







 本文深入探讨了用户生成内容(UGC)在推荐系统中的作用,介绍了如何利用用户标签行为数据进行推荐。通过统计用户常用标签及物品的热门标签,提出了一种简单的推荐算法。然而,这种方法可能导致热门标签和物品过度曝光,影响个性化推荐。为解决此问题,文章引入TF-IDF概念,通过惩罚热门标签和物品,提高推荐的多样性和新颖性。详细阐述了TF-IDF的计算过程,并给出了Python代码实现。
本文深入探讨了用户生成内容(UGC)在推荐系统中的作用,介绍了如何利用用户标签行为数据进行推荐。通过统计用户常用标签及物品的热门标签,提出了一种简单的推荐算法。然而,这种方法可能导致热门标签和物品过度曝光,影响个性化推荐。为解决此问题,文章引入TF-IDF概念,通过惩罚热门标签和物品,提高推荐的多样性和新颖性。详细阐述了TF-IDF的计算过程,并给出了Python代码实现。
基于 UGC 的推荐
用户用标签来描述对物品的看法,所以用户生成标签(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源
一个用户标签行为的数据集一般由一个三元组(用户,物品,标签)的集合表示,其中一条记录(u,i,b)表示用户 u 给物品 i 打上了标签 b
一个最简单的算法
- 统计每个用户最常用的标签
- 对于每个标签,统计被打过这个标签次数最多的物品
- 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门的物品,推荐给他
- 所以用户 u 对物品 i 的兴趣公式为
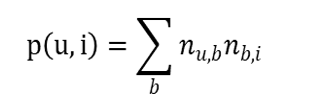

简单算法中直接将用户打出标签的次数和物品得到的标签次数相乘,可以简单地表现出用户对物品某个特征的兴趣
这种方法倾向于给热门标签(谁都会给的标签,如“大片”、“搞笑”等)、热门物品(打标签人数最多)比较大的权重,如果一个热门物品同时对应着热门标签,那它就会“霸榜”,推荐的个性化、新颖度就会降低
TF-IDF

词频(Term Frequency,TF)
指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数的归一化,以防止偏向更长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
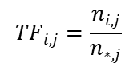
其中 TFi,j 表示词语 i 在文档 j 中出现的频率,ni,j 表示 i 在 j 中出现的次数,n*,j 表示文档 j 的总词数
逆向文件频率(Inverse Document Frequency,IDF)
是一个词语普遍重要性的度量,某一特定词语的 IDF,可以由总文档数目除以包含该词语之文档的数目,再将得到的商取对数得到
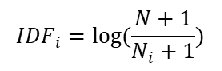
其中 IDFi 表示词语 i 在文档集中的逆文档频率,N 表示文档集中的文档总数,Ni 表示文档集中包含了词语 i 的文档数
TF-IDF 对基于 UGC 推荐的改进
为了避免热门标签和热门物品获得更多的权重,我们需要对“热门”进行惩罚
借鉴 TF-IDF 的思想,以一个物品的所有标签作为“文档”,标签作为“词语”,从而计算标签的“词频”(在物品所有标签中的频率)和“逆文档频率”(在其它物品标签中普遍出现的频率)
由于“物品 i 的所有标签”n*,i 应该对标签权重没有影响,而“所有标签总数”N 对于所有标签是一定的,所以这两项可以略去。在简单算法的基础上,直接加入对热门标签和热门物品的惩罚项:
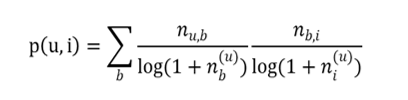

TF-IDF算法代码实现
# TF-IDF算法示例
### 0.引入依赖
import numpy as np
import pandas as pd
### 1.定义数据和预处理
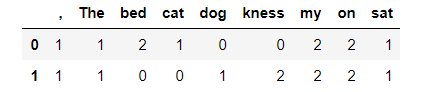
docA = "The cat sat on my bed , on my bed"
docB = "The dog sat on my kness , on my kness"
bowA = docA.split(" ")
bowB = docB.split(" ")
#构建词库
wordSet = set(bowA).union(set(bowB))
### 2.进行词数统计
# 用统计字典来保存词出现的次数
wordDictA = dict.fromkeys( wordSet, 0)
wordDictB = dict.fromkeys( wordSet, 0)
# 遍历文档,统计词数
for word in bowA:
wordDictA[word] += 1
for word in bowB:
wordDictB[word] += 1
pd.DataFrame([wordDictA, wordDictB])
### 3.计算词频TF
def computeTF(wordDict, bow):
# 用一个字典对象记录tf,把所有的词对应在bow文档里的tf都算出来
tfDict = {}
nbowCount = len(bow)
for word, count in wordDict.items():
tfDict[word] = count / nbowCount
return tfDict
tfA = computeTF(wordDictA, bowA)
tfB = computeTF(wordDictB, bowB)
### 4.计算逆文档频率IDF
def computeIDF(wordDictList):
#用一个字典对象保存idf结果,每个词作为key,初始值为0
idfDict = dict.fromkeys(wordDictList[0], 0)
N = len(wordDictList)
import math
for wordDict in wordDictList:
# 遍历字典中的每个词汇,统计Ni
for word, count in wordDict.items():
if count > 0:
# 先把Ni增加1,保存到idfDict
idfDict[word] += 1
# 已经得到所有词汇i对应的Ni,现在根据公式把他替换成idf值
for word,ni in idfDict.items():
idfDict[word] = math.log10( (N+1)/(ni+1) )
return idfDict
idfs = computeIDF([wordDictA, wordDictB])
### 5.计算TF-IDF
def computeTFIDF(tf, idfs):
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
tfidfA = computeTFIDF(tfA, idfs)
tfidfB = computeTFIDF(tfB, idfs)
pd.DataFrame([tfidfA, tfidfB])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









