







首次真正意义上的完成一个爬虫实战项目,学到了很对小技巧,也巩固了前期学习的内容。在此仅作记录与分享。下一步打算将代码升级为多线程版本,如果大家有更好的思路,希望可以进一步讨论。
目标网址:https://desk.zol.com.cn/fengjing/yejing/
他长这个样子:
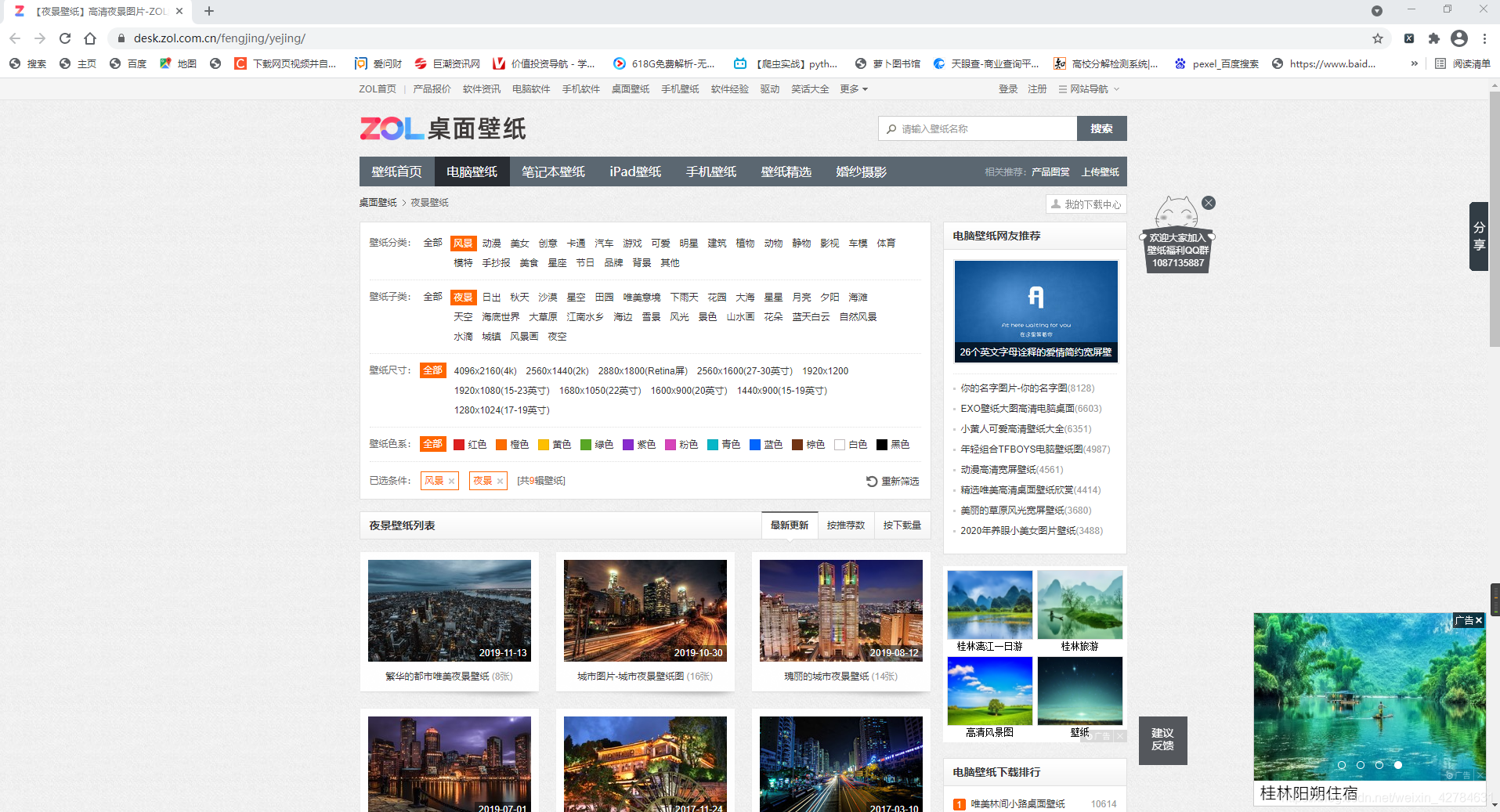
我想把 风景-夜景 下面的9组图片爬取下来。观察网页可以发现,每一组图片里面都有好多张图片,
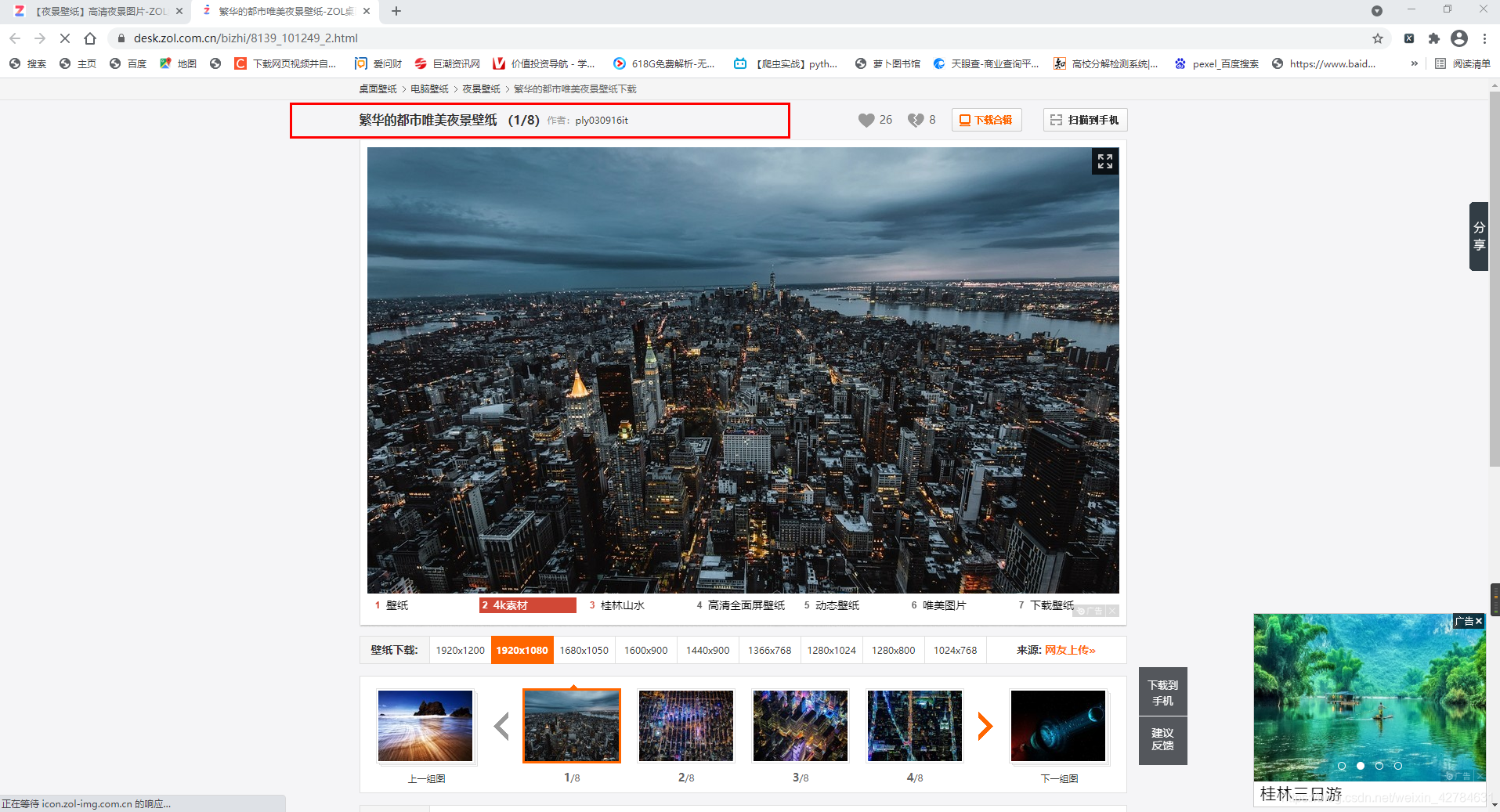
我要以每组图片系列的名字命名文件夹,把这一组图片爬到他名字下面的文件夹中,就像这样
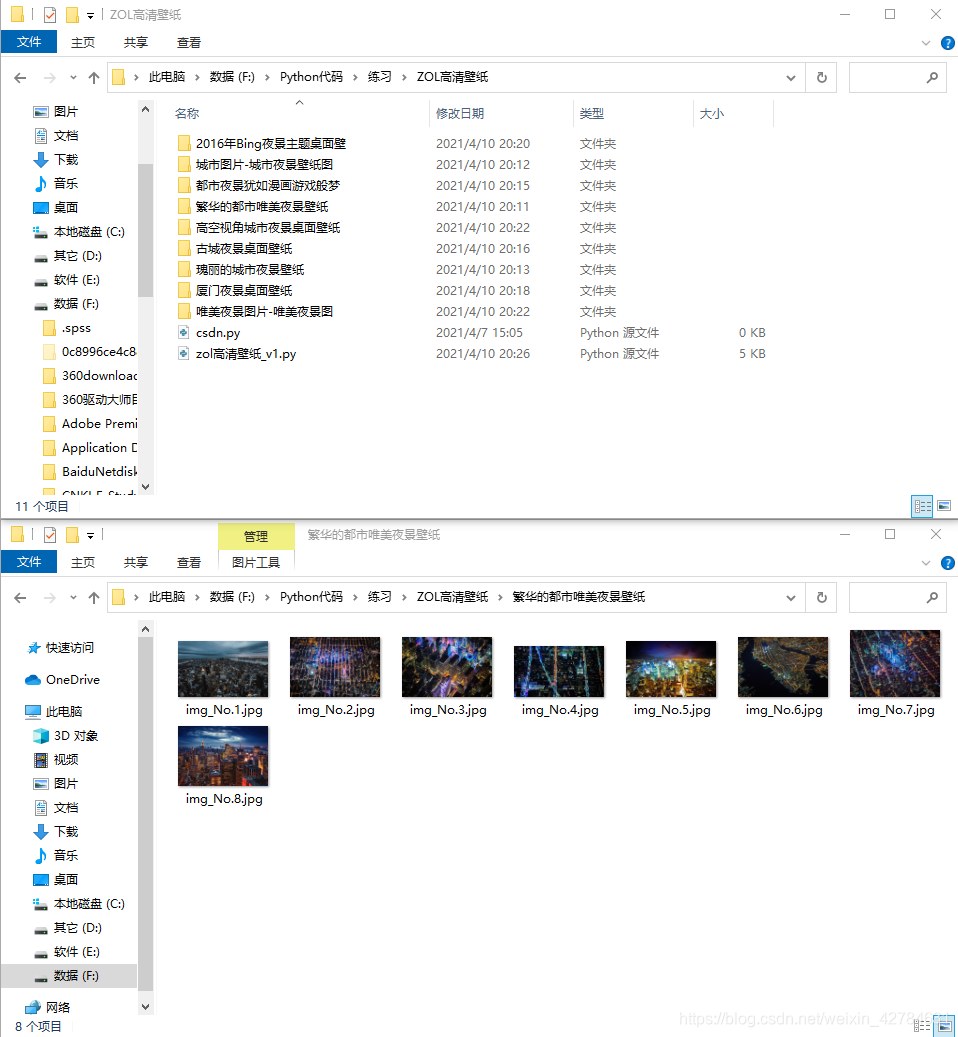
目标有了,下面开始整理思路
思路:
要以每组图片的名字命名创建文件夹,可以从能看见所有图组名字的地方找。
要爬取所有图片,那么就要进入每组图片的界面去找每张图片的真实地址。
那么,
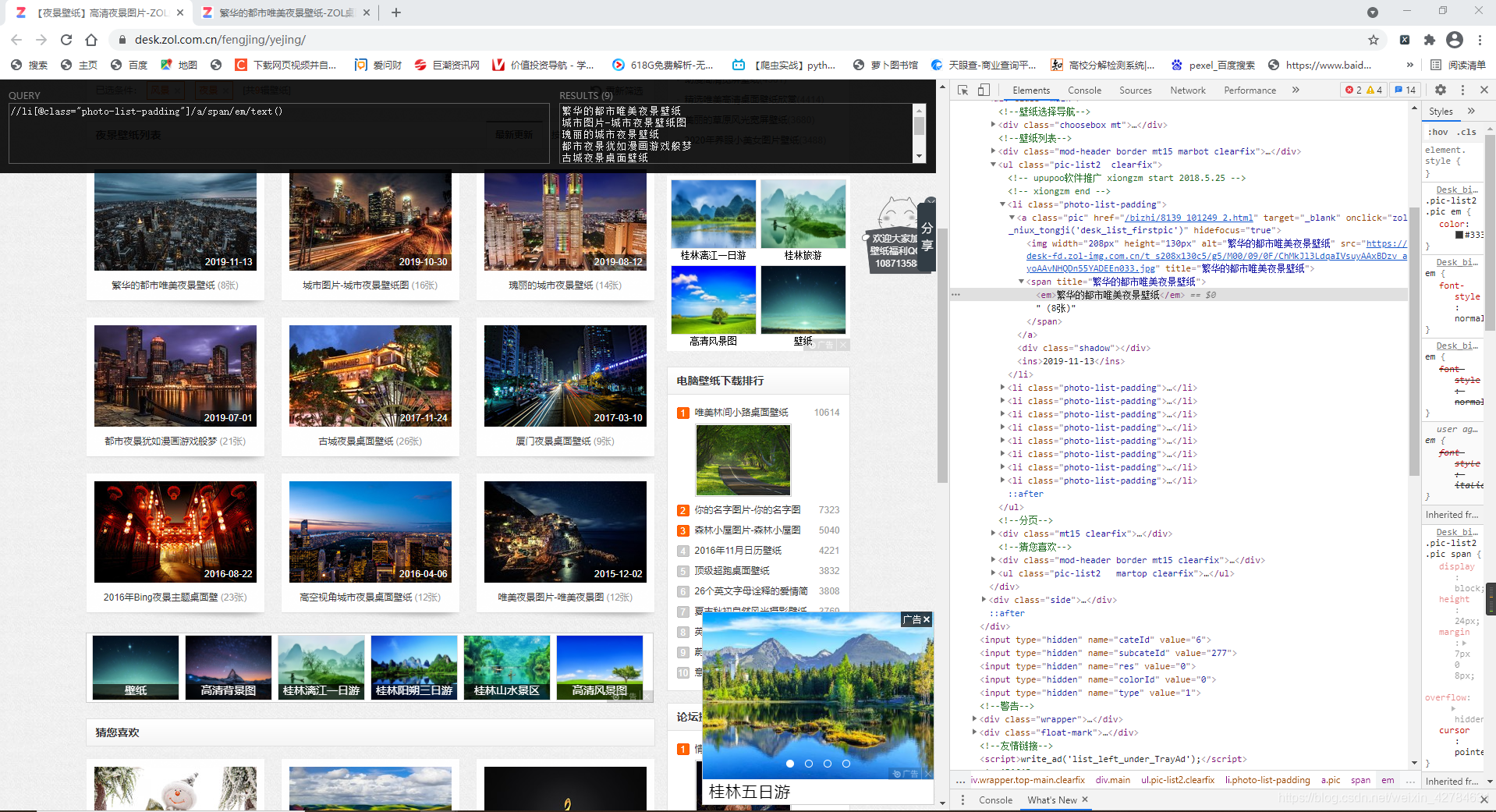
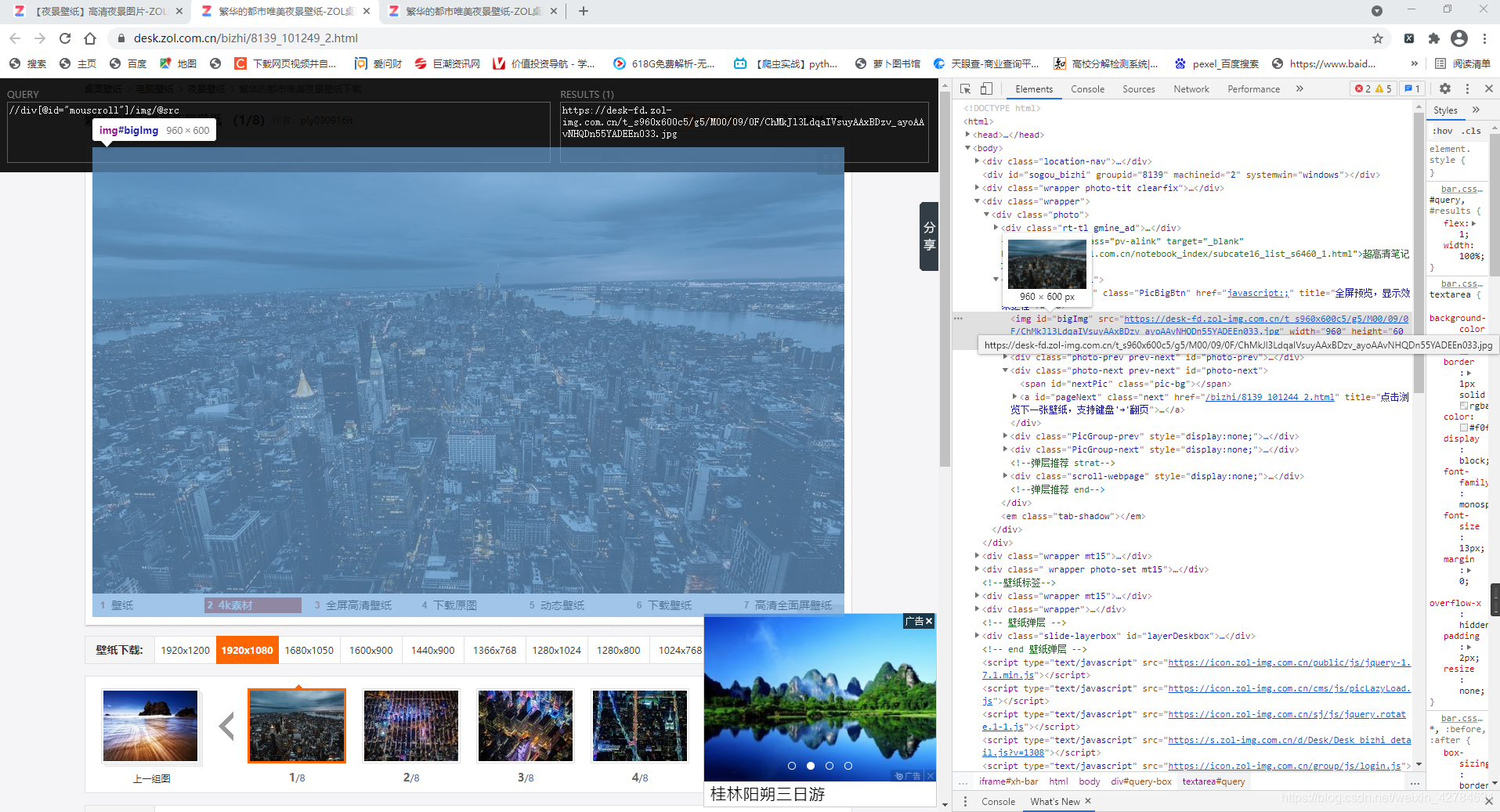
名字name在这里找,xpath为‘//li[@class=“photo-list-padding”]/a/span/em/text()’
真实图片地址在这里,xpath为‘//div[@id=“mouscroll”]/img/@src’
不过我要的是1920x1080的大图,这个网址出来的图片是960x600,想得到1920x1080的大图,我试着将图片网址里面的 t_s960x600c5 这个参数替换成 t_s1920x1080 发现得到的就是想要的大图,所以增加一个替换内容,即
adress = html_1.xpath('//div[@id="mouscroll"]/img/@src')[0].replace('t_s960x600c5','t_s1920x1080')
原材料都找到了,可以开始了
一、调用需要的库
设置请求头,使用代理(设置代理只是为了巩固前期所学,这里好像没必要,网站的反爬措施没那么严)
from lxml import etree
import requests
import os
import threading
import queue
from urllib import parse
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie':'HMACCOUNT_BFESS=5A76C20AA8660D57; BDUSS_BFESS=UwZTVlQ0oxdTNNcVRiUUp3YkZ2YlpTWEtMN2tNSFpFeWdRUlRjRDlxZTBobDFmRVFBQUFBJCQAAAAAAAAAAAEAAAD8Ar-O70yDuv2XAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALT5NV-0-TVfYj; BDSFRCVID_BFESS=dPCOJeC62xqMEQoeDjW8TGYSv07fn5jTH6aocB2aoVUNToy-YSWMEG0PDM8g0Kubo25nogKKBeOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR-JoDDMJDL3qPTuKITaKDCShUFsKpOmB2Q-5KL-MPjYsfjvbfO83Tk7Qnrg-j8f5D_tBfbdJJjoHp_4-tn43fC7hpuLXlJUBmTxoUJgBCnJhhvG-4PKjtCebPRi3tQ9Qg-qahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHj8he5bP; BAIDUID_BFESS=7C613C37D1AFB222B605AA8CCBB44540:FG=1',
}
# 使用代理
proxy = {
'http':'113.194.143.101:9999'
}
二、获取夜景壁纸列表,返回每个图组的urls,通过这个urls进入每组图片系列。
这个函数用来返回所有图组名字name和所有图组链接urls_list
其中返回的图组链接只有一半,经过简单观察,可以得出完整的链接需要在前面拼接上 https://desk.zol.com.cn这段字符串,才能算是一个完整的链接,通过该链接,可以进入到每组图片里面。
def yejing_pic_list(base_url):
res = requests.get(base_url,proxies=proxy,headers=headers).content.decode('gbk')
html = etree.HTML(res)
Incomplete_url = html.xpath('//li[@class="photo-list-padding"]/a/@href') # 返回的是['/bizhi/8139_101249_2.html', '/bizhi/7947_98766_2.html', '/bizhi/7741_96199_2.html', '/bizhi/7568_93902_2.html', '/bizhi/7203_89142_2.html', '/bizhi/7000_86950_2.html', '/bizhi/6704_83622_2.html', '/bizhi/6383_78552_2.html', '/bizhi/6062_75033_2.html']
s = 'https://desk.zol.com.cn'
global name
name = html.xpath('//li[@class="photo-list-padding"]/a/span/em/text()') # 返回的是['繁华的都市唯美夜景壁纸', '城市图片-城市夜景壁纸图', '瑰丽的城市夜景壁纸', '都市夜景犹如漫画游戏般梦', '古城夜景桌面壁纸', '厦门夜景桌面壁纸', '2016年Bing夜景主题桌面壁', '高空视角城市夜景桌面壁纸', '唯美夜景图片-唯美夜景图']
# 拼接url s+Incomplete_url
for i in range(len(Incomplete_url)):
Incomplete_url[i] = s + Incomplete_url[i]
urls_list = Incomplete_url # 返回的是['https://desk.zol.com.cn/bizhi/8139_101249_2.html', 'https://desk.zol.com.cn/bizhi/7947_98766_2.html', 'https://desk.zol.com.cn/bizhi/7741_96199_2.html', 'https://desk.zol.com.cn/bizhi/7568_93902_2.html', 'https://desk.zol.com.cn/bizhi/7203_89142_2.html', 'https://desk.zol.com.cn/bizhi/7000_86950_2.html', 'https://desk.zol.com.cn/bizhi/6704_83622_2.html', 'https://desk.zol.com.cn/bizhi/6383_78552_2.html', 'https://desk.zol.com.cn/bizhi/6062_75033_2.html']
return name,urls_list
三、返回每张图片的网页链接
需要通过urls_list进入每组图片系列中获取真实图片地址。但是这样一次只能爬取到四张图片的链接,即下面显示的这四张图片的链接,要拿到所有图片链接,应该有一个翻页的动作(就是点击一下右边那个箭头)。虽然在右边检查里面可以看到图组的所有地址链接(具体在图中所示的8个li标签里面)但是只能拿到前四张壁纸链接。
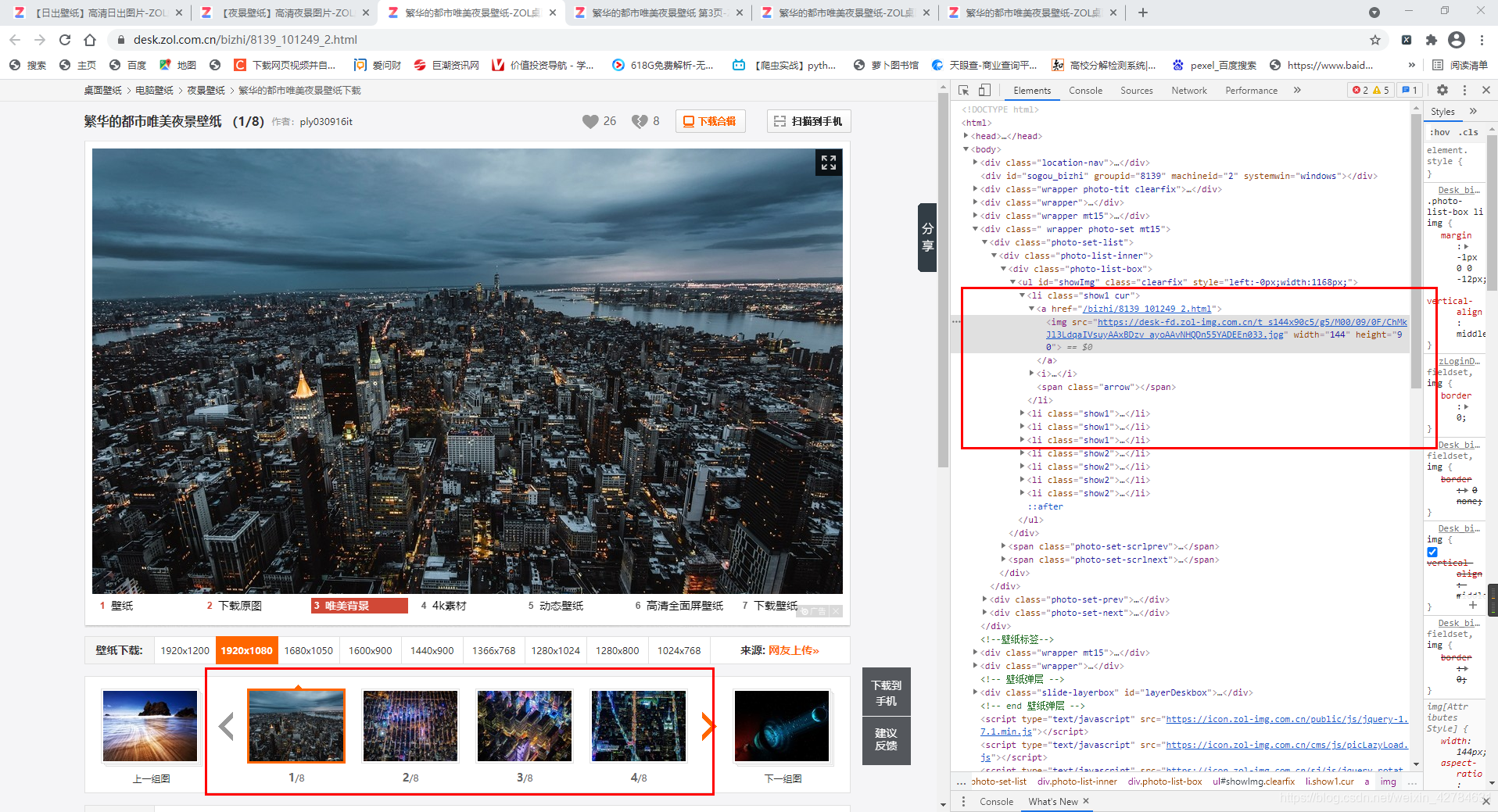
于是换了一种思路,每张图片都有一个网页链接,用这个网页链接再去请求,可以直接得到图片真实链接,像这种:https://desk.zol.com.cn/bizhi/8139_101249_2.html
所以用下面这个函数传入url_list参数后得到每张图片的网页链接返回值是list_1
# 返回每张图的网页链接
def secande(urls_list):
list_1 = []
for x in urls_list:
resp = requests.get(x,headers=headers).content.decode('gbk')
html = etree.HTML(resp)
links = html.xpath('//div[@class="photo-list-box"]/ul//li/a/@href')
s = 'https://desk.zol.com.cn'
url_links = [s+i for i in links]
list_1.append(url_links)
return list_1
-------------这里学到了用列表推导式去拼接网址链接字符串-----------------
links = html.xpath('//div[@class="photo-list-box"]/ul//li/a/@href')
s = 'https://desk.zol.com.cn'
url_links = [s+i for i in links]
四、返回每张图片的真实链接地址
# 返回每张图片的真实链接
def new_links(list_1):
url_111 = []
for i in list_1:
# print('='*220)
url_111_dict={}
for index,y in enumerate(i):
resp = requests.get(y,headers=headers).content.decode('gbk')
html_1 = etree.HTML(resp)
adress = html_1.xpath('//div[@id="mouscroll"]/img/@src')[0].replace('t_s960x600c5','t_s1920x1080')
url_111_dict[f'img_No.{index+1}']=adress
url_111.append(url_111_dict)
# print(url_111)
return url_111
这个地方卡了我好几天,在这里感谢csdn的老师和小伙伴们的热心帮助解答
遇到的问题:
这样for循环两次后面url_111_dict这个字典打印一直错误,不是我想要的,后来发现是return缩进错误,纠正后,在return前面尝试打印,结果是我想要的,但是其他函数调用return返回值url_111_dict这个字典,却是空的。经过几经波折之后终于弄清楚了原因。于是在最开始初始化一个空列表url_111用来放入循环后的字典,这样循环出来的所有字典被放入列表中,终于可以被其他函数调用了。。。
五、下载数据并存储到本地,设置主函数
# 下载数据并存储到本地
def donwlond(name,url_111):
for n,u in zip(name,url_111):
print(n,u)
path = os.path.join('zol高清壁纸',n)
if not os.path.exists(path):
os.mkdir(path)
for img_links in u.items():
index,img_links = img_links
with open(os.path.join(path, f'{index}.jpg'),'wb') as fp:
fp.write(requests.get(img_links,headers=headers).content)
def main():
base_url = 'https://desk.zol.com.cn/fengjing/richu/'
name,urls_list = yejing_pic_list(base_url)
list_1 = secande(urls_list)
url_111 = new_links(list_1)
donwlond(name,url_111)
if __name__=='__main__':
main()
-------------------------------------------------同时遍历两个列表------------------------------------------------
for n,u in zip(name,url_111):
print(n,u)
-----------------------------------------------一个小经验-----------------------------------------------------------
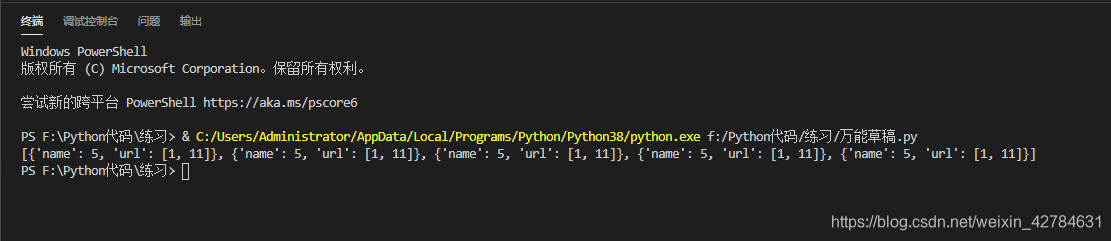
def dict(a,p):
dic_list = []
dic = {}
for i,j in zip(a,p):
dic['name']=i;dic['url']=j
dic_list.append(dic)
return dic_list
def main():
a = [1,2,3,4,5]
p = [[1,7],[1,8],[1,9],[1,10],[1,11]]
dic_list = dict(a,p)
print(dic_list)
if __name__=='__main__':
main()
打印结果:
最后附上完整代码
from lxml import etree
import requests
import os
import threading
import queue
from urllib import parse
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie':'HMACCOUNT_BFESS=5A76C20AA8660D57; BDUSS_BFESS=UwZTVlQ0oxdTNNcVRiUUp3YkZ2YlpTWEtMN2tNSFpFeWdRUlRjRDlxZTBobDFmRVFBQUFBJCQAAAAAAAAAAAEAAAD8Ar-O70yDuv2XAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALT5NV-0-TVfYj; BDSFRCVID_BFESS=dPCOJeC62xqMEQoeDjW8TGYSv07fn5jTH6aocB2aoVUNToy-YSWMEG0PDM8g0Kubo25nogKKBeOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR-JoDDMJDL3qPTuKITaKDCShUFsKpOmB2Q-5KL-MPjYsfjvbfO83Tk7Qnrg-j8f5D_tBfbdJJjoHp_4-tn43fC7hpuLXlJUBmTxoUJgBCnJhhvG-4PKjtCebPRi3tQ9Qg-qahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHj8he5bP; BAIDUID_BFESS=7C613C37D1AFB222B605AA8CCBB44540:FG=1',
}
# 使用代理
proxy = {
'http':'113.194.143.101:9999'
}
# 获取夜景壁纸列表,返回每个图组的urls
def yejing_pic_list(base_url):
res = requests.get(base_url,proxies=proxy,headers=headers).content.decode('gbk')
html = etree.HTML(res)
Incomplete_url = html.xpath('//li[@class="photo-list-padding"]/a/@href') # 返回的是['/bizhi/8139_101249_2.html', '/bizhi/7947_98766_2.html', '/bizhi/7741_96199_2.html', '/bizhi/7568_93902_2.html', '/bizhi/7203_89142_2.html', '/bizhi/7000_86950_2.html', '/bizhi/6704_83622_2.html', '/bizhi/6383_78552_2.html', '/bizhi/6062_75033_2.html']
s = 'https://desk.zol.com.cn'
global name
name = html.xpath('//li[@class="photo-list-padding"]/a/span/em/text()') # 返回的是['繁华的都市唯美夜景壁纸', '城市图片-城市夜景壁纸图', '瑰丽的城市夜景壁纸', '都市夜景犹如漫画游戏般梦', '古城夜景桌面壁纸', '厦门夜景桌面壁纸', '2016年Bing夜景主题桌面壁', '高空视角城市夜景桌面壁纸', '唯美夜景图片-唯美夜景图']
# 拼接url s+Incomplete_url
for i in range(len(Incomplete_url)):
Incomplete_url[i] = s + Incomplete_url[i]
urls_list = Incomplete_url # 返回的是['https://desk.zol.com.cn/bizhi/8139_101249_2.html', 'https://desk.zol.com.cn/bizhi/7947_98766_2.html', 'https://desk.zol.com.cn/bizhi/7741_96199_2.html', 'https://desk.zol.com.cn/bizhi/7568_93902_2.html', 'https://desk.zol.com.cn/bizhi/7203_89142_2.html', 'https://desk.zol.com.cn/bizhi/7000_86950_2.html', 'https://desk.zol.com.cn/bizhi/6704_83622_2.html', 'https://desk.zol.com.cn/bizhi/6383_78552_2.html', 'https://desk.zol.com.cn/bizhi/6062_75033_2.html']
return name,urls_list
# 返回每张图的网页链接
def secande(urls_list):
list_1 = []
for x in urls_list:
resp = requests.get(x,headers=headers).content.decode('gbk')
html = etree.HTML(resp)
links = html.xpath('//div[@class="photo-list-box"]/ul//li/a/@href')
s = 'https://desk.zol.com.cn'
url_links = [s+i for i in links]
list_1.append(url_links)
return list_1
# 返回每张图片的真实链接
def new_links(list_1):
url_111 = []
for i in list_1:
# print('='*220)
url_111_dict={}
for index,y in enumerate(i):
resp = requests.get(y,headers=headers).content.decode('gbk')
html_1 = etree.HTML(resp)
adress = html_1.xpath('//div[@id="mouscroll"]/img/@src')[0].replace('t_s960x600c5','t_s1920x1080')
url_111_dict[f'img_No.{index+1}']=adress
url_111.append(url_111_dict)
# print(url_111)
return url_111
def hebing(name,url_111):
for n,u in zip(name,url_111):
print(n,u)
path = os.path.join('zol高清壁纸',n)
if not os.path.exists(path):
os.mkdir(path)
for img_links in u.items():
index,img_links = img_links
with open(os.path.join(path, f'{index}.jpg'),'wb') as fp:
fp.write(requests.get(img_links,headers=headers).content)
def main():
base_url = 'https://desk.zol.com.cn/fengjing/yejing/'
name,urls_list = yejing_pic_list(base_url)
list_1 = secande(urls_list)
url_111 = new_links(list_1)
hebing(name,url_111)
if __name__=='__main__':
main()
通过改变基础url即base_url中的 /fengjing/yejing/ 可以完成整个zol网站壁纸的爬取,后面代码正在改进升级…
改进方向:
1.全站爬取
2.多线程爬取

















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









