







场景
产品基于Django rest framework、Mysql开发。随着产品发展,部分模型数据量日益增涨,每月达到千万级数据,严重影响性能。
这里以项目实际场景中的Order(订单表)来展开
需求:
1、基本查询,查看历史订单。
2、看板输出,查看每天销售情况,计算订单表中的金额、成本、毛利等字段。
方案分析
性能下降一方面是数据量过大,另一方面是该表承担着频繁的计算请求。以Django对Order(订单表)金额字段计算为例
result = models.Order.objects.filter(pk='test',time__gte='2022-01-01').aggregate(total_money=SUM('money'))
数据库中实际执行的sql
SELECT SUM(money) From Order where pk='test' AND time>='2022-01-01';
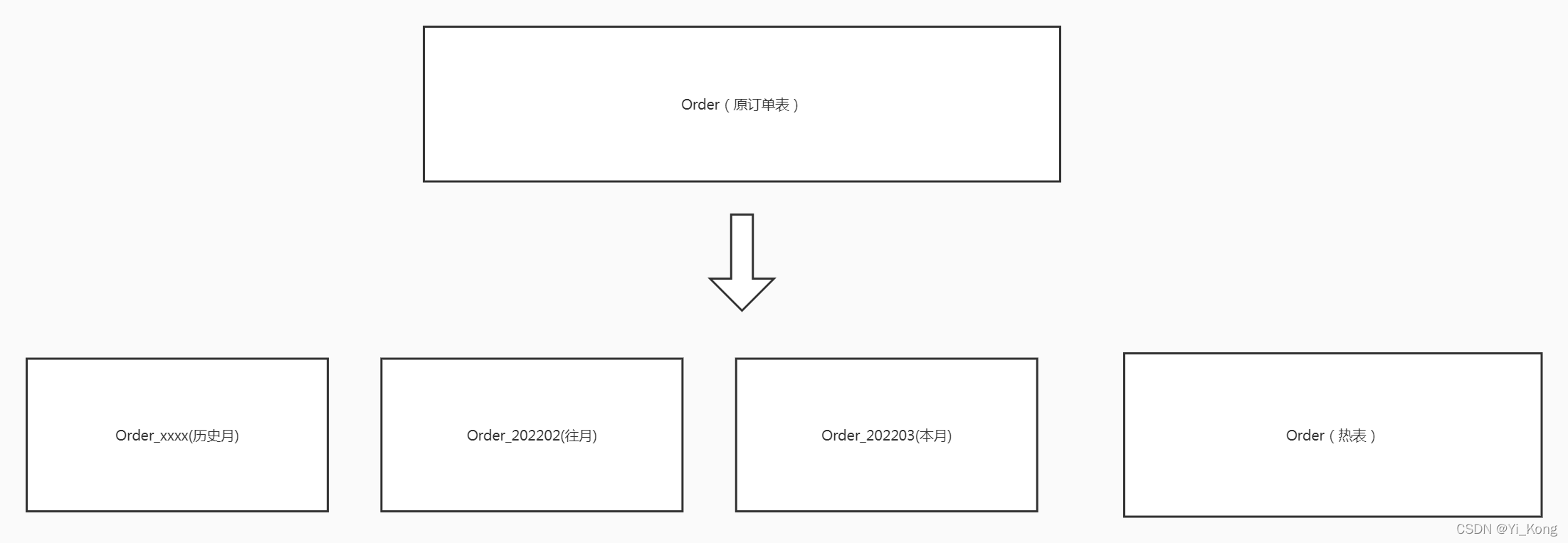
即时有索引,每次从磁盘读取的数据依然很大,而且随着数据量的增长,每次读取的数据会越来越大。但是用于计算的只是符合时间要求的一小部分,所以采取冷热分离的思路。冷表存储基本查询的数据,热表存储经常计算的数据。
根据业务量,这里的订单表按时间月份来划分。热表只存当天、昨天的数据。因为昨天数据用于晚上的定时任务计算产出报表,当天数据用于看板实时计算。这里一天平均的数据量大概50w左右,存两天就100w出头的数据。至于以后业务量会不会发展到一天500w数据,是很遥远的事情。就先不考虑了
项目改动
1、数据迁移
这里的案例是热表只存两天数据,也就是说每天凌晨0点就要迁移前一天的数据到冷表。
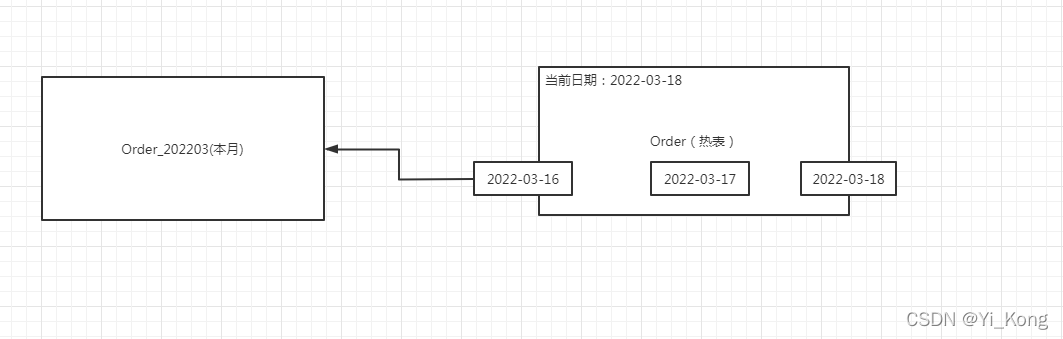
当03-18日0点到来的时候,03-16的数据会迁移到冷表中。
实现:
配置Crontab 任务,每天0点执行。本次实践中,一百万数据左右,3分钟不到就执行完了。
table_name_date=$(date "+%Y%m") # 数据导入的月份表
month_table=$(date "+%Y%m") # 月份表
run_date=$(date "+%Y%m%d") # 脚本执行日期
this_month_first_day=$(date "+%Y%m01") # 本月第一天 2022-04-01
this_month_second_day=$(date "+%Y%m02") # 本月第二天 2022-04-02
# 脚本执行日期 = 本月第一\二天,月份表为上月
if [ "$run_date" = "$this_month_second_day" ] || [ "$run_date" = "$this_month_first_day" ];then
table_name_date=$(date -d "last month" +%Y%m)
fi
# 登录数据库
mysql -u root -proot <<EOF # 这里必须是root账号
use test_databases;
# 建表
CREATE TABLE IF NOT EXISTS order_$month_table LIKE order;
# 从热表迁移前天的数据
SELECT * FROM order WHERE Time < DATE_SUB(CURDATE(),INTERVAL 1 DAY) INTO OUTFILE 'order_daily_transfrom_$run_date';
# 导入数据到冷表
LOAD DATA INFILE 'order_daily_transfrom_$run_date' REPLACE INTO TABLE order_$table_name_date;
# 从热表中删除旧数据
DELETE FROM order WHERE Time < DATE_SUB(CURDATE(),INTERVAL 1 DAY);
EOF
2、项目代码修改
上面提到的两个需求中,查看历史订单是需要看到所有的订单。但是原来接口是DRF基于单表提供的。
class OrderViewSet(ViewSet):
serializer_class = serializers.OrderSerializer
queryset = models.Order.objects.filter()
permission_classes = (permissions.LoginRequire,)
authentication_classes = (authentications.TokenAuthentication,)
filter_backends = (DjangoFilterBackend, SearchFilter, OrderingFilter)
历史数据拆到冷表后,就需要对代码做出调整。其中包括:Models类,list(),get_queryset()。
Model:
class Order(models.Model):
"""
原----订单模型
"""
id = models.CharField(db_column='Id', primary_key=True,max_length=50, editable=False)
time = models.DateTimeField(verbose_name='时间', db_column='Time')
# 省略部分字段
class Meta:
verbose_name = '订单'
verbose_name_plural = verbose_name
db_table = 'order'
# 补充模型
class HistoryOrder(models.Model):
"""
冷表----订单模型
"""
id = models.CharField(db_column='Id', primary_key=True,max_length=50, editable=False)
time = models.DateTimeField(verbose_name='时间', db_column='Time')
# 省略部分字段
class Meta:
abstract = True
verbose_name = '订单'
verbose_name_plural = verbose_name
db_table = 'order'
@classmethod
def get_table_name(cls, suffix):
# 修改表后缀,默认是当月order_202203
table_name = 'order_%s' % suffix if suffix else 'order_%s' % datetime.strftime(datetime.now(), "%Y%m")
return table_name
@classmethod
def sharding_get(cls, name=None):
# 获取model实例
new_cls = cls.get_table_model(name)
return new_cls
_table_model = {}
@classmethod
def get_table_model(cls, suffix: str):
"""
创建模型
"""
# 要连接的数据表,
table_name = cls.get_table_name(suffix)
if table_name in cls._table_model:
return cls._table_model[table_name]
# 这里会重新设置创建的model的名字,每个model名字都是动态的,不是BaseTable
class Metaclass(models.base.ModelBase):
def __new__(cls, name, bases, attrs):
name = name + '_%s' % suffix # 这是Model的name.
return models.base.ModelBase.__new__(cls, name, bases, attrs)
# 注意继承的顺序
class NewOrder(HistoryOrder, metaclass=Metaclass):
class Meta:
db_table = table_name
NewOrder._meta.db_table = table_name
cls._table_model[table_name] = NewOrder
return NewOrder
Viewset:
class OrderViewSet(ViewSet):
serializer_class = serializers.OrderSerializer
queryset = models.Order.objects.filter()
permission_classes = (permissions.LoginRequire,)
authentication_classes = (authentications.TokenAuthentication,)
filter_backends = (MyFilterBackend, SearchFilter, OrderingFilter)
def list(self, request, *args, **kwargs):
date = self.request.GET.get('date', '') # 以往月份数据需要按请求参数拼接
queryset = self.filter_queryset(self.get_queryset()) # 原order表对应的queryset
if not date or date == datetime.strftime(datetime.now(), "%Y%m"): # 默认返回本月数据
history_queryset = models.HistoryOrder.sharding_get().objects.filter(pk=pk)
history = self.filter_queryset(history_queryset) # 筛选
# 以当前时间为例,拼接order_202203 union order
queryset = queryset.union(history).order_by('-create_time')
if date and date != datetime.strftime(datetime.now(), '%Y%m'):
#2022
history_queryset = models.HistoryOrder.sharding_get(date ).objects.filter(pk=pk)
queryset = self.filter_queryset(queryset) # 筛选
page = self.paginate_queryset(queryset) # 分页处理
# your code
return
def get_quertset(self):
# 按需修改
# your code
return
DRF的进一步封装,提高了开发效率,但是自定义开发的灵活性也相对受到限制。
这里需要注意一个地方,就是 filter_backends =(DjangoFilterBackend, SearchFilter, OrderingFilter),DjangoFilterBackend中有个代码片段,判断queryset和filter_queryset采用的模型是否为另一个的子类
if filterset_class:
# filterset_model = filterset_class._meta.model
# FilterSets do not need to specify a Meta class
# if filterset_model and queryset is not None:
# assert issubclass(queryset.model, filterset_model), \
# 'FilterSet model %s does not match queryset model %s' % \
# (filterset_model, queryset.model)
return filterset_class
这里的处理是重写DjangoFilterBackend为MyFilterBackend,把这部分代码注释掉。这里要保证模型中冷表和热表的两个模型字段是一样的。
目前这么处理没发现会有什么问题,也不影响正常的业务数据请求。














 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









