







一、内容简介
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。但是我们在使用的过程中,需要将Json配置文件放到DataX的job路径下,随着业务的增加,配置文件不方便管理和迁移并且每次执行都需要记录命令。 下面介绍搭建基于DataX的可视化界面。
二、部署前准备
1、阿里的开源同步工具datax3.0
2、语言Java 8
3、数据库Mysql5.7
4、datax-web(项目地址:https://github.com/WeiYe-Jing/datax-web)
三、部署步骤
1、安装datax
下载datax
git cloune https://github.com/alibaba/DataX.git
编译datax,这里编译需要maven,安装不再累述
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
编译完成后,可以验证一下
cd DataX/target/datax/datax/bin
python datax.py …/job/job.json
2、安装jdk
yum install java-1.8.0-openjdk
3、安装数据库5.7
下载源
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
安装repo
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
安装mysql5.7
yum install mysql-server
4、安装datax-web
下载源码
git clone https://github.com/WeiYe-Jing/datax-web.git
执行sql
cd datax-web/doc/db,在mysql中执行datax_web.sql
修改datax-admin配置文件
vi datax-web/datax-admin/src/main/resources/application.yml

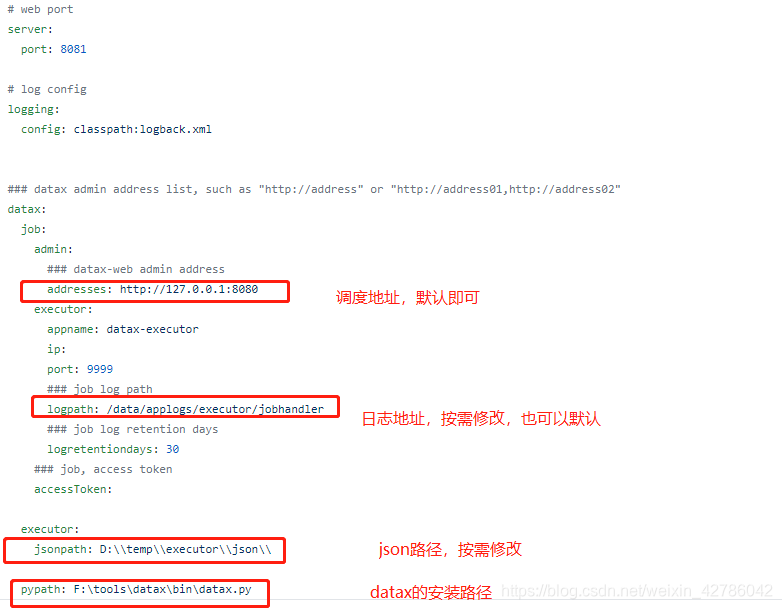
修改datax-executor配置文件
vi datax-executor/src/main/resources/application.yml
四、验证使用
启动datax-admin
java -Xmx1024M -Xms1024M -Xmn448M -XX:MaxMetaspaceSize=192M -XX:MetaspaceSize=192M -jar datax-admin-2.1.0.jar --server.port=8080 >> admin.log &
启动datax-executo
java -Xmx1024M -Xms1024M -Xmn448M -XX:MaxMetaspaceSize=192M -XX:MetaspaceSize=192M -jar datax-executor-2.1.0.jar >> executor.log &
检查端口是否起来
netstat -nuplt

可以看到已经成功启动,现在在浏览器输入地址查看
http://IP:8080/index.html#/dashboard
默认账号密码为admin/123456

















 2999
2999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









