,通过执行内核代码进行I/O操作。比如进行网络I/O的web服务的用户/内核时间比大约为70/30
饱和度
一个100%使用率的CPU被称为是饱和的,线程在这种情况下会碰上调度器延时,因为他们需要等待才能在CPU上运行,降低了总体性能。这个延时是线程花在等待CPU运行队列或者其他管理线程的数据结构上的时间。
另一个CPU饱和度的形式则和CPU资源控制有关,这个控制会在云计算环境下发生。尽管CPU并没有100%的被使用,但已经达到了控制的上限,因此可运行的线程就必须等待轮到他们的机会。
因为更高优先级的工作可以抢占当前线程,所有一个饱和运行的CPU的影响不会像其他资源那样严重。
空闲线程
内核“空闲”线程(或者空闲任务)只在没有其他可运行线程的时候才在CPU上运行,并且优先级经尽可能地低。通常被设计为通知处理器CPU执行停止(停止指令)或者减速以节省资源,CPU会在下一次硬件中断醒来。
工具法分析CPU
| 命令工具(注意区分系统) | 描述 |
|---|---|
| uptime | 检查负载平均数以确认CPU负载是随时间上升还是下降;负载平均数超过了CPU数量通常代表CPU饱和 |
| vmstat | 每秒运行vmstat检查空闲列,看看还有多少余量,少于10%可能是个问题 |
| mpstat | 检查单个热点(繁忙)CPU,跳出一个可能的线程扩展性问题 |
| top/prstat | 看看哪个进程和用户是CPU消耗大户 |
| perf/dtrace/stap/oprofile | 从用户时间或者内核时间的角度剖析CPU使用的堆栈跟踪,以了解为什么使用这么多CPU |
| perf/cpustat | 测量CPI |
原本是为了了解一下相关的方法论,但实在是没能看下去,此处就略去原书中介绍的一些方法论
实验
把书中的实验列一下,能动手敲一下还是要直观多了。
- 模拟单线程的CPU密集型负载:
#while 循环制造负载
while :; do :; done
#可另开终端观测 1s 统计一次
mpstat -P ALL 1
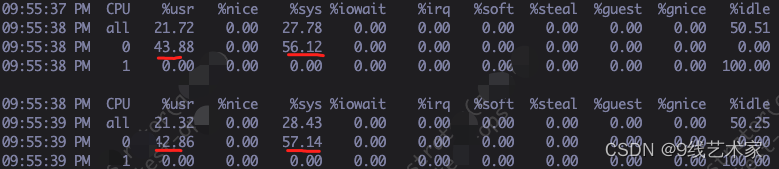 可以看到是在0号CPU上运行,用户态和内核态占比在4/6.
可以看到是在0号CPU上运行,用户态和内核态占比在4/6.
- sysbench
#先快速安装一下
yum install sysbench
#脚本
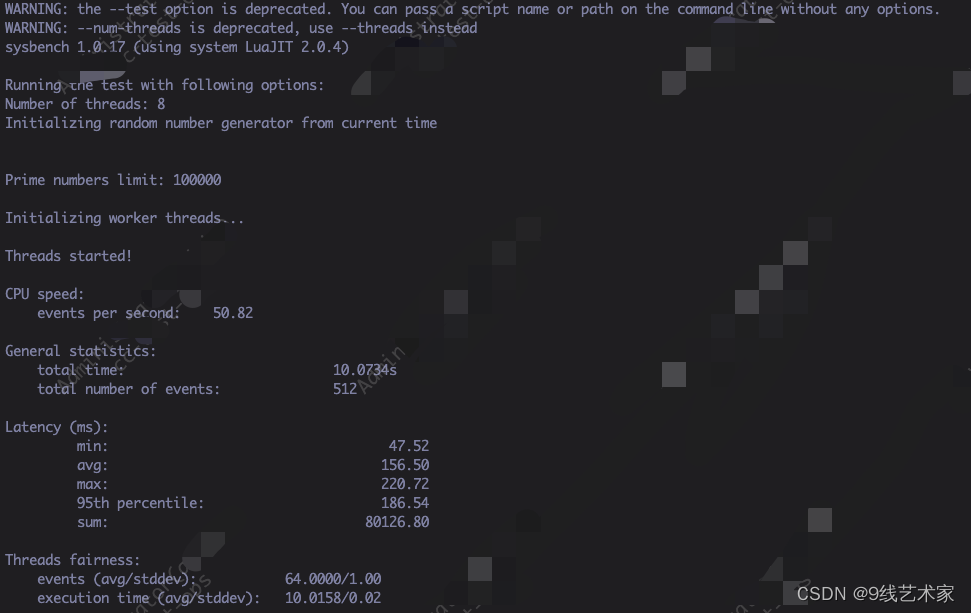
sysbench --num-threads=8 --test=cpu --cpu-max-prime=100000 run
#上述脚本会有几个提示,按提示改了一下
sysbench --threads=8 cpu --cpu-max-prime=100000 run
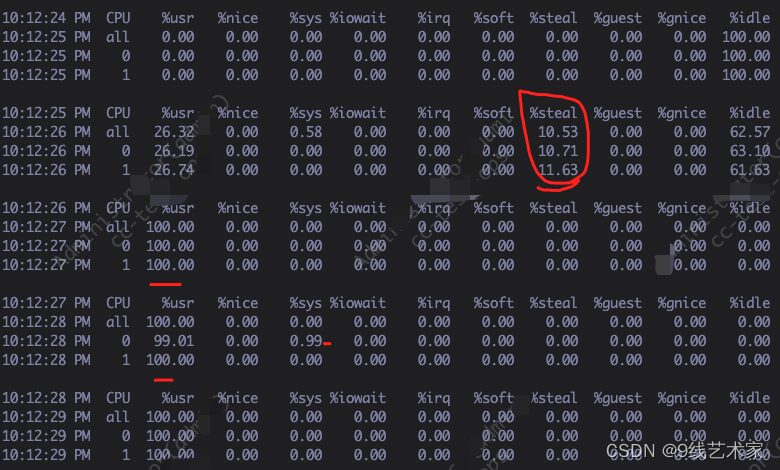
监控截图,aws的云服务,这个steal是别的租户抢占了物理CPU的资源了吗?
这个的耗时全在用户态















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









