







1、外部表和内部表
Hive 表分为两类,即内部表和外部表。 所谓内部表,即Hive 管理的表, Hive 内部表的管理既包含逻辑以及语法上的,也包含实际物理意义上的,即创建 Hive 内部表时,数据将真实存在于表所在的目录内,删除内部表时,物理数据和文件也一并删除。 外部表 ( external table)则不然,其管理仅仅是在逻辑和语法意义上的,即新建表仅仅是指向一个外部目录而已。 同样,删除时也并不物理删除外部目录,而仅仅是将引用和定义 删除。 外部表,指定 EXTERNAL 关键字后,因而不会把数据移动到 warehouse 目录中。 事实上,Hive甚至不会校验外部表的目录是否存在。 这使得我们可以在创建表之后再创建数据。 当删除外部表时, Hive只删除元数据,而不会删除外部实际物理文件。
2、内部表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量 的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
3、分区表和分桶表
主要是在hive中没有索引的功能,想要快速查找,所以就出现了分区表和分桶表。常见的分区表是用日期来做分区,不同日期的数据放在同一个文件。还可以做二级分区,比如一级分区是按日期分,二级分区是按照国家分。这样做的话就是方便写sql提高速度。

分桶表是更细的颗粒度,可以把一张表分成几个部分,但是这有个问题是会造成小文件太多。比如分桶表可以把一张订单表根据id分成4个桶,分桶时, Hive 根据字段id哈希后取余数来决定数据应该放在哪个桶,因此每个桶都是整体数据的随机抽样。 由于id是不重复的,所以数据会被分配到4个部分。好处是有联表操作时候,两个表根据相同的宇段进行分桶,处理左边表的 bucket 时,可以直接从外表对应的 bucket 中提取数据进行关联操作。
4、hive底层执行mapreduce时,map和reduce启动的任务数
map启动的任务数量是由文件分块决定的,hadoop2.x中最小的分块是128m,如果一个文件300m,那么会分成3块,128m,128m,44m。会启动3个map任务。
reduce任务数可以设置。
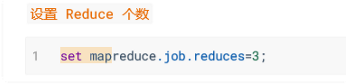
5、mapreduce阶段分配到reduce的过程
Hadoop 中最为 常用的分区方法是 Hash Partitioner,即 Hadoop 会对每个键取hash值,然后再对此 hash 值按照 reduce 任务数目取模,从而得到对应的 reducer,这样保证相同的键,肯定被分配到同一个reducr 上,同时hash函数也能确保Map任务的输出被均匀地分配到所有的 Reduce 任 务上。
6、小表join大表
join 时大表放在最后。 这是因为每次 Map/Reduce 任务的逻辑是这样的 : Reduce 会 缓存join 序列中除最后一个表之外的所有表的记录,再通过最后一个表将结果序列化到文 件系统,因此实践中,应该把最大的那个表写在最后。
7、having语句

8、局部排序

9、分区排序

10、hive参数设置
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在Session建立以前已经完成了。
参数声明 > 命令行参数 > 配置文件参数(hive)















 2228
2228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









