









什么是hive
首先要学习Hive,第一步是了解Hive,Hive是基于Hadoop的一个数据仓库,可以将结构化的数据文件映射为一张表,并提供类sql查询功能,Hive底层将sql语句转化为mapreduce任务运行。相对于用java代码编写mapreduce来说,Hive的优势明显:快速开发,人员成本低,可扩展性(自由扩展集群规模),延展性(支持自定义函数)。
Hive的构架:
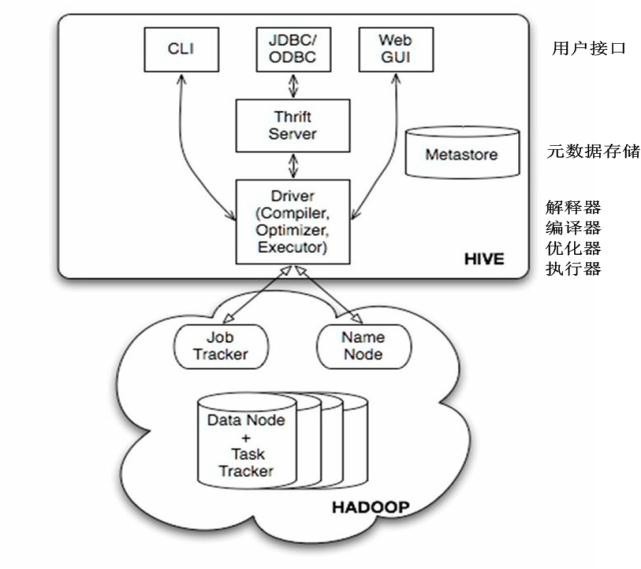
Hive提供了三种用户接口:CLI、HWI和客户端。客户端是使用JDBC驱动通过thrift,远程操作Hive。HWI即提供Web界面远程访问Hive。但是最常见的使用方式还是使用CLI方式。(在linux终端操作Hive)
Hive安装
可以从Apache官网下载安装文件,即 http://mirror.bit.edu.cn/apache/hive/
解压包到指定目录下
tar -zxvf apache-hive-1.2.1-bin.tar.gzhive配置
1、在mysql上创建hive元数据库,创建hive账号,并进行授权
mysql> grant all on *.* to hive@'%' identified by 'hive';
mysql> flush privileges; //刷新权限all代表接受所有操作,比如 select,insert,delete....; *.* 代表所有库下面的所有表;% 代表这个用户允许从任何地方登录;为了安全期间,这个%可以替换为你允许的ip地址;第一个hive是用户,第二个hive是密码。
2、添加hive目录下的/conf/hive-site.xml文件,配置如下:
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
</configuration>3、复制mysql驱动程序到hive的lib目录下
cp mysql-connector-java-5.1.43-bin.jar apache-hive-1.2.1-bin/lib/4、配置环境变量(/etc/profile)
export HIVE_HOME=$PWD/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/binhive操作
hive中的数据类型
原子数据类型:TINYINT SMALLINT INT BIGINT FLOAT DOUBLE BOOLEAN STRING
复杂数据类型:STRUCT MAP ARRAY
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE 观察可发现一共有三种建表方式,接下来我们将一一讲解。
1.直接建表法:
create table table_name(col_name data_type);
row format
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
Hive将HDFS上的文件映射成表结构,通过分隔符来区分列(比如’,’ ‘;’ or ‘^’ 等),row format就是用于指定序列化和反序列化的规则。比如对于以下记录:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
逗号用于分割列,即FIELDS TERMINATED BY ',',分割为如下列 ID、name、hobby(该字段是数组形式,通过 ‘-’ 进行分割,即COLLECTION ITEMS TERMINATED BY ‘-’)、address(该字段是键值对形式map,通过 ‘:’ 分割键值,即 MAP KEYS TERMINATED BY ‘:’);而LINES TERMINATED BY char用于区分不同条的数据,默认是换行符;
根据上面文件,创建一个表t1
create table t1(
id int
,name string
,hobby array<string>
,add map<String,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
stored as textfile; //指定文件的存储格式为textfile
分区表
在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的值不一定要基于表的某一列(字段),它可以指定任意值,只要查询的时候指定相应的分区键来查询即可。我们可以对分区进行添加、删除、重命名、清空等操作。因为分区在特定的区域(子目录)下检索数据,它作用同DNMS分区一样,都是为了减少扫描成本。
Hive(Inceptor)分区又分为单值分区、范围分区。单值分区又分为静态分区和动态分区。我们先看下分区长啥样。如下,假如有一张表名为persionrank表,记录每个人的评级,有id、name、score字段。我们便可以创建分区rank(注意rank不是表中的列,我们可以把它当做虚拟列),并将相应数据导入指定分区(将数据插入指定目录)。

1、单值分区
单值分区根据插入时是否需要手动指定分区可以分为:单值静态分区:导入数据时需要手动指定分区。单值动态分区:导入数据时,系统可以动态判断目标分区。
单值分区表的建表方式有两种:直接定义列和 CREATE TABLE LIKE。注意,单值分区表不能用 CREATE
TABLE AS SELECT 建表。而范围分区表只能通过直接定义列来建表。
1)静态分区创建(分区键的值不一定要基于表的某一列(字段))
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type> [, <col_name> <data_type> ...])
-- 指定分区键和数据类型
PARTITIONED BY (<partition_key> <data_type>, ...)
[CLUSTERED BY ...]
[ROW FORMAT <row_format>]
[STORED AS TEXTFILE|ORC|CSVFILE]
[LOCATION '<file_path>']
[TBLPROPERTIES ('<property_name>'='<property_value>', ...)];例如:
create table t1(
id int
,name string
,hobby array<string>
,add map<String,string>
)
partitioned by (pt_d string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;如果分区字段和表中字段相同的话,会报错,如下:
create table t1(
id int
,name string
,hobby array<string>
,add map<String,string>
)
partitioned by (id int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;
报错信息:FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns
2、写入数据
-- 覆盖写入
INSERT OVERWRITE TABLE <table_name>
PARTITION (<partition_key>=<partition_value>[, <partition_key>=<partition_value>, ...])
SELECT <select_statement>;
-- 追加写入
INSERT INTO TABLE <table_name>
PARTITION (<partition_key>=<partition_value>[, <partition_key>=<partition_value>, ...])
SELECT <select_statement>;
--加载数据
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [(<partition_key>=<partition_value>[, <partition_key>=<partition_value>, ...])]
举例:
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1 partition ( pt_d = '201701');














 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









