






目录
Abstract
本文提出了一种用于动态环境中资源受限机器人的实时 RGB-D 惯性里程计系统,称为 Dynamic-VINS。三个主要线程并行运行:目标检测、特征跟踪和状态优化。
所提出的 Dynamic-VINS 结合了目标检测和深度信息以进行动态特征识别,并实现了与语义分割相当的性能。 Dynamic-VINS采用基于网格的特征检测,提出了一种快速高效的方法来提取高质量的FAST特征点。 IMU 用于预测运动以进行特征跟踪和运动一致性检查。所提出的方法在公共数据集和实际应用程序上进行了评估,并在动态环境中显示出具有竞争力的定位精度和稳健性。然而,据我们所知,它是目前动态环境中资源受限平台的最佳性能实时 RGB-D 惯性里程计。所提出的系统是开源的:https://github.com/HITSZ-NRSL/Dynamic-VINS.git
Introduction
本文的主要贡献如下:
- 提出了一种有效的基于优化的 RGB-D 惯性里程计,为动态和复杂环境中资源受限的机器人提供实时状态估计结果。
- 提出了轻量级的特征检测和跟踪以减轻计算负担。此外,提出了结合目标检测和深度信息的动态特征识别模块,以在复杂和室外环境中提供鲁棒的动态特征识别。
- 进行验证实验以显示所提出的系统在动态环境中资源受限平台上具有竞争力的准确性、鲁棒性和效率。
System Overview
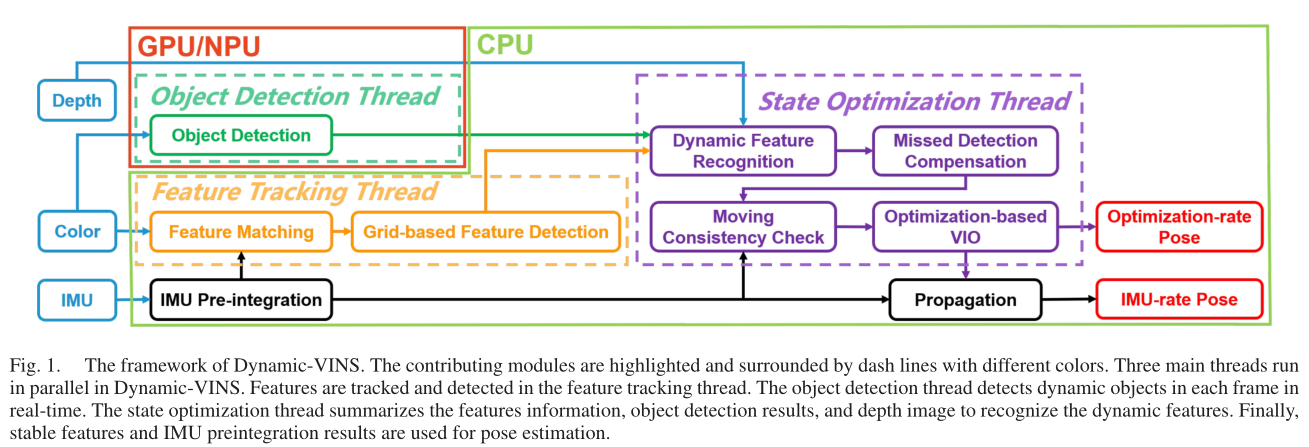
Methodology
本研究提出了轻量级、高质量的特征跟踪和检测方法来加速系统。从RGB-D 图像和 IMU 预积分提取的语义和几何信息被应用于动态特征识别和移动一致性检查。漏检补偿模块在漏检情况下对目标检测起到辅助作用。通过移动一致性检查进一步识别未知对象的动态特征。所提出的方法分为五个部分进行详细描述。
Feature Matching
特征跟踪使用KLT稀疏光流法。IMU测量用来预测特征的运动,更好的特征初始位置估计可以减少光流金字塔的层数,以此来提高特征跟踪的效率。而且通过这种方法,可以有效地丢弃不稳定的特征,例如噪声和运动不一致的动态特征。基本思想如下图所示:
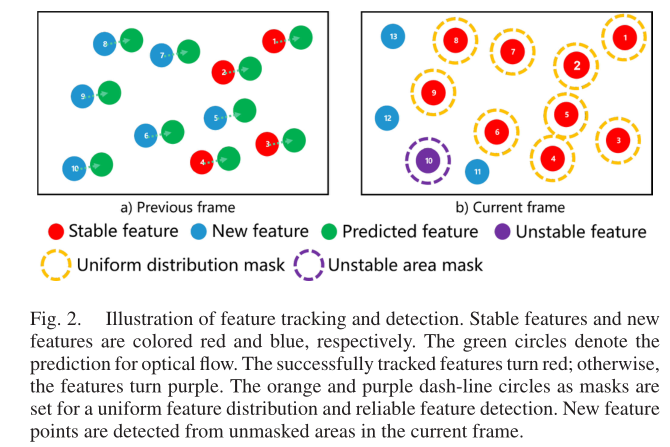
上述手段可以获得均匀分布的特征,捕捉综合约束,避免在模糊或纹理较弱的区域重复提取不稳定的特征。长期特征跟踪可以借助下面基于网格的特征检测来减少时间消耗。
Grid-Based Feature Detection
系统需要保持最少数量的特征以确保稳定性。因此,需要不断地从帧中提取特征点。本研究采用基于网格的特征检测。将图像划分为网格,填充每个网格的边界,防止网格边缘的特征被忽略;padding 使当前网格能够获取相邻像素信息以进行特征检测。与遍历整幅图像进行特征检测不同,只有特征匹配不足的格子才会进行特征检测。对于纹理弱而未能检测到特征的网格或者被掩码覆盖的网格将在下一个检测帧中被跳过,以避免重复的无用检测。线程池技术用于开发基于网格的特征检测的并行性能。因此,特征检测的时间消耗大大减少而没有损失。
FAST特征检测器可以有效地提取特征点,但很容易将噪声视为特征并提取相似的聚类特征。因此,结合上一节特征匹配中的mask和非极大值抑制的思想来选择高质量和均匀分布的FAST特征。
Dynamic Feature Recognition
通过上述改进,大部分特征点可以稳定跟踪。然而,动态对象的长期跟踪特征总是伴随着异常运动并且对系统引入错误的约束。为了提高效率和降低计算成本,采用了一种实时单级目标检测方法YOLOv3对人、车等多种动态场景元素进行检测。如果检测到的边界框覆盖了图像的较大区域,盲目删除边界框中的特征点可能会导致没有可用的特征来提供约束。因此,类语义分割掩码有助于跟踪不被动态对象遮挡的特征,从而维持系统的运行。
本文将目标检测与深度信息相结合,实现高效的动态特征识别,达到与语义分割相当的性能。深度相机测得越远,精度就越差。这一问题使得一些充分利用深度信息的方法,如Seed Filling、DBSCAN、K-Means等,在精度较低的深度摄像机下表现不佳,如图5(a)所示。通过将检测到的bounding box中的一组点与深度信息进行集成,可以得到与语义分割相当的性能,如图3所示。
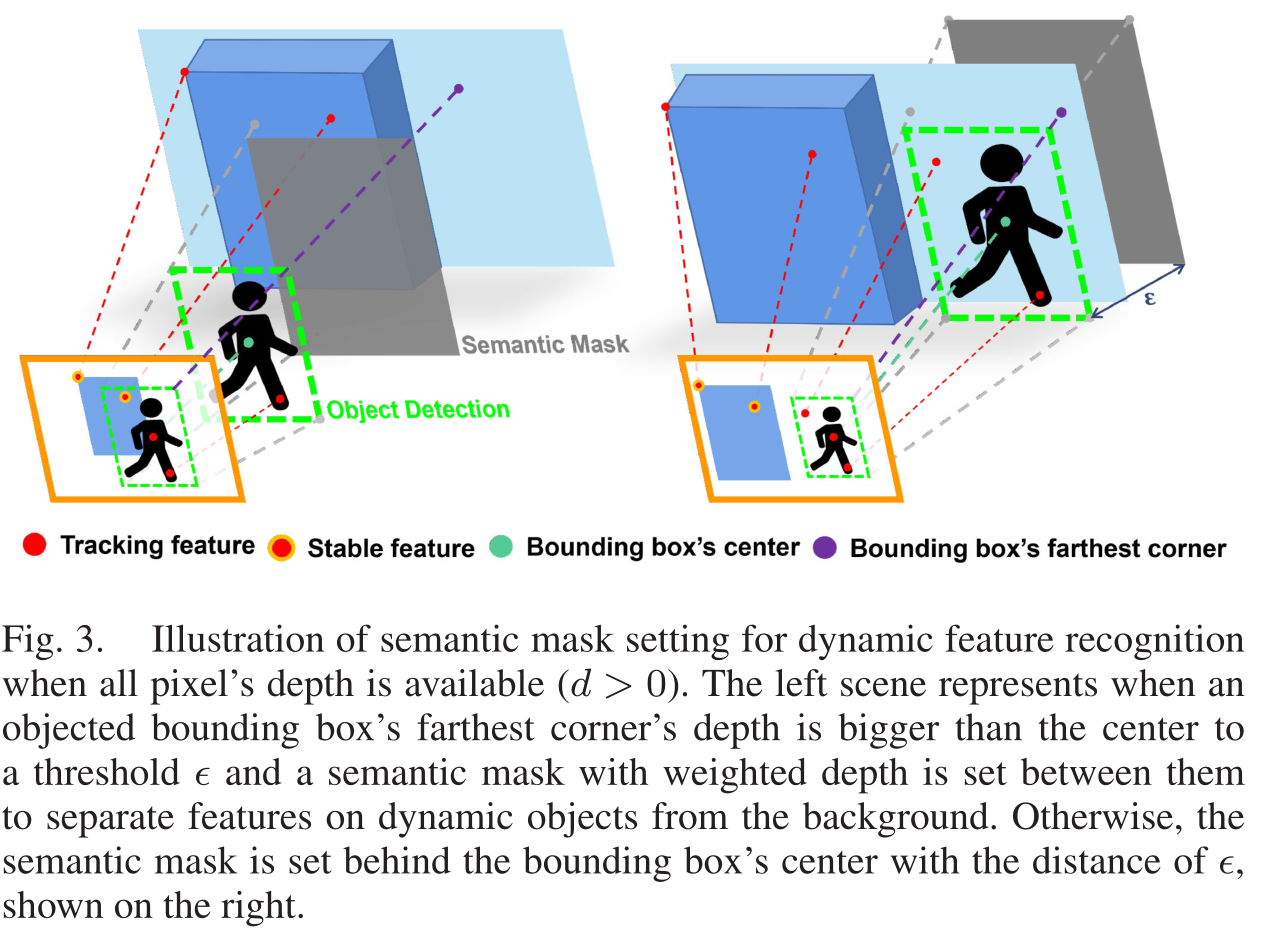 一个像素的深度d>0则是可用的。考虑到大多数动态对象的bounding box角都对应于背景点,且动态对象通常与背景有较大的深度差距。则第k个动态对象的最大背景深度
K
d
m
a
x
=
m
a
x
(
K
d
t
l
+
K
d
t
r
+
K
d
b
l
+
K
d
b
r
)
^{K}d_{max}= max(^{K}d_{tl}+^{K}d_{tr}+^{K}d_{bl}+^{K}d_{br})
Kdmax=max(Kdtl+Kdtr+Kdbl+Kdbr)其中
K
d
t
l
,
K
d
t
r
,
K
d
b
l
,
K
d
b
r
^{K}d_{tl},^{K}d_{tr},^{K}d_{bl},^{K}d_{br}
Kdtl,Kdtr,Kdbl,Kdbr分别是第K个目标检查框的四个角点的深度值。接着,第K个bounding box的深度阈值
K
d
ˉ
^{K}\bar{d}
Kdˉ定义如下
K
d
ˉ
=
{
1
2
(
K
d
m
a
x
+
K
d
c
)
,
if
K
d
m
a
x
−
K
d
c
>
ϵ
,
K
d
c
>
0
,
K
d
c
+
ϵ
if
K
d
m
a
x
−
K
d
c
<
ϵ
,
K
d
c
>
0
,
K
d
m
a
x
if
K
d
m
a
x
>
0
,
K
d
c
=
0
,
+
∞
o
t
h
e
r
w
i
s
e
,
^{K}\bar{d}= \begin{cases} \frac{1}{2}(^{K}d_{max}+^{K}d_{c}) , &\text{if} \quad{} ^{K}d_{max}-^{K}d_{c}>\epsilon,^{K}d_{c}>0,\\ ^{K}d_{c}+\epsilon &\text{if} \quad{} ^{K}d_{max}-^{K}d_{c}<\epsilon,^{K}d_{c}>0 ,\\ ^{K}d_{max} &\text{if} \quad{} ^{K}d_{max}>0,^{K}d_{c}=0 ,\\ +\infin &otherwise, \end{cases}
Kdˉ=⎩
⎨
⎧21(Kdmax+Kdc),Kdc+ϵKdmax+∞ifKdmax−Kdc>ϵ,Kdc>0,ifKdmax−Kdc<ϵ,Kdc>0,ifKdmax>0,Kdc=0,otherwise,
一个像素的深度d>0则是可用的。考虑到大多数动态对象的bounding box角都对应于背景点,且动态对象通常与背景有较大的深度差距。则第k个动态对象的最大背景深度
K
d
m
a
x
=
m
a
x
(
K
d
t
l
+
K
d
t
r
+
K
d
b
l
+
K
d
b
r
)
^{K}d_{max}= max(^{K}d_{tl}+^{K}d_{tr}+^{K}d_{bl}+^{K}d_{br})
Kdmax=max(Kdtl+Kdtr+Kdbl+Kdbr)其中
K
d
t
l
,
K
d
t
r
,
K
d
b
l
,
K
d
b
r
^{K}d_{tl},^{K}d_{tr},^{K}d_{bl},^{K}d_{br}
Kdtl,Kdtr,Kdbl,Kdbr分别是第K个目标检查框的四个角点的深度值。接着,第K个bounding box的深度阈值
K
d
ˉ
^{K}\bar{d}
Kdˉ定义如下
K
d
ˉ
=
{
1
2
(
K
d
m
a
x
+
K
d
c
)
,
if
K
d
m
a
x
−
K
d
c
>
ϵ
,
K
d
c
>
0
,
K
d
c
+
ϵ
if
K
d
m
a
x
−
K
d
c
<
ϵ
,
K
d
c
>
0
,
K
d
m
a
x
if
K
d
m
a
x
>
0
,
K
d
c
=
0
,
+
∞
o
t
h
e
r
w
i
s
e
,
^{K}\bar{d}= \begin{cases} \frac{1}{2}(^{K}d_{max}+^{K}d_{c}) , &\text{if} \quad{} ^{K}d_{max}-^{K}d_{c}>\epsilon,^{K}d_{c}>0,\\ ^{K}d_{c}+\epsilon &\text{if} \quad{} ^{K}d_{max}-^{K}d_{c}<\epsilon,^{K}d_{c}>0 ,\\ ^{K}d_{max} &\text{if} \quad{} ^{K}d_{max}>0,^{K}d_{c}=0 ,\\ +\infin &otherwise, \end{cases}
Kdˉ=⎩
⎨
⎧21(Kdmax+Kdc),Kdc+ϵKdmax+∞ifKdmax−Kdc>ϵ,Kdc>0,ifKdmax−Kdc<ϵ,Kdc>0,ifKdmax>0,Kdc=0,otherwise,
其中
K
d
c
^{K}d_{c}
Kdc是检测框中心点的深度值;
ϵ
>
0
\epsilon>0
ϵ>0是根据场景中场景动态物体大小预先设定的。如果深度不可用,则采用保守策略,选择无限深度作为阈值。
在语义掩码上,第K个动态对象包围框覆盖的区域被设置为加权深度
K
d
ˉ
^{K}\bar{d}
Kdˉ;没有动态对象的区域设置为0。每个传入特征的深度d与语义掩码上对应像素的深度阈值
d
ˉ
\bar{d}
dˉ进行比较。如果
d
<
d
ˉ
d<\bar{d}
d<dˉ,则认为该特征为动态特征。否则,认为该特征为稳定特征。因此,深度值小于加权深度
d
ˉ
\bar{d}
dˉ的区域构成广义语义掩码,如图4和图5(b)所示。

 考虑到动态物体可能长期存在于视场中,因此不同于直接删除动态特征,我们对动态特征进行跟踪而不用于姿态估计。根据其记录的信息,从特征跟踪线程传入的每一个特征点将被判断是否为历史动态特征。上述方法可以避免盲目删除特征点,同时保证效率。它可以节省检测动态对象上特征的时间,对对象检测的漏检具有鲁棒性,并回收假阳性动态特征,如III-E节所述。
考虑到动态物体可能长期存在于视场中,因此不同于直接删除动态特征,我们对动态特征进行跟踪而不用于姿态估计。根据其记录的信息,从特征跟踪线程传入的每一个特征点将被判断是否为历史动态特征。上述方法可以避免盲目删除特征点,同时保证效率。它可以节省检测动态对象上特征的时间,对对象检测的漏检具有鲁棒性,并回收假阳性动态特征,如III-E节所述。
Missed Detection Compensation
由于目标检测有时可能失败,本文提出的Dynamic-VINS利用之前的检测结果来预测接下来的检测结果,以弥补遗漏的检测。假设相邻帧中的动态对象具有一致的运动。一旦动态物体被检测到,它的像素速度和包围框将被更新。设j为当前检测帧,j−1为前一检测帧,定义第k个动态对象帧间像素速度 K v c j ^{K}v^{c_{j}} Kvcj(像素/帧)为 K v c j = K u c c j − K u c c j − 1 ^{K}v^{c_{j}} = ^{K}u^{c_{j}}_{c} - ^{K}u^{c_{j-1}}_{c} Kvcj=Kuccj−Kuccj−1其中 K u c c j , K u c c j − 1 ^{K}u^{c_{j}}_{c},^{K}u^{c_{j-1}}_{c} Kuccj,Kuccj−1分别表示第k个物体检测包围框中心在第j帧和第j−1帧的像素位置。一个加权的预测速度 K v ^ ^{K}\hat{v} Kv^定义为 K v ^ c j + 1 = 1 2 ( K v c j + K v ^ c j ) ^{K}\hat{v}^{c_{j}+1}=\frac{1}{2}(^{K}v^{c_{j}}+^{K}\hat{v}^{c_{j}}) Kv^cj+1=21(Kvcj+Kv^cj)随着更新的进行,越老的帧所拥有的权重预测速度 K v ^ ^{K}\hat{v} Kv^的权重越小。如果在下一帧中未检测到该对象,其对应的包围框 K B o x ^{K}Box KBox包含有四个角的像素位置 K u t l , K u t r , K u b l , K u b r ^{K}u_{tl},^{K}u_{tr},^{K}u_{bl},^{K}u_{br} Kutl,Kutr,Kubl,Kubr,会基于预测速度 K v ^ ^{K}\hat{v} Kv^进行如下更新 K B o x ^ c j + 1 = K B o x c j + K v ^ c j + 1 , ^{K}\hat{Box}^{c_{j}+1}=^{K}Box^{c_j}+^{K}\hat{v}^{c_{j}+1}, KBox^cj+1=KBoxcj+Kv^cj+1,当漏检时间超过阈值时,该动态对象的补偿将被放弃。结果如图4所示。该方法提高了目标检测的召回率,有利于动态特征识别的一致性。
Moving Consistency Check
由于物体检测只能识别人为定义的动态物体,存在漏检问题,状态优化仍然会受到未知移动物体的影响,比如随着人移动的书籍。Dynamic-VINS将IMU预测的位姿与在滑动窗口中优化后的位姿相结合,进行动态特征的识别。
假设第k个特征首先在第i帧图像中观察到,并被其他m帧图像在滑动窗口中观察到。则滑动窗口中特征观测的平均重投影残差
r
k
r_{k}
rk定义为
r
k
=
1
m
∑
j
≠
i
∥
u
k
c
i
−
π
(
T
b
c
T
w
b
i
T
b
j
w
T
c
b
P
k
c
j
)
∥
r_{k}=\frac{1}{m}\sum_{j \neq i}{\left \| u^{c_{i}}_{k}-\pi(T^{c}_{b}T^{b_{i}}_{w}T^{w}_{b_{j}}T^{b}_{c}P^{c_{j}}_{k}) \right \|}
rk=m1j=i∑
ukci−π(TbcTwbiTbjwTcbPkcj)
式中
u
k
c
i
u^{c_{i}}_{k}
ukci为第i帧中对K个特征的观测;
P
k
c
j
P^{c_{j}}_{k}
Pkcj为第k个特征在第j帧中的三维坐标;
T
c
b
T^{b}_{c}
Tcb和
T
b
j
w
T^{w}_{b_{j}}
Tbjw分别是相机坐标到body坐标和第j个body坐标到世界坐标的变换;π代表相机投影模型。当
r
k
r_{k}
rk超过预设阈值时,第k个特征被认为是动态特征。
如图7所示,移动一致性检查(MCC)模块可以发现不稳定特征。然而,一些稳定的特征被错误识别(左上图),站着的人的特征没有被识别(右下图)。阈值越低,不稳定特征的召回率越高。此外,如果重投影误差低于阈值,则具有更多观测值的错误识别的不稳定特征将被回收。

Experimental Results
略


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









